我有一个包含多个工作表的Excel工作簿。 我正在尝试使用Pandas read_excel()迭代地从每个工作表读取DataFrame,以便为每个工作表输出单独的csv文件。
def getSheets(inputfile, fileformat):
'''Split the sheets in the workbook into seperate CSV files in to folder
in the directory. CSV's are named identical to the original sheet names'''
name = getName(inputfile) # get name
try:
os.makedirs(name)
except:
pass
# read as df
df1 = pd.ExcelFile(inputfile)
# for each sheet create new file
for x in df1.sheet_names:
y = x.lower().replace("-", "_").replace(" ","_")
print(x + '.' + fileformat, 'Done!')
df2 = pd.read_excel(inputfile, sheet_name=x) #looking for way to dynamically find where the table begins
filename = os.path.join(name, y + '.' + fileformat)
if fileformat == 'csv':
df2.to_csv(filename, index=False)
else:
df2.to_excel(filename, index=False)
我遇到的问题是Excel工作簿有很多格式。结果是每个表格在每个工作表上都从不同的行开始。以下是工作簿中一个工作表的示例:示例表格 在这里,表格从第10行开始。在同一工作簿的其他工作表中,该表格从第8行开始等等。有50多个工作表,表格的第一行在各处不同。
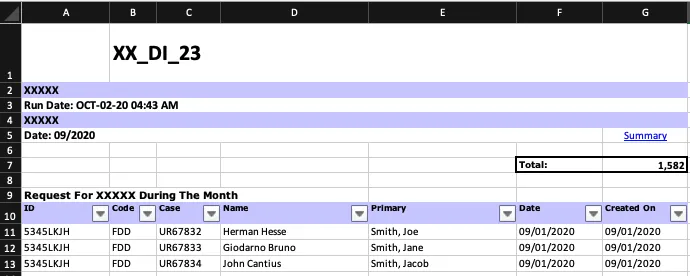{kind=link}
我已经了解了使用“skiprows”参数读取特定行的方法。但是该参数的值在迭代每个工作表时会发生变化。有没有一种使用Pandas读取表格的方法,即使每个表格都从可变行开始,或者有没有一种方法可以确定表格实际开始的位置?