我是一名有用的助手,可以为您进行文本翻译。
我有一个大型数据框,由许多周期组成,每个周期内有2个最大峰值需要捕获到另一个数据框中。
我创建了一个示例数据框,模拟了我看到的数据:
正如您在每个周期中所看到的那样,有两个峰值,但我遇到的问题是第二个峰值通常比第一个峰值更高,因此可能会有一行数字在技术上比循环中其他峰值的最大值更高。结果应该看起来像这样:
我已经尝试了几种方法,包括每个周期使用 .nlargest(2),但问题是由于其中一个峰值通常更高,它会提取数据中第二高的数字,这不一定是另一个峰值。此图显示我想要找到的每个周期的峰值压力。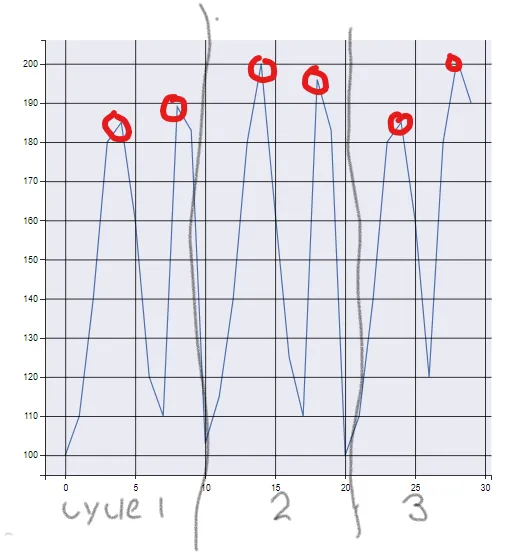 。谢谢任何帮助。
。谢谢任何帮助。
我有一个大型数据框,由许多周期组成,每个周期内有2个最大峰值需要捕获到另一个数据框中。
我创建了一个示例数据框,模拟了我看到的数据:
import pandas as pd
data = {'Cycle':[1,1,1,1,1,1,1,1,1,1,2,2,2,2,2,2,2,2,2,2,3,3,3,3,3,3,3,3,3,3], 'Pressure':[100,110,140,180,185,160,120,110,189,183,103,115,140,180,200,162,125,110,196,183,100,110,140,180,185,160,120,180,201,190]}
df = pd.DataFrame(data)
正如您在每个周期中所看到的那样,有两个峰值,但我遇到的问题是第二个峰值通常比第一个峰值更高,因此可能会有一行数字在技术上比循环中其他峰值的最大值更高。结果应该看起来像这样:
data2 = {'Cycle':[1,1,2,2,3,3], 'Peak Maxs': [185,189,200,196,185,201]}
df2= pd.DataFrame(data2)
我已经尝试了几种方法,包括每个周期使用 .nlargest(2),但问题是由于其中一个峰值通常更高,它会提取数据中第二高的数字,这不一定是另一个峰值。此图显示我想要找到的每个周期的峰值压力。
。谢谢任何帮助。
signal。我一直在尝试使用find_peaks,但是scipy.signal.find_peaks总是让我失望... - Quang Hoangdf.groupby('Cycle')['Pressure'].apply(lambda x : x.iloc[find_peaks(x.values)[0]])- BENY