当MATLAB字符编码为UTF-8时,通常是Linux用户的情况下(因此Amro使用CP1252配置没有问题),会出现问题。当MATLAB字符集编码(使用
slCharacterEncoding()获取)为UTF-8时,MATLAB eps导出函数存在错误(至少在R2011b之前),因为它以八进制转义的UTF-8格式(2字节)导出非ASCII字符,而Postscript解释器设定为解码1字节格式。
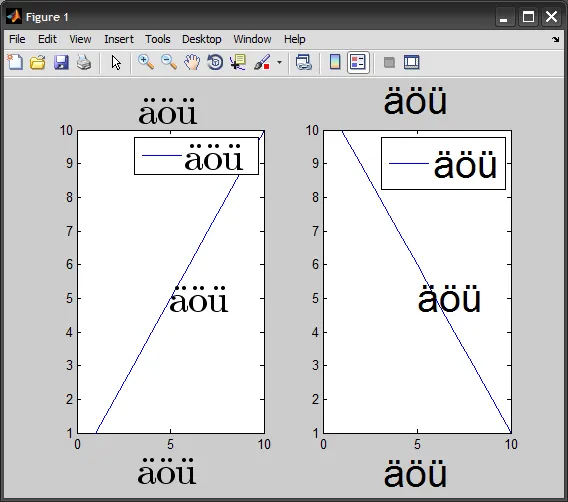
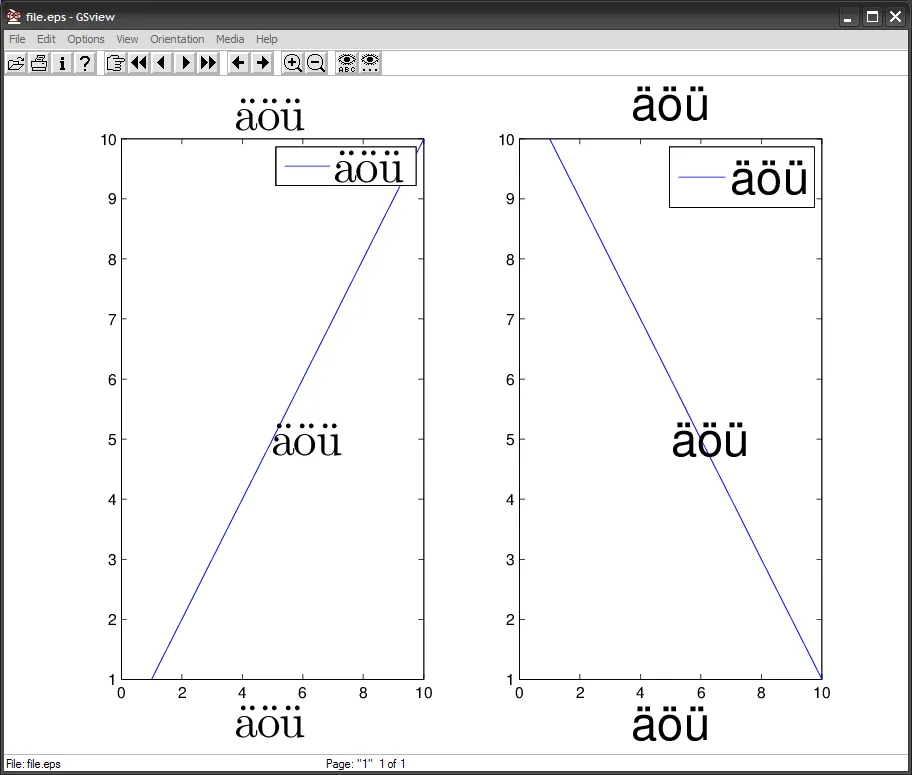
让我们用字符ö U+00F6来说明这个错误,它的一些表示形式如下:
- UTF-16: 0x00F6
- UTF-8: 0xC3 0xB6
- C octal escaped UTF-8: \303\266
- XML decimal entity: ö
MATLAB创建的eps文件包含:
/Helvetica /ISOLatin1Encoding 120 FMSR
(\303\266) s
MATLAB在eps文件中定义了一个名为
FMSR的函数,该函数将Helvetica字体重新编码为另一种编码方式,即
ISOLatin1Encoding。这是两个内置编码向量之一,与ISO-8859-1(Latin1)标准非常接近(有关更多详细信息,请参见Postscript语言参考手册的第329-330页)。简而言之,编码向量是256元素数组,将字符名称与字符代码相关联。因此,它只读取1字节字符代码。在ISO-8859-1中,\303=195=à 和 \266=182=¶。因此,它打印出了ö。
导出非ASCII ISO-8859-1字符的选项与UTF-8本地环境。
Convert the octal UTF-8 codes into octal ISO-8859-1 codes, which is easy because non-ASCII ISO-8859-1 characters follow the same layout in UTF-8. For example, with the program sed, which can be run from the Command window or from your export script:
!sed -i -e 's/\\302\(\\2[4-7][0-7]\)/\1/g' -e 's/\\303\\2\([0-7][0-7]\)/\\3\1/g' file.eps
Thus, \303\266 becomes \366=246=ö. You can directly type the non-ASCII characters in MATLAB.
