我正在尝试使用pandas执行合并操作。这两个文件有一个共同的关键字(“KEY_PLA”),我正在尝试使用左连接。但不幸的是,从第二个文件传输到第一个文件的所有列都具有NaN值。
以下是我迄今为止所做的事情:
这是结果: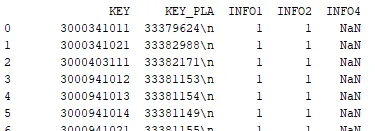 这里是Excel文件:
Excel1
Excel2
代码有什么问题?我也检查了类型,甚至将列转换为字符串。但是什么都不起作用。
这里是Excel文件:
Excel1
Excel2
代码有什么问题?我也检查了类型,甚至将列转换为字符串。但是什么都不起作用。
以下是我迄今为止所做的事情:
df_1 = pd.read_excel(path1, skiprows=1)
df_2 = pd.read_excel(path2, skiprows=1)
df_1.columns = ["Index", "KEY", "KEY_PLA", "INFO1", "INFO2"]
df_2.columns = ["Index", "KEY_PLA", "INFO4"]
df_1.drop(["Index"], axis=1, inplace=True)
df_2.drop(["Index"], axis=1, inplace=True)
# Merge all dataframes
df_merge = pd.DataFrame()
df_merge = df_1.merge(df_2, left_on="KEY_PLA", right_on="KEY_PLA", how="left")
print(df_merge)
这是结果:
这里是Excel文件:
Excel1
Excel2
代码有什么问题?我也检查了类型,甚至将列转换为字符串。但是什么都不起作用。
df_1.head().to_dict('list')和df_2.head().to_dict('list'),这样我们就不必下载几百MB的数据来查看问题了。 - unutbu