如何在整数列表中找到重复项并创建另一个包含这些重复项的列表?
如何在列表中找到重复项并创建另一个包含它们的列表?
697
- MFB
3
2可能是重复的问题:如何在保留顺序的情况下从Python列表中删除重复项? - DhruvPathak
3你希望重复出现的内容只保留一次,还是每次看到都要重复? - moooeeeep
我认为这个问题已经得到了更高效的回答。https://dev59.com/wnRB5IYBdhLWcg3wXmRI#642919 intersection是一个集合的内置方法,应该可以完全满足需求。 - Tom Smith
44个回答
9
我会使用pandas来完成这个任务,因为我经常使用它。
import pandas as pd
a = [1,2,3,3,3,4,5,6,6,7]
vc = pd.Series(a).value_counts()
vc[vc > 1].index.tolist()
提供
[3,6]
也许这种方法不太高效,但比其他答案的代码要少得多,所以我认为贡献一下也无妨。
- firelynx
1
6请注意,pandas中包含一个内置的重复函数。
pda = pd.Series(a)
print list(pda[pda.duplicated()]) - Len Blokken8
如何简单地循环遍历列表中的每个元素,通过检查出现次数,将它们添加到一个集合中,然后打印出重复项。希望这能帮助到某些人。
myList = [2 ,4 , 6, 8, 4, 6, 12];
newList = set()
for i in myList:
if myList.count(i) >= 2:
newList.add(i)
print(list(newList))
## [4 , 6]
- HenryDev
7
不需要转换为列表,可能最简单的方法如下所示。在面试中,当他们要求不使用集合时,这可能很有用。
a=[1,2,3,3,3]
dup=[]
for each in a:
if each not in dup:
dup.append(each)
print(dup)
======= 否则将获得2个独特值列表和重复值列表
a=[1,2,3,3,3]
uniques=[]
dups=[]
for each in a:
if each not in uniques:
uniques.append(each)
else:
dups.append(each)
print("Unique values are below:")
print(uniques)
print("Duplicate values are below:")
print(dups)
- Chetan_Vasudevan
