我有一个包含3万条记录的数据框,格式如下:
ID | Name | Latitude | Longitude | Country |
1 | Hull | 53.744 | -0.3456 | GB |
我希望选择一条记录作为起点,另一条记录作为终点,并返回最短路径的路径(列表)。
我正在使用Geopy查找点之间的距离(以千米为单位)。
import geopy.distance
coords_1 = (52.2296756, 21.0122287)
coords_2 = (52.406374, 16.9251681)
print (geopy.distance.vincenty(coords_1, coords_2).km)
我已经阅读了以下教程,学习了如何在Python中使用A*算法: https://www.redblobgames.com/pathfinding/a-star/implementation.html
然而,他们创建了一个网格系统来进行导航。
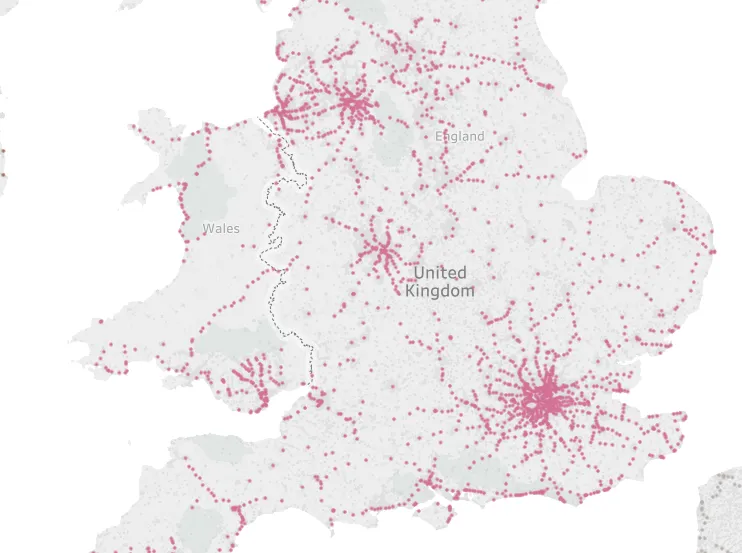
这是数据框中记录的可视化表示:
这是我目前的代码,但它无法找到路径:
def calcH(start, end):
coords_1 = (df['latitude'][start], df['longitude'][start])
coords_2 = (df['latitude'][end], df['longitude'][end])
distance = (geopy.distance.vincenty(coords_1, coords_2)).km
return distance
^计算点之间的距离
def getneighbors(startlocation):
neighborDF = pd.DataFrame(columns=['ID', 'Distance'])
coords_1 = (df['latitude'][startlocation], df['longitude'][startlocation])
for index, row in df.iterrows():
coords_2 = (df['latitude'][index], df['longitude'][index])
distance = round((geopy.distance.vincenty(coords_1, coords_2)).km,2)
neighborDF.loc[len(neighborDF)] = [index, distance]
neighborDF = neighborDF.sort_values(by=['Distance'])
neighborDF = neighborDF.reset_index(drop=True)
return neighborDF[1:5]
^返回4个最接近的位置(不包括自身)
