以下是需要翻译的内容:
这是我的问题:
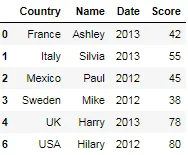
我有一个数据框,长这样:
Date Name Score Country
2012 Paul 45 Mexico
2012 Mike 38 Sweden
2012 Teddy 62 USA
2012 Hilary 80 USA
2013 Ashley 42 France
2013 Temari 58 UK
2013 Harry 78 UK
2013 Silvia 55 Italy
我想选择两个最好的分数,按日期过滤并且来自不同的国家。
例如在这里:2012年,Hilary获得了最高的分数(来自美国),因此她将被选中。 Teddy在2012年获得了第二好的成绩,但他不会被选中,因为他来自同一个国家(美国)。 因此,保罗将被选中,因为他来自另一个国家(墨西哥)。
这是我所做的:
df = pd.DataFrame(
{'Date':["2012","2012","2012","2012","2013","2013","2013","2013"],
'Name': ["Paul", "Mike", "Teddy", "Hilary", "Ashley", "Temaru","Harry","Silvia"],
'Score': [45, 38, 62, 80, 42, 58,78,55],
"Country":["Mexico","Sweden","USA","USA","France","UK",'UK','Italy']})
然后我按照日期和分数制作了筛选器:
df1 = df.set_index('Name').groupby('Date')['Score'].apply(lambda grp: grp.nlargest(2))
但我不是很确定如何筛选出来自不同国家的内容。
有没有人有这方面的想法?非常感谢。
编辑:我需要的答案应该像这样:
Date Name Score Country
2012 Hilary 80 USA
2012 Paul 45 Mexico
2013 Harry 78 UK
2013 Silvia 55 Italy
按日期、最佳得分和不同国家筛选两个人。