我正在尝试使用CUDA内核修改OpenGL纹理,但是遇到了奇怪的问题,我的
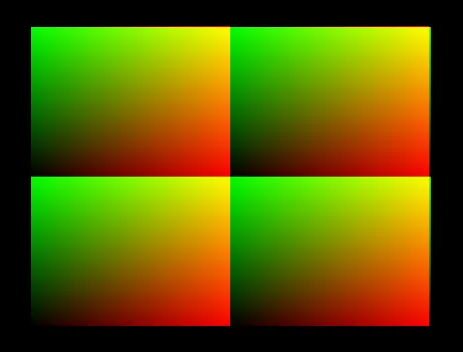
surf2Dwrite()调用似乎与纹理的先前内容混合,如下图所示。背景中的木纹纹理是在使用CUDA内核修改之前的纹理。预期输出应仅包括颜色渐变,而不是其后面的木纹纹理。我不明白为什么会发生这种混合。

可能的问题/误解
我对CUDA和OpenGL都很陌生。在这里,我尝试解释导致我编写此代码的思考过程:
- 我使用
cudaArray来访问纹理(而不是例如浮点数组),因为我读到说这样做在读/写纹理时更好地利用缓存一些。 - 我使用surface,因为我在某个地方读到这是修改
cudaArray的唯一方法 - 我想使用surface对象,我理解这是新的处理方式。旧的方式是使用surface references。
一些可能存在的问题,我不知道如何检查/测试:
- 我的图像格式是否不一致?也许我没有在某个地方指定正确的每通道位数?也许我应该使用
float而不是unsigned char?
代码摘要
您可以在GitHub Gist中找到一个完整的最小工作示例。由于涉及多个部分,代码比较长,但我会尝试概括一下。欢迎提出缩短MWE的建议。总体结构如下:- 从本地文件创建OpenGL纹理
- 使用
cudaGraphicsGLRegisterImage()将纹理注册到CUDA - 调用
cudaGraphicsSubResourceGetMappedArray()获取表示纹理的cudaArray - 创建
cudaSurfaceObject_t以用于向cudaArray写入数据 - 将表面对象传递给写入纹理的内核函数
surf2Dwrite() - 使用纹理在屏幕上绘制矩形
创建OpenGL纹理
我对OpenGL还很陌生,所以我使用LearnOpenGL教程中的“纹理”部分作为起点。以下是我如何设置纹理(使用图像库stb_image.h)
GLuint initTexturesGL(){
// load texture from file
int numChannels;
unsigned char *data = stbi_load("img/container.jpg", &g_imageWidth, &g_imageHeight, &numChannels, 4);
if(!data){
std::cerr << "Error: Failed to load texture image!" << std::endl;
exit(1);
}
// opengl texture
GLuint textureId;
glGenTextures(1, &textureId);
glBindTexture(GL_TEXTURE_2D, textureId);
// wrapping
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_MIRRORED_REPEAT);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_MIRRORED_REPEAT);
// filtering
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR_MIPMAP_LINEAR);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
// set texture image
glTexImage2D(
GL_TEXTURE_2D, // target
0, // mipmap level
GL_RGBA8, // internal format (#channels, #bits/channel, ...)
g_imageWidth, // width
g_imageHeight, // height
0, // border (must be zero)
GL_RGBA, // format of input image
GL_UNSIGNED_BYTE, // type
data // data
);
glGenerateMipmap(GL_TEXTURE_2D);
// unbind and free image
glBindTexture(GL_TEXTURE_2D, 0);
stbi_image_free(data);
return textureId;
}
CUDA图形交互
在调用上述函数后,我使用CUDA注册纹理:
void initTexturesCuda(GLuint textureId){
// register texture
HANDLE(cudaGraphicsGLRegisterImage(
&g_textureResource, // resource
textureId, // image
GL_TEXTURE_2D, // target
cudaGraphicsRegisterFlagsSurfaceLoadStore // flags
));
// resource description for surface
memset(&g_resourceDesc, 0, sizeof(g_resourceDesc));
g_resourceDesc.resType = cudaResourceTypeArray;
}
渲染循环
每一帧,我都会运行以下代码来修改纹理并渲染图像:
while(!glfwWindowShouldClose(window)){
// -- CUDA --
// map
HANDLE(cudaGraphicsMapResources(1, &g_textureResource));
HANDLE(cudaGraphicsSubResourceGetMappedArray(
&g_textureArray, // array through which to access subresource
g_textureResource, // mapped resource to access
0, // array index
0 // mipLevel
));
// create surface object (compute >= 3.0)
g_resourceDesc.res.array.array = g_textureArray;
HANDLE(cudaCreateSurfaceObject(&g_surfaceObj, &g_resourceDesc));
// run kernel
kernel<<<gridDim, blockDim>>>(g_surfaceObj, g_imageWidth, g_imageHeight);
// unmap
HANDLE(cudaGraphicsUnmapResources(1, &g_textureResource));
// --- OpenGL ---
// clear
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
// use program
shader.use();
// triangle
glBindVertexArray(vao);
glBindTexture(GL_TEXTURE_2D, textureId);
glDrawElements(GL_TRIANGLES, 6, GL_UNSIGNED_INT, 0);
glBindVertexArray(0);
// glfw: swap buffers and poll i/o events
glfwSwapBuffers(window);
glfwPollEvents();
}
CUDA内核
实际的CUDA内核如下:
__global__ void kernel(cudaSurfaceObject_t surface, int nx, int ny){
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
if(x < nx && y < ny){
uchar4 data = make_uchar4(x % 255,
y % 255,
0, 255);
surf2Dwrite(data, surface, x * sizeof(uchar4), y);
}
}
glTexParameteri将参数应用于当前绑定的图像,因此必须在执行glGenTextures和glBindTexture之前完成。 - Rabbid76