我有一个包含4列字符串和其他整数的数据框。现在我需要找出那些至少一列是非零值(或>0)的数据行。
manwra,sahAyaH,T7,0,0,0,0,T
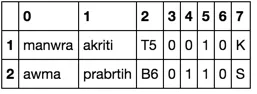
manwra, akriti,T5,0,0,1,0,K
awma, prabrtih,B6, 0,1,1,0,S
我的输出应该是:
manwra, akriti,T5,0,0,1,0,K
awma, prabrtih,B6, 0,1,1,0,S
我尝试了以下方法来获取答案。字符串的值在第0列、第1列、第2列和最后一列(-1列)中。
KT[KT.ix[:,3:-2] != 0]
我接收到的输出是:
NaN,NaNNaN,NaN,NaN,NaN,NaN,NaN
NaN,NaN,NaN,NaN,NaN,1,NaN,NaN
NaN,NaN,NaN,NaN,1,1,NaN,NaN
如何获得所需的输出结果。