我该如何在PyTorch中保存已训练的模型? 我已经阅读到:
torch.save()/torch.load()用于保存/加载可序列化对象。model.state_dict()/model.load_state_dict()用于保存/加载模型状态。
我该如何在PyTorch中保存已训练的模型? 我已经阅读到:
torch.save()/torch.load() 用于保存/加载可序列化对象。model.state_dict()/model.load_state_dict() 用于保存/加载模型状态。在他们的 Github 存储库中找到了 this page:
Recommended approach for saving a model
There are two main approaches for serializing and restoring a model.
The first (recommended) saves and loads only the model parameters:
torch.save(the_model.state_dict(), PATH)Then later:
the_model = TheModelClass(*args, **kwargs) the_model.load_state_dict(torch.load(PATH))The second saves and loads the entire model:
torch.save(the_model, PATH)Then later:
the_model = torch.load(PATH)However in this case, the serialized data is bound to the specific classes and the exact directory structure used, so it can break in various ways when used in other projects, or after some serious refactors.
这要看你想做什么。
情况1:保存模型以便自己使用进行推断:您保存模型,恢复它,然后将模型更改为评估模式。这是因为通常在构建时默认处于训练模式的 BatchNorm 和 Dropout 层:
torch.save(model.state_dict(), filepath)
#Later to restore:
model.load_state_dict(torch.load(filepath))
model.eval()
案例#2:保存模型以便稍后继续训练:如果您需要保留即将保存的模型的训练状态,您需要保存的不仅仅是模型本身。您还需要保存优化器、纪元、分数等状态。您可以像这样完成:
state = {
'epoch': epoch,
'state_dict': model.state_dict(),
'optimizer': optimizer.state_dict(),
...
}
torch.save(state, filepath)
要恢复训练,您需要执行以下操作:state = torch.load(filepath),然后针对每个单独对象恢复其状态,像这样:
model.load_state_dict(state['state_dict'])
optimizer.load_state_dict(state['optimizer'])
由于您正在恢复训练,请勿在加载状态后调用 model.eval()。
方案#3:供他人使用且无法访问您的代码的模型:
在Tensorflow中,您可以创建一个 .pb 文件,定义模型的架构和权重。这非常方便,特别是在使用 Tensorflow serve 时。在Pytorch中执行相应操作的方式如下:
torch.save(model, filepath)
# Then later:
model = torch.load(filepath)
这种方式仍然不是百分之百可靠的,而且由于PyTorch仍在经历许多变化,我不建议使用。
torch.load仅返回一个有序字典。如何获取模型以进行预测? - Alber8295Python的pickle库实现了二进制协议来序列化和反序列化Python对象。
当你使用import torch(或者使用PyTorch)时,它会为你导入pickle,你不需要直接调用pickle.dump()和pickle.load()方法进行对象的保存和加载。
事实上,torch.save()和torch.load()将为您包装pickle.dump()和pickle.load()。
另一个答案提到的state_dict值得更多的说明。
在PyTorch中有哪些state_dict?实际上有两个state_dict。
PyTorch模型是torch.nn.Module,其具有model.parameters()调用以获取可学习参数(w和b)。这些可学习参数一旦随机设置,将随着时间的推移而更新。可学习参数是第一个state_dict。
第二个state_dict是优化器状态字典。您可能还记得,优化器用于改进我们的可学习参数。但是优化器的state_dict是固定的。没有什么可学习的。
因为state_dict对象是Python字典,所以它们可以轻松保存、更新、修改和恢复,为PyTorch模型和优化器增加了很大的模块性。
让我们创建一个超级简单的模型来解释这个问题:
import torch
import torch.optim as optim
model = torch.nn.Linear(5, 2)
# Initialize optimizer
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
print("Model's state_dict:")
for param_tensor in model.state_dict():
print(param_tensor, "\t", model.state_dict()[param_tensor].size())
