我的问题:
我有一个包含ufloats(例如unarray)的数组,使用Python uncertainties包。 数组中的所有值都有自己的误差,我需要一个函数,可以根据平均值的标称值误差和值误差的影响来计算数组的平均值。
我有一个uarray:
2 +/- 1
3 +/- 2
4 +/- 3
我需要一个函数,可以给我这个数组的平均值。
谢谢
我的问题:
我有一个包含ufloats(例如unarray)的数组,使用Python uncertainties包。 数组中的所有值都有自己的误差,我需要一个函数,可以根据平均值的标称值误差和值误差的影响来计算数组的平均值。
我有一个uarray:
2 +/- 1
3 +/- 2
4 +/- 3
我需要一个函数,可以给我这个数组的平均值。
谢谢
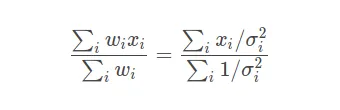 只需要对其进行良好的误差传递,得到带权平均值的不确定度为:
$$ \sqrt{\sum_i \frac{1}{1/\sum_i \sigma_i^2}} $$
只需要对其进行良好的误差传递,得到带权平均值的不确定度为:
$$ \sqrt{\sum_i \frac{1}{1/\sum_i \sigma_i^2}} $$
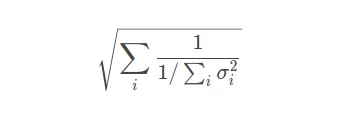 在一个简单的情况下,可以通过以下方式获取加权平均值及其不确定度,但没有n长度的公式来进行语法上的处理:
在一个简单的情况下,可以通过以下方式获取加权平均值及其不确定度,但没有n长度的公式来进行语法上的处理: a = un.ufloat(5, 2)
b = un.ufloat(8, 4)
wavg = un.ufloat((a.n/a.s**2 + b.n/b.s**2)/(1/a.s**2 + 1/b.s**2),
np.sqrt(2/(1/a.s**2 + 1/b.s**2)))
print(wavg)
>>> 5.6+/-2.5298221281347035
除非我漏掉了什么,你可以计算sum除以数组的长度:
from uncertainties import unumpy, ufloat
import numpy as np
arr = np.array([ufloat(2, 1), ufloat(3, 2), ufloat(4,3)])
print(sum(arr)/len(arr))
# 3.0+/-1.2
你也可以这样定义:
arr1 = unumpy.uarray([2, 3, 4], [1, 2, 3])
print(sum(arr1)/len(arr1))
# 3.0+/-1.2
uncertainties会处理其余部分。我使用了Captain Morgan的答案来为一个项目提供一些甜美的Python代码,发现它需要一点额外的成分:
import uncertainties as un
from un.unumpy import unp
epsilon = unp.nominal_values(values).mean()/(1e12)
wavg = ufloat(sum([v.n/(v.s**2+epsilon) for v in values])/sum([1/(v.s**2+epsilon) for v in values]),
np.sqrt(len(values)/sum([1/(v.s**2+epsilon) for v in values])))
if wavg.s <= np.sqrt(epsilon):
wavg = ufloat(wavg.n, 0.0)
如果没有那个微小的东西(epsilon),我们在记录了零不确定性的观测中会出现除以零的错误。
from uncertainties import ufloat_fromstr
df=pd.read_csv('Z:\compare\SL2P_PAR.csv')
for i in range(len(df.uncertainty)):
df['mean'] = ufloat_fromstr(df['uncertainty'][I]).n
df['sted'] = ufloat_fromstr(df['uncertainty'][I]).s