编辑:新库
存在一个更新的库,可以通过以下命令安装:
pip install finance-byu
文档在这里:https://fin-library.readthedocs.io/en/latest/
新库包括 Fama Macbeth 回归实现和 Regtable 类,可用于报告结果。
此页面的文档概述了 Fama Macbeth 函数:https://fin-library.readthedocs.io/en/latest/fama_macbeth.html
有一个实现与 Karl D. 上面的实现非常相似,使用了 numpy 的线性代数函数,一个利用 joblib 进行并行化以增加数据中大量时间段时的性能,以及一个使用 numba 进行优化的实现,可以在小数据集上节省一个数量级。
以下是一个类似于文档中的小模拟数据集的示例:
>>> from finance_byu.fama_macbeth import fama_macbeth, fama_macbeth_parallel, fm_summary, fama_macbeth_numba
>>> import pandas as pd
>>> import time
>>> import numpy as np
>>>
>>> n_jobs = 5
>>> n_firms = 1.0e2
>>> n_periods = 1.0e2
>>>
>>> def firm(fid):
>>> f = np.random.random((int(n_periods),4))
>>> f = pd.DataFrame(f)
>>> f['period'] = f.index
>>> f['firmid'] = fid
>>> return f
>>> df = [firm(i) for i in range(int(n_firms))]
>>> df = pd.concat(df).rename(columns={0:'ret',1:'exmkt',2:'smb',3:'hml'})
>>> df.head()
ret exmkt smb hml period firmid
0 0.766593 0.002390 0.496230 0.992345 0 0
1 0.346250 0.509880 0.083644 0.732374 1 0
2 0.787731 0.204211 0.705075 0.313182 2 0
3 0.904969 0.338722 0.437298 0.669285 3 0
4 0.121908 0.827623 0.319610 0.455530 4 0
>>> result = fama_macbeth(df,'period','ret',['exmkt','smb','hml'],intercept=True)
>>> result.head()
intercept exmkt smb hml
period
0 0.655784 -0.160938 -0.109336 0.028015
1 0.455177 0.033941 0.085344 0.013814
2 0.410705 -0.084130 0.218568 0.016897
3 0.410537 0.010719 0.208912 0.001029
4 0.439061 0.046104 -0.084381 0.199775
>>> fm_summary(result)
mean std_error tstat
intercept 0.506834 0.008793 57.643021
exmkt 0.004750 0.009828 0.483269
smb -0.012702 0.010842 -1.171530
hml 0.004276 0.010530 0.406119
>>>
123 ms ± 117 µs per loop (mean ± std. dev. of 7 runs, 10 loops each
>>>
146 ms ± 16.9 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
>>>
5.04 ms ± 5.2 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
注意:关闭memmap可实现公平比较,无需在每次运行时生成新数据。使用memmap时,并行实现将仅提取缓存的结果。
这里有几个使用模拟数据的表类简单实现:
>>> from finance_byu.regtables import Regtable
>>> import pandas as pd
>>> import statsmodels.formula.api as smf
>>> import numpy as np
>>>
>>>
>>> nobs = 1000
>>> df = pd.DataFrame(np.random.random((nobs,3))).rename(columns={0:'age',1:'bmi',2:'hincome'})
