我有一组数据,其中我记录了每组三个读数的值(以便能够获得SEM的概括性想法)。我将它们记录在一个列表中,看起来像下面这样,我正在尝试将其折叠为每组三个点的平均值:
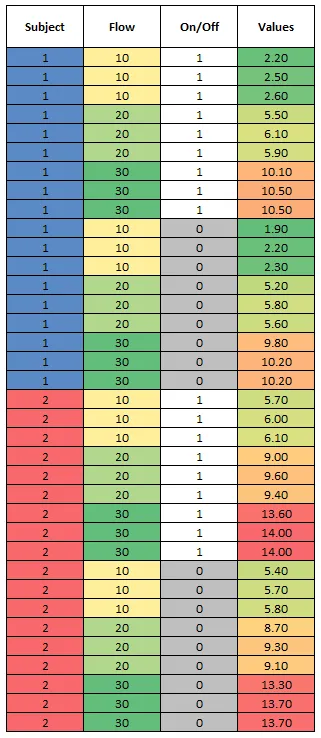
我希望将每3行数据折叠成一行,并提供该组的平均数据值。实际上,它看起来应该像这样:
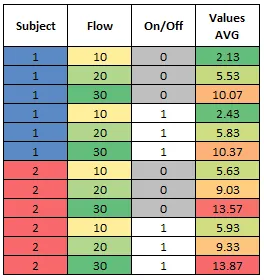
我基本上知道如何在Excel中完成这个任务(即使用数据透视表),但我不确定如何在MATLAB中完成相同的任务。我尝试使用accumarray,但是在实际操作中很难将多个条件整合起来。我需要创建一个subs数组,其中每个数字对应于每组唯一的3个数据点。通过暴力方法,我可以创建这样一个数组:
subs = [1 1 1; 2 2 2; 3 3 3; 4 4 4; ...]'
我希望你能使用一些循环并将其作为我的subs数组,但由于它与数据本身没有关联,并且可能会出现奇怪的问题(即每组超过3个数据点或缺少数据等),所以需要某种方式来进行类似于透视表的分组。但需要一些帮助才能启动它。谢谢。
以下是文本形式的输入数据:
Subject Flow On/Off Values
1 10 1 2.20
1 10 1 2.50
1 10 1 2.60
1 20 1 5.50
1 20 1 6.10
1 20 1 5.90
1 30 1 10.10
1 30 1 10.50
1 30 1 10.50
1 10 0 1.90
1 10 0 2.20
1 10 0 2.30
1 20 0 5.20
1 20 0 5.80
1 20 0 5.60
1 30 0 9.80
1 30 0 10.20
1 30 0 10.20
2 10 1 5.70
2 10 1 6.00
2 10 1 6.10
2 20 1 9.00
2 20 1 9.60
2 20 1 9.40
2 30 1 13.60
2 30 1 14.00
2 30 1 14.00
2 10 0 5.40
2 10 0 5.70
2 10 0 5.80
2 20 0 8.70
2 20 0 9.30
2 20 0 9.10
2 30 0 13.30
2 30 0 13.70
2 30 0 13.70
2.13的结果的呢?那里平均了哪些数字? - Luis Mendo