1
3这并不会生成 a(或原始列表)的重复项列表,而是生成包含a(或原始列表)所有不同元素的列表。完成形成“dup”列表后,某人会怎么做? - gameCoder95
7
我们可以使用
输出结果如下:
itertools.groupby 来查找所有具有重复项的项目:from itertools import groupby
myList = [2, 4, 6, 8, 4, 6, 12]
# when the list is sorted, groupby groups by consecutive elements which are similar
for x, y in groupby(sorted(myList)):
# list(y) returns all the occurences of item x
if len(list(y)) > 1:
print x
输出结果如下:
4
6
- Nir Alfasi
1
2更简洁地说:
dupes = [x for x, y in groupby(sorted(myList)) if len(list(y)) > 1] - frnhr7
尽管其时间复杂度为O(n log n),但从以下基准测试结果来看,它似乎有一定的竞争力。
a = sorted(a)
dupes = list(set(a[::2]) & set(a[1::2]))
排序将重复值放在一起,所以它们既在偶数索引处也在奇数索引处。唯一值只在偶数或奇数索引处出现,而不是两者都出现。因此,偶数索引值和奇数索引值的交集就是重复值。
基准测试结果:
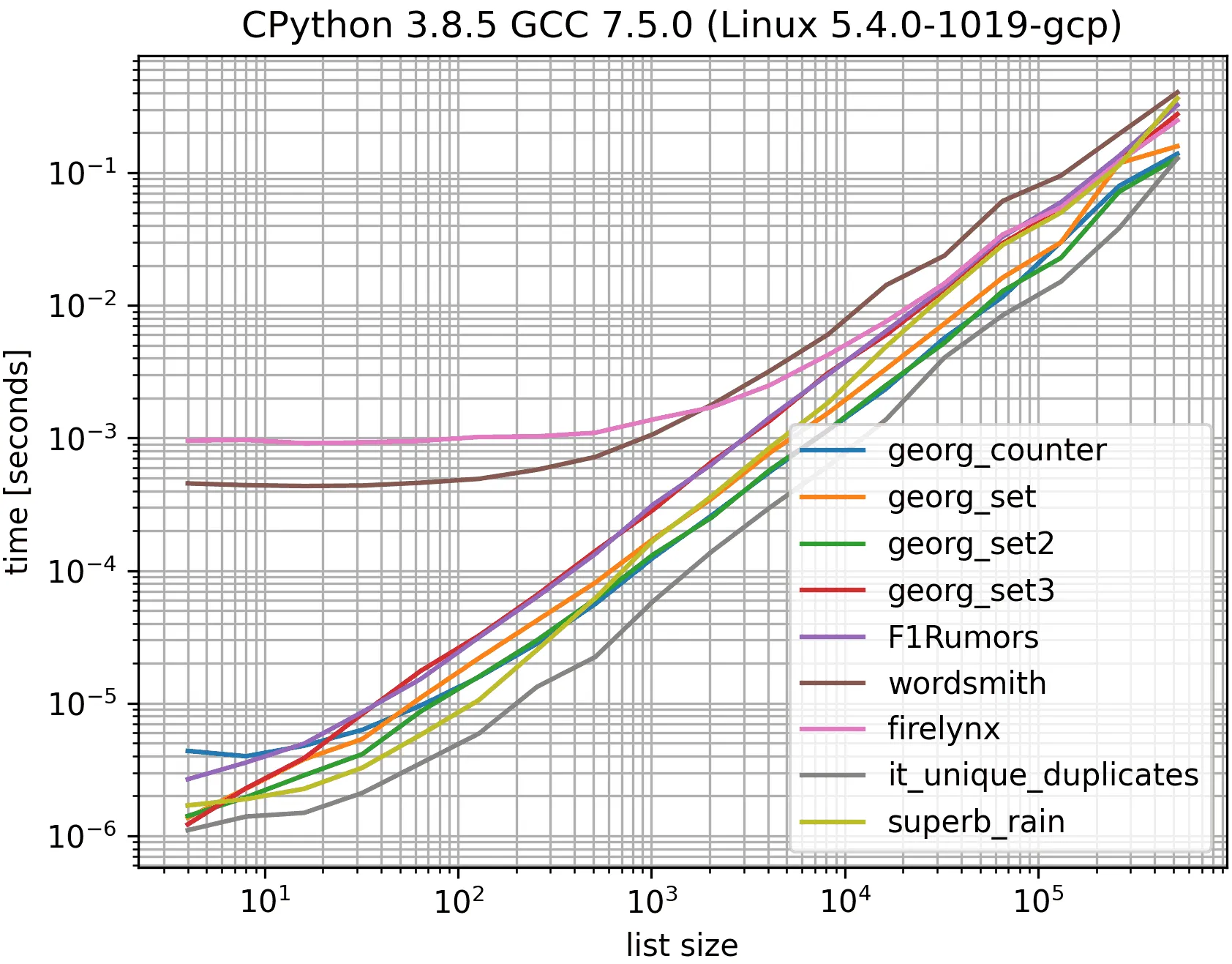
这使用了MSeifert的基准测试,但仅使用被接受答案的解决方案(georgs),最慢的解决方案,最快的解决方案(排除it_duplicates,因为它不会去重重复值),以及我的解决方案。否则太拥挤,颜色太相似。
如果我们可以修改给定的列表,那么第一行可以使用a.sort(),这样会更快一些。但是基准测试多次重用同一列表,所以修改它会影响基准测试。
显然,set(a[::2]).intersection(a[1::2])不会创建第二个集合,并且会更快一些,但是稍微有点长。
- superb rain
3
1这是考虑到复杂性后最佳的解决方案。谢谢! - anujonthemove
简单而高效,这绝对是一个明显的胜利者! - 16807
简单而高效,这绝对是一个明显的胜利者! - undefined
6
被接受回答的第三个例子给出了错误的答案,并未尝试给出重复项。这里是正确的版本:
number_lst = [1, 1, 2, 3, 5, ...]