>>> df['age'] = df['age']*100
>>> df['bmi'] = df['bmi']*30
>>> df['hincome'] = df['hincome']*100000
>>> df['hincome'] = pd.qcut(df['hincome'],16,labels=False)
>>> df['rich'] = df['hincome'] > 13
>>> df['gender'] = np.random.choice(['M','F'],nobs)
>>> df['race'] = np.random.choice(['W','B','H','O'],nobs)
>>>
>>> regformulas = ['bmi ~ age',
>>> 'bmi ~ np.log(age)',
>>> 'bmi ~ C(gender) + np.log(age)',
>>> 'bmi ~ C(gender) + C(race) + np.log(age)',
>>> 'bmi ~ C(gender) + rich + C(gender)*rich + C(race) + np.log(age)',
>>> 'bmi ~ -1 + np.log(age)',
>>> 'bmi ~ -1 + C(race) + np.log(age)']
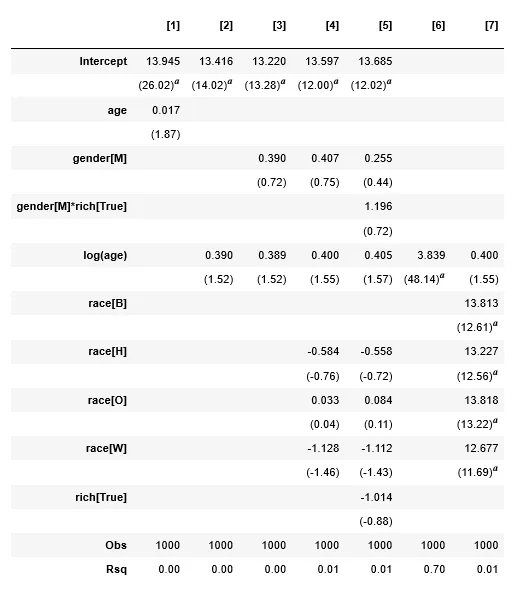
>>> reg = [smf.ols(f,df).fit() for f in regformulas]
>>> tbl = Regtable(reg)
>>> tbl.render()
产生以下结果:
>>> df2 = pd.DataFrame(np.random.random((nobs,10)))
>>> df2.columns = ['t0_vw','t4_vw','et_vw','t0_ew','t4_ew','et_ew','mktrf','smb','hml','umd']
>>> regformulas2 = ['t0_vw ~ mktrf',
>>> 't0_vw ~ mktrf + smb + hml',
>>> 't0_vw ~ mktrf + smb + hml + umd',
>>> 't4_vw ~ mktrf',
>>> 't4_vw ~ mktrf + smb + hml',
>>> 't4_vw ~ mktrf + smb + hml + umd',
>>> 'et_vw ~ mktrf',
>>> 'et_vw ~ mktrf + smb + hml',
>>> 'et_vw ~ mktrf + smb + hml + umd',
>>> 't0_ew ~ mktrf',
>>> 't0_ew ~ mktrf + smb + hml',
>>> 't0_ew ~ mktrf + smb + hml + umd',
>>> 't4_ew ~ mktrf',
>>> 't4_ew ~ mktrf + smb + hml',
>>> 't4_ew ~ mktrf + smb + hml + umd',
>>> 'et_ew ~ mktrf',
>>> 'et_ew ~ mktrf + smb + hml',
>>> 'et_ew ~ mktrf + smb + hml + umd'
>>> ]
>>> regnames = ['Small VW','','',
>>> 'Large VW','','',
>>> 'Spread VW','','',
>>> 'Small EW','','',
>>> 'Large EW','','',
>>> 'Spread EW','',''
>>> ]
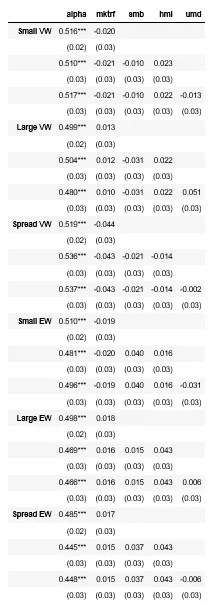
>>> reg2 = [smf.ols(f,df2).fit() for f in regformulas2]
>>>
>>> tbl2 = Regtable(reg2,orientation='horizontal',regnames=regnames,sig='coeff',intercept_name='alpha',nobs=False,rsq=False,stat='se')
>>> tbl2.render()
产生以下结果:
Regtable类的文档在此处:https://byu-finance-library-finance-byu.readthedocs.io/en/latest/regtables.html
这些表格可以导出为LaTeX格式,方便写作中的使用:
tbl.to_latex()
summary_col函数,但它缺少一些选项(和花里胡哨的功能)https://github.com/statsmodels/statsmodels/issues/1637 - Josef