这个问题是此问题的延续。
我的目标是找到股票价格数据中的拐点。
到目前为止,我已经尝试使用Dr. Andrew Burnett-Thompson的中心五点法对平滑后的价格集进行微分,如此处所述。
我使用EMA20的tick数据对数据集进行平滑处理。
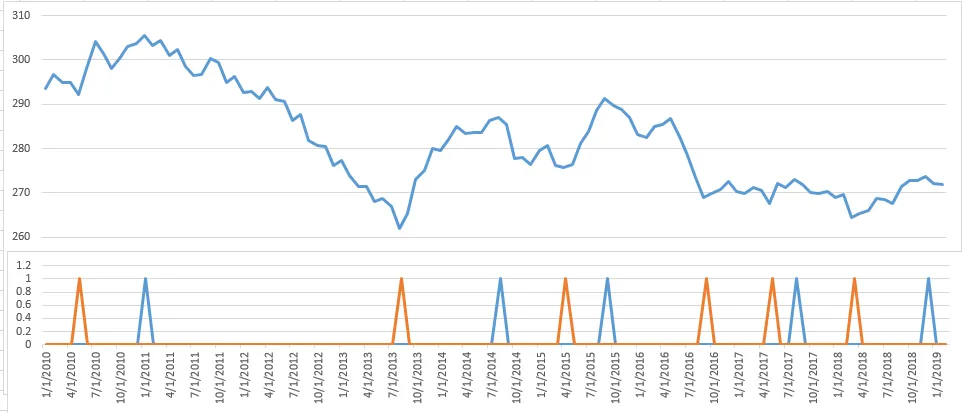
对于图表上的每个点,我获得了1阶导数(dy/dx)。我为拐点创建了第二个图表。每当dy/dx在[-一些小值]和[+一些小值]之间时,我就向该图表添加一个点。
问题在于: 我没有得到真正的拐点,只是得到了接近的结果。 我得到的点太多或太少——取决于[某个小值]
我尝试了第二种方法,即当dy/dx从负变为正时添加一个点,但由于我使用的是tick数据的EMA(而不是1分钟收盘价的EMA),所以可能会创建太多的点。
第三种方法是将数据集分成n个点的片段,并找到最小点和最大点。这种方法效果很好(不完美),但有滞后。
有没有更好的方法?
我附上了两张输出图片(1阶导数和n个点的最小/最大值)。
我的目标是找到股票价格数据中的拐点。
到目前为止,我已经尝试使用Dr. Andrew Burnett-Thompson的中心五点法对平滑后的价格集进行微分,如此处所述。
我使用EMA20的tick数据对数据集进行平滑处理。
对于图表上的每个点,我获得了1阶导数(dy/dx)。我为拐点创建了第二个图表。每当dy/dx在[-一些小值]和[+一些小值]之间时,我就向该图表添加一个点。
问题在于: 我没有得到真正的拐点,只是得到了接近的结果。 我得到的点太多或太少——取决于[某个小值]
我尝试了第二种方法,即当dy/dx从负变为正时添加一个点,但由于我使用的是tick数据的EMA(而不是1分钟收盘价的EMA),所以可能会创建太多的点。
第三种方法是将数据集分成n个点的片段,并找到最小点和最大点。这种方法效果很好(不完美),但有滞后。
有没有更好的方法?
我附上了两张输出图片(1阶导数和n个点的最小/最大值)。