print("Model weight:")
print(model.weight)
print("Model bias:")
print(model.bias)
print("---")
print("Optimizer's state_dict:")
for var_name in optimizer.state_dict():
print(var_name, "\t", optimizer.state_dict()[var_name])
这段代码将会输出以下结果:
Model's state_dict:
weight torch.Size([2, 5])
bias torch.Size([2])
Model weight:
Parameter containing:
tensor([[ 0.1328, 0.1360, 0.1553, -0.1838, -0.0316],
[ 0.0479, 0.1760, 0.1712, 0.2244, 0.1408]], requires_grad=True)
Model bias:
Parameter containing:
tensor([ 0.4112, -0.0733], requires_grad=True)
---
Optimizer's state_dict:
state {}
param_groups [{'lr': 0.001, 'momentum': 0.9, 'dampening': 0, 'weight_decay': 0, 'nesterov': False, 'params': [140695321443856, 140695321443928]}]
请注意,这只是一个最简模型。您可以尝试添加连续的堆栈。
model = torch.nn.Sequential(
torch.nn.Linear(D_in, H),
torch.nn.Conv2d(A, B, C)
torch.nn.Linear(H, D_out),
)
请注意,只有具有可学习参数(如卷积层、线性层等)和已注册缓冲区(批归一化层)的层才在模型的 state_dict 中有条目。
不可学习的内容属于优化器对象 state_dict,其中包含有关优化器状态以及使用的超参数的信息。
剩下的故事是相同的;在推理阶段(这是我们在训练后使用模型的阶段)进行预测时,我们是基于所学参数进行预测的。因此,在推理时,我们只需要保存参数 model.state_dict()。
torch.save(model.state_dict(), filepath)
并在之后使用:
model.load_state_dict(torch.load(filepath))
model.eval()
注意: 不要忘记最后一行model.eval(),这在加载模型后非常重要。
另外,请不要尝试保存torch.save(model.parameters(), filepath)。 model.parameters()只是生成器对象。
另一方面,torch.save(model, filepath)保存模型对象本身,但请记住,该模型没有优化器的state_dict。请查看@Jadiel de Armas的其他优秀答案以保存优化器的state dict。
model.load_state_dict中,model是什么?如果我要将其导出到另一个环境,导出和导入模型的代码示例是什么?我正在训练一个Bert模型,不确定要使用哪个类来加载这些参数。 - undefined一个常见的 PyTorch 约定是使用 .pt 或 .pth 文件扩展名保存模型。
保存/加载整个模型
保存:
path = "username/directory/lstmmodelgpu.pth"
torch.save(trainer, path)
加载:
(模型类必须在某处定义)
model.load_state_dict(torch.load(PATH))
model.eval()
state = {
'epoch': epoch,
'state_dict': model.state_dict(),
'optimizer': optimizer.state_dict(),
}
savepath='checkpoint.t7'
torch.save(state,savepath)
加载:
checkpoint = torch.load('checkpoint.t7')
model.load_state_dict(checkpoint['state_dict'])
optimizer.load_state_dict(checkpoint['optimizer'])
epoch = checkpoint['epoch']
多个GPU:保存
state = {
'epoch': epoch,
'state_dict': model.module.state_dict(),
'optimizer': optimizer.state_dict(),
}
savepath='checkpoint.t7'
torch.save(state,savepath)
加载:
checkpoint = torch.load('checkpoint.t7')
model.load_state_dict(checkpoint['state_dict'])
optimizer.load_state_dict(checkpoint['optimizer'])
epoch = checkpoint['epoch']
#Don't call DataParallel before loading the model otherwise you will get an error
model = nn.DataParallel(model) #ignore the line if you want to load on Single GPU
你如何保存模型取决于你将来如何访问它。如果你可以调用 model 类的一个新实例,那么你只需要使用 model.state_dict() 来保存/加载模型的权重即可:
# Save:
torch.save(old_model.state_dict(), PATH)
# Load:
new_model = TheModelClass(*args, **kwargs)
new_model.load_state_dict(torch.load(PATH))
torch.save()保存整个模型(实际上是对定义模型的文件(s)及其state_dict的引用)。# Save:
torch.save(old_model, PATH)
# Load:
new_model = torch.load(PATH)
但由于这是对定义模型类文件位置的引用,除非这些文件也在相同的目录结构中移植,否则此代码不可移植。
如果您希望使您的模型具有可移植性,可以轻松地使用 torch.hub 允许其被导入。如果您向 github 存储库添加一个适当定义的 hubconf.py 文件,则可以轻松从 PyTorch 中调用它,以使用户能够加载/不加载权重来加载您的模型:
hubconf.py (github.com/repo_owner/repo_name)
dependencies = ['torch']
from my_module import mymodel as _mymodel
def mymodel(pretrained=False, **kwargs):
return _mymodel(pretrained=pretrained, **kwargs)
正在加载模型:
new_model = torch.hub.load('repo_owner/repo_name', 'mymodel')
new_model_pretrained = torch.hub.load('repo_owner/repo_name', 'mymodel', pretrained=True)
安装 pytorch-lightning,请使用 pip install pytorch-lightning 命令。
确保您的父模型使用 pl.LightningModule 而不是 nn.Module。
使用 pytorch lightning 保存和加载检查点。
import pytorch_lightning as pl
model = MyLightningModule(hparams)
trainer.fit(model)
trainer.save_checkpoint("example.ckpt")
new_model = MyModel.load_from_checkpoint(checkpoint_path="example.ckpt")
我使用这种方法,希望对你有用。
num_labels = len(test_label_cols)
robertaclassificationtrain = '/dbfs/FileStore/tables/PM/TC/roberta_model'
robertaclassificationpath = "/dbfs/FileStore/tables/PM/TC/ROBERTACLASSIFICATION"
model = RobertaForSequenceClassification.from_pretrained(robertaclassificationpath,
num_labels=num_labels)
model.cuda()
model.load_state_dict(torch.load(robertaclassificationtrain))
model.eval()
我已将训练模型保存在“roberta_model”路径中。保存一个训练模型。
torch.save(model.state_dict(), '/dbfs/FileStore/tables/PM/TC/roberta_model')
以TorchScript格式导出/加载模型是保存模型的另一种方式。
使用训练好的模型进行推理的另一种常见方法是使用TorchScript,这是PyTorch模型的中间表示形式,可以在Python和C++中运行。
注意:使用TorchScript格式,您将能够加载导出的模型并进行推理,而无需定义模型类。
class TheModelClass(nn.Module):
def __init__(self):
super(TheModelClass, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# Initialize model
model = TheModelClass()
导出:
model_scripted = torch.jit.script(model) # Export to TorchScript
model_scripted.save('model_scripted.pt') # Save
加载【不需定义模型类】:
model = torch.jit.load('model_scripted.pt')
model.eval()
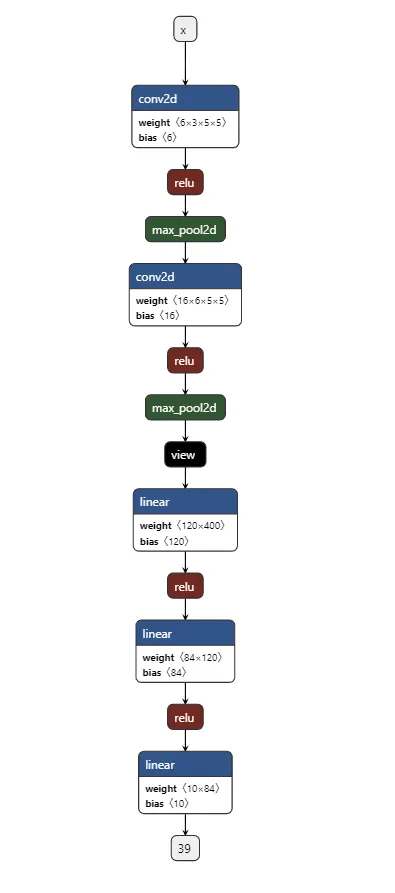
**Model arch in Netron looks like this**
现在所有的东西都写在官方教程里了: https://pytorch.org/tutorials/beginner/saving_loading_models.html
你有几个选项可以选择如何保存和保存什么,所有内容都在那个教程中解释。
torch.save(model, f)和torch.save(model.state_dict(), f)。保存下来的文件大小相同,这让我感到困惑。同时,我发现使用pickle保存model.state_dict()速度极慢。我认为最好的方法是使用torch.save(model.state_dict(), f),因为你负责模型的创建,而torch负责加载模型权重,从而消除可能存在的问题。 参考链接:https://discuss.pytorch.org/t/saving-torch-models/838/4 - Dawei Yang