seen_set = set()
duplicate_set = set(x for x in number_lst if x in seen_set or seen_set.add(x))
unique_set = seen_set - duplicate_set
- yota
5
有点晚,但可能对一些人有帮助。
对于较大的列表,我发现这对我很有用。
仅显示所有重复项并保留顺序。
l=[1,2,3,5,4,1,3,1]
s=set(l)
d=[]
for x in l:
if x in s:
s.remove(x)
else:
d.append(x)
d
[1,3,1]
仅显示所有重复项并保留顺序。
- user3109122
4
使用Python一次迭代查找重复项的非常简单且快速的方法是:
testList = ['red', 'blue', 'red', 'green', 'blue', 'blue']
testListDict = {}
for item in testList:
try:
testListDict[item] += 1
except:
testListDict[item] = 1
print testListDict
输出结果如下:
>>> print testListDict
{'blue': 3, 'green': 1, 'red': 2}
这是我的博客,里面有更多相关的IT技术内容:http://www.howtoprogramwithpython.com
- Igor Vishnevskiy
1
这是桶排序的一种变体。 - ingyhere
4
我很晚才加入这个讨论。尽管如此,我想用一行代码解决这个问题。因为这是Python的魅力。 如果我们只想将重复项放入一个单独的列表(或任何集合)中,我建议按以下方式操作。假设我们有一个重复的列表,可以称之为“目标”
``` duplicates = list(set([x for x in target if target.count(x) > 1])) ``` target=[1,2,3,4,4,4,3,5,6,8,4,3]
如果我们想要获取重复的内容,可以使用以下一句话代码:
duplicates=dict(set((x,target.count(x)) for x in filter(lambda rec : target.count(rec)>1,target)))
这段代码将重复的记录作为键,计数作为值存入字典“duplicates”中。“duplicates”字典的样式如下:
{3: 3, 4: 4} #it saying 3 is repeated 3 times and 4 is 4 times
如果您只想要一个包含重复记录的列表,那么代码会更加简短:
duplicates=filter(lambda rec : target.count(rec)>1,target)
输出结果将会是:
[3, 4, 4, 4, 3, 4, 3]
这在 Python 2.7.x 及以上版本中完美运行。
- akhil pathirippilly
3
方法一:
list(set([val for idx, val in enumerate(input_list) if val in input_list[idx+1:]]))
示例: input_list = [42,31,42,31,3,31,31,5,6,6,6,6,6,7,42]
从列表中的第一个元素42开始,其索引为0,它检查元素42是否存在于input_list [1:](即从索引1到列表末尾)中。 因为42存在于input_list [1:]中,它将返回42。
然后它转到下一个元素31,其索引为1,并检查元素31是否存在于input_list [2:](即从索引2到列表末尾)中, 因为31存在于input_list [2:]中,它将返回31。
类似地,它遍历列表中的所有元素,并仅将重复/重复的元素返回到列表中。
然后,因为我们有重复项,所以需要从重复项中选择一个,即删除重复项。为此,我们调用名为set()的Python内置函数,它会删除重复项。
然后我们剩下一个集合,但不是列表,因此要从集合转换为列表,我们使用类型转换list(),它将元素的集合转换为列表。
方法2:
def dupes(ilist):
temp_list = [] # initially, empty temporary list
dupe_list = [] # initially, empty duplicate list
for each in ilist:
if each in temp_list: # Found a Duplicate element
if not each in dupe_list: # Avoid duplicate elements in dupe_list
dupe_list.append(each) # Add duplicate element to dupe_list
else:
temp_list.append(each) # Add a new (non-duplicate) to temp_list
return dupe_list
解释: 我们创建了两个空列表来开始。 然后遍历整个列表中的所有元素,查看它是否存在于temp_list(最初为空)。如果不在temp_list中,则使用append方法将其添加到temp_list中。
如果已经存在于temp_list中,则说明当前列表元素是重复的,因此我们需要使用append方法将其添加到dupe_list中。
- Sundeep471
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接