Change the MATLAB character set encoding slCharacterEncoding('ISO-8859-1') before adding text to the figure and, if you add text from the Command window, use char(number) for non-ASCII characters. If you add text directly in the figure with the plot tools, you can enter the non-ASCII characters. This solution is not ideal because the non-ASCII characters do not appear on the figure in the default font (Helvetica by default with MATLAB on Linux) and it requires to use char(number) if you script the creation of the figure.
Render the text later with LaTex by using a user-submitted MATLAB function such as LaPrint or one of its forks, which creates a tex-file with the text of the figure and an eps-file with the non-text part of the figure. A similar solution is matlab2tikz which creates a tikz/pgfplot file and a tex file.
Use the Latex interpreter of MATLAB: \"{o}. MATLAB creates the character by combining the ASCII character with its diacritic but the result is low quality because of bad relative positioning (the diacritic is a bit too much on the right compared to the character). MATLAB uses the glyphs from Computer Modern font and embeds the font in the eps file (which adds ~ 80 Ko). Furthermore, the raw text in the pdf created from the eps does not contain ö but o ̈.
导出非ISO-8859-1字符
对于需要导出不在ISO-8859-1中的字符(如这里所提问的),如果所需字符数小于256(8位格式),最好使用标准编码集。以下是解决方案:
- 将八进制代码转换为Unicode字符;
- 将文件保存到目标编码标准中(以8位格式);
- 添加目标编码集的编码向量。
例如,如果您想要导出波兰文本,则需要将文件转换为ISO-8859-2。以下是Linux Bash实现的示例:
#!/bin/bash
name=$(basename "$1" .eps)
ascii2uni -a K "$1" > /tmp/eps_uni.eps
iconv -t ISO-8859-2 /tmp/eps_uni.eps -o "$name"_latin2.eps
sed -i -e '/%EndPageSetup/ r ISOLatin2Encoding.ps' -e 's/ISOLatin1Encoding/MyEncoding/' "$name"_latin2.eps
将文件保存为eps_lat2; 然后运行命令 sh eps_lat2 file.eps 会创建一个使用Latin-2编码的file_latin2.eps文件。文件ISOLatin2Encoding.ps包含以下内容:
/MyEncoding
% The first 144 entries are the same as the ISO Latin-1 encoding.
ISOLatin1Encoding 0 144 getinterval aload pop
% \22x
/.notdef /.notdef /.notdef /.notdef /.notdef /.notdef /.notdef /.notdef
/.notdef /.notdef /.notdef /.notdef /.notdef /.notdef /.notdef /.notdef
% \24x
/nbspace /Aogonek /breve /Lslash /currency /Lcaron /Sacute /section
/dieresis /Scaron /Scedilla /Tcaron /Zacute /hyphen /Zcaron /Zdotaccent
/degree /aogonek /ogonek /lslash /acute /lcaron /sacute /caron
/cedilla /scaron /scedilla /tcaron /zacute /hungarumlaut /zcaron /zdotaccent
% \30x
/Racute /Aacute /Acircumflex /Abreve /Adieresis /Lacute /Cacute /Ccedilla
/Ccaron /Eacute /Eogonek /Edieresis /Ecaron /Iacute /Icircumflex /Dcaron
/Dcroat /Nacute /Ncaron /Oacute /Ocircumflex /Ohungarumlaut /Odieresis /multiply
/Rcaron /Uring /Uacute /Uhungarumlaut /Udieresis /Yacute /Tcedilla /germandbls
% \34x
/racute /aacute /acircumflex /abreve /adieresis /lacute /cacute /ccedilla
/ccaron /eacute /eogonek /edieresis /ecaron /iacute /icircumflex /dcaron
/dcroat /nacute /ncaron /oacute /ocircumflex /ohungarumlaut /odieresis /divide
/rcaron /uring /uacute /uhungarumlaut /udieresis /yacute /tcedilla /dotaccent
256 packedarray def
以下是使用Python的另一种实现方式(因此它也可以在Windows和Mac上运行):
import sys,codecs
input = sys.argv[1]
fo = codecs.open(input[:-4]+'_latin2.eps','w','latin2')
with codecs.open(input,'r','string_escape') as fi:
data = fi.readlines()
with open('ISOLatin2Encoding.ps') as fenc:
for line in data:
fo.write(line.decode('utf-8').replace('ISOLatin1Encoding','MyEncoding'))
if line.startswith('%%EndPageSetup'):
fo.write(fenc.read())
fo.close()
将文件保存为eps_lat2.py; 然后运行命令python eps_lat2.py file.eps,将创建一个使用Latin-2编码的file_latin2.eps文件。
该脚本可以轻松地适应其他8位编码标准,只需更改编码向量和脚本中的iconv(或codecs.open)参数即可。
{kind=link}
slCharacterEncoding函数是Simulink的一部分。我更喜欢使用feature('DefaultCharacterSet','xxx')来获取/设置字符集,这是核心MATLAB的一部分(尽管它没有文档记录)。 - Amro