我希望以连续的方式对数据框中的金融数据执行自己的复杂操作。
例如,我正在使用从Yahoo Finance获取的以下 MSFT CSV 文件:
Date,Open,High,Low,Close,Volume,Adj Close
2011-10-19,27.37,27.47,27.01,27.13,42880000,27.13
2011-10-18,26.94,27.40,26.80,27.31,52487900,27.31
2011-10-17,27.11,27.42,26.85,26.98,39433400,26.98
2011-10-14,27.31,27.50,27.02,27.27,50947700,27.27
....
接下来我会执行以下步骤:
#!/usr/bin/env python
from pandas import *
df = read_csv('table.csv')
for i, row in enumerate(df.values):
date = df.index[i]
open, high, low, close, adjclose = row
#now perform analysis on open/close based on date, etc..
那是最有效的方式吗?鉴于pandas对速度的关注,我认为一定有一些特殊的函数可以以一种同时检索索引的方式迭代值(可能通过生成器进行内存效率)?df.iteritems不幸的是只能逐列迭代。
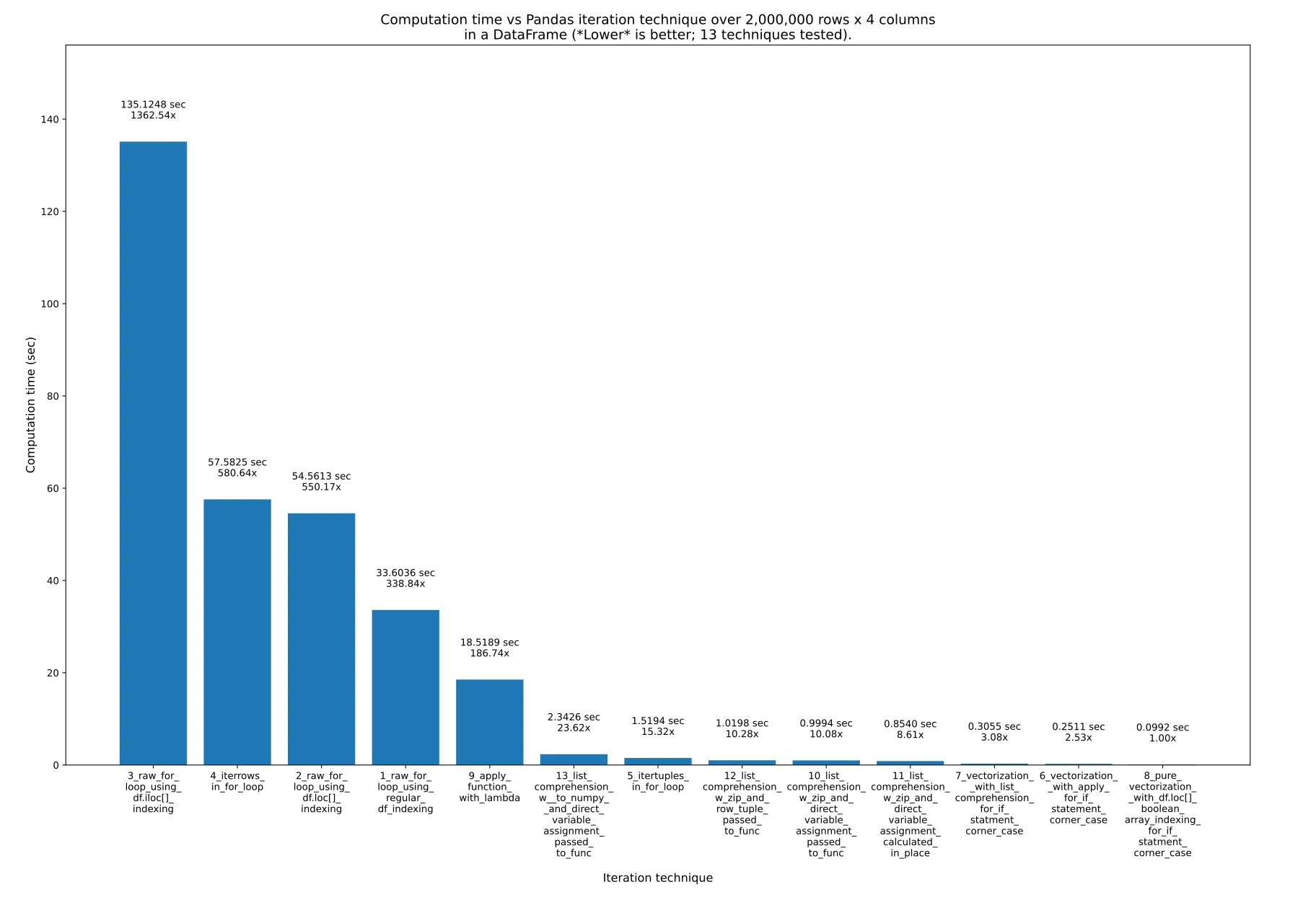
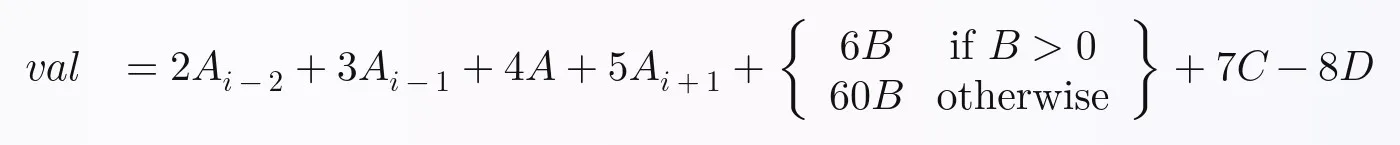
df.apply()吗? - naught101iterrows(),这比最快的技术慢600倍,或者使用itertuples(),这比最快的技术慢15倍。因此,请考虑将接受的答案移动到我的答案,我在其中介绍了1倍和其他技术,并对它们进行了详细的速度测试。 - undefined