我有一个数据框,其中包含一个字符串列。它看起来像这样:
我想要的是添加6个列,将[a]的值分割开来,就像这样:
我使用这段代码:
但是我遇到了“超出范围”的错误,这可以解释为所有值的元素数量不相同。
我该如何避免这个错误,并将所有出错的值替换为None?
提前感谢。
编辑:我们无法预先知道要拆分的字符串长度。有时它包含2个出现次数,有时包含4个等等。
[a]
aaa aa a aaaa
bbb bbb b
cc cccc ccc cc ccc
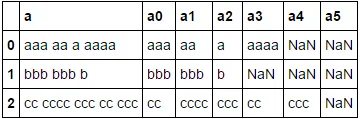
我想要的是添加6个列,将[a]的值分割开来,就像这样:
[a] [a0] [a1] [a2] [a3] [a4] [a5]
aaa aa a aaaa aaa aa a aaaa NaN NaN
bbb bbb b bbb bbb b NaN NaN NaN
cc cccc ccc cc ccc cc cccc ccc cc ccc NaN
我使用这段代码:
for i in range(6):
df["a{}".format(i)] = df[a].apply(lambda x:x.split(' ')[i])
但是我遇到了“超出范围”的错误,这可以解释为所有值的元素数量不相同。
我该如何避免这个错误,并将所有出错的值替换为None?
提前感谢。
编辑:我们无法预先知道要拆分的字符串长度。有时它包含2个出现次数,有时包含4个等等。