openlist = pd.DataFrame(columns=['ID', 'F', 'G', 'H', 'parentID'])
closedlist = pd.DataFrame(columns=['ID', 'F', 'G', 'H', 'parentID'])
startIndex = 25479 # Hessle
endIndex = 8262 # Leeds
h = calcH(startIndex, endIndex)
openlist.loc[len(openlist)] = [startIndex,h, 0, h, startIndex]
while True:
#sort the open list by F score
openlist = openlist.sort_values(by=['F'])
openlist = openlist.reset_index(drop=True)
currentLocation = openlist.loc[0]
closedlist.loc[len(closedlist)] = currentLocation
openlist = openlist[openlist.ID != currentLocation.ID]
if currentLocation.ID == endIndex:
print("Complete")
break
adjacentLocations = getneighbors(currentLocation.ID)
if(len(adjacentLocations) < 1):
print("No Neighbors: " + str(currentLocation.ID))
else:
print(str(len(adjacentLocations)))
for index, row in adjacentLocations.iterrows():
if adjacentLocations['ID'][index] in closedlist.values:
continue
if (adjacentLocations['ID'][index] in openlist.values) == False:
g = currentLocation.G + calcH(currentLocation.ID, adjacentLocations['ID'][index])
h = calcH(adjacentLocations['ID'][index], endIndex)
f = g + h
openlist.loc[len(openlist)] = [adjacentLocations['ID'][index], f, g, h, currentLocation.ID]
else:
adjacentLocationInDF = openlist.loc[openlist['ID'] == adjacentLocations['ID'][index]] #Get location from openlist
g = currentLocation.G + calcH(currentLocation.ID, adjacentLocations['ID'][index])
f = g + adjacentLocationInDF.H
if float(f) < float(adjacentLocationInDF.F):
openlist = openlist[openlist.ID != currentLocation.ID]
openlist.loc[len(openlist)] = [adjacentLocations['ID'][index], f, g, adjacentLocationInDF.H, currentLocation.ID]
if (len(openlist)< 1):
print("No Path")
break
从关闭列表中找到路径:
# return the path
pathdf = pd.DataFrame(columns=['name', 'latitude', 'longitude', 'country'])
def getParent(index):
parentDF = closedlist.loc[closedlist['ID'] == index]
pathdf.loc[len(pathdf)] = [df['name'][parentDF.ID.values[0]],df['latitude'][parentDF.ID.values[0]],df['longitude'][parentDF.ID.values[0]],df['country'][parentDF.ID.values[0]]]
if index != startIndex:
getParent(parentDF.parentID.values[0])
getParent(closedlist['ID'][len(closedlist)-1])
目前这个A*算法的实现没有找到完整的路径。有什么建议吗?
编辑: 我已经尝试将考虑的邻居数量从4增加到10,我得到了一条路径,但不是最优路径。
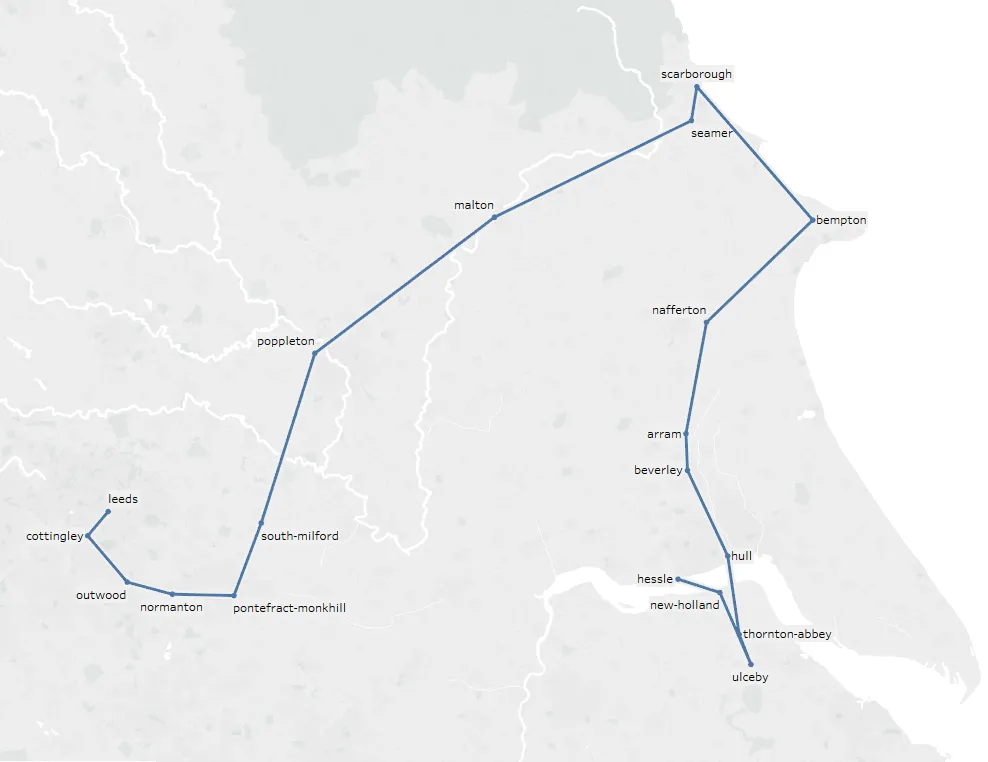
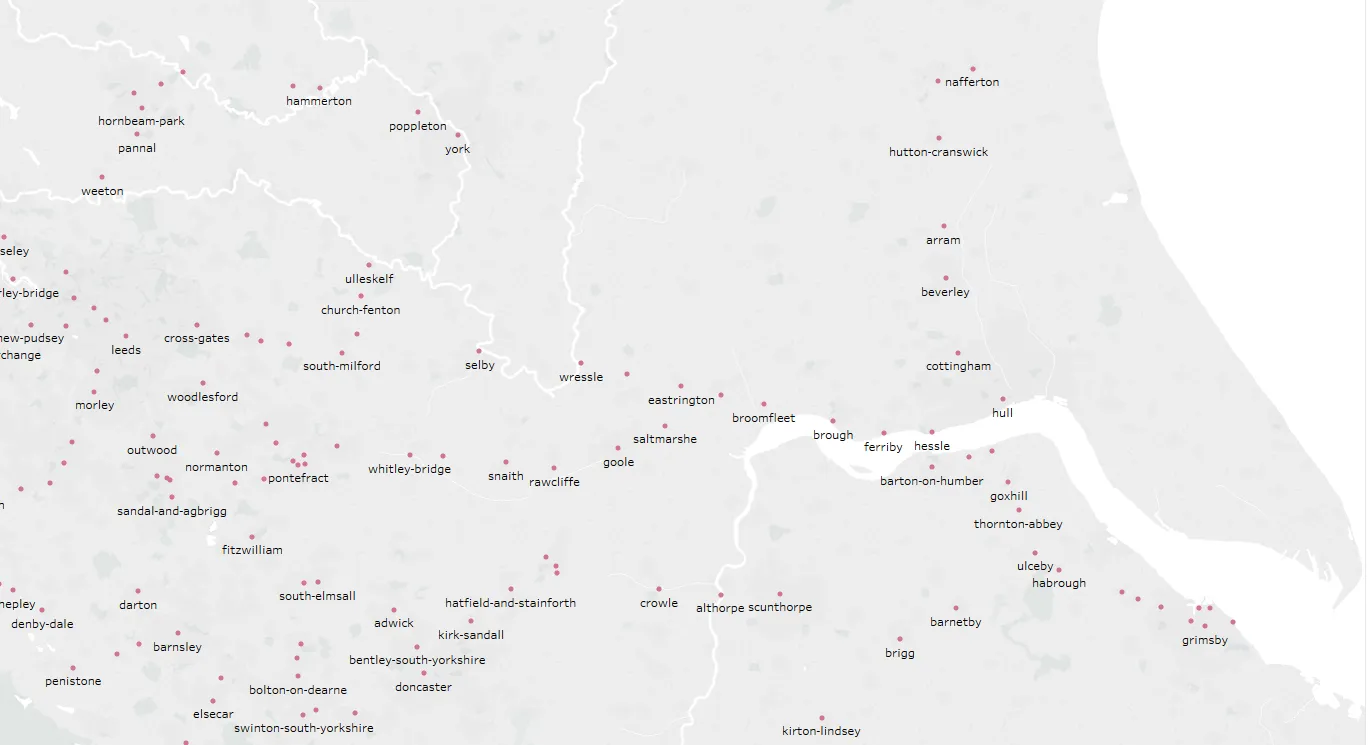 ^ 可用节点
^ 可用节点原始数据: 链接
values的结果是一个二维的 numpy 矩阵,检查<int> in ...values将返回 true,即使 int 不是索引,而是矩阵中的任何其他 int(在这种情况下,它是父节点的索引)。你能试着将这些检查更改为adjacentLocations['ID'][index] in openlist['ID'].values吗? - tobias_k