为什么双向链表中节点删除的时间复杂度(O(1))比单向链表中的节点删除时间复杂度(O(n))更快呢?
单链表和双链表节点删除的时间复杂度
29
- empty heart
9个回答
46
该问题假设已知要删除的节点并可用指向该节点的指针。
为了删除一个节点并将前一个节点和后一个节点连接起来,需要知道它们的指针。在双向链表中,这两个指针都在要删除的节点中可用。此时时间复杂度是常数级别,即O(1)。
而在单向链表中,先前节点的指针是未知的并且只能通过从头开始遍历列表,直到达到具有指向要删除的节点的下一个节点指针的节点才能找到它。此时时间复杂度为O(n)。
在只知道要删除的节点值的情况下,必须搜索列表,此时在单向和双向链表中时间复杂度都变成了O(n)。
- Raj
1
3关于从单向链表中删除节点需要 O(n) 复杂度的说法是不正确的 - 可以看下面我的回答。有一个技巧,即将要被删除的节点的值替换为其后继节点的值,然后直接跳过该后继节点,将指针指向它之后的节点,这样就不需要遍历整个链表了。 - Ben
13
实际上,单链表中的删除操作也可以以O(1)的时间复杂度实现。
假设有一个单链表,其状态如下:
SinglyLinkedList:
Node 1 -> Node 2
Node 2 -> Node 3
Node 3 -> Node 4
Node 4 -> None
Head = Node 1
我们可以这样实现删除节点2:
Node 2 Value <- Node 3 Value
Node 2 -> Node 4
在这里,我们将Node 2的值替换为其下一个节点Node 3的值,并将其下一个指针设置为Node 3的下一个指针Node 4,跳过现在有效地“重复”的Node 3。因此不需要遍历。
- Ben
7
2这个说法有道理,但是当删除最后一个元素时,除非你有对前一个(倒数第二个)节点的引用,否则它实际上不起作用。 - peterfields
在这种情况下,@peterfields,您只需完全删除该节点,以便先前节点的引用不再指向任何内容。关于GC等具体细节显然取决于技术和实现(例如,您可以使用弱引用)。 - Ben
2@mangusta 这是不正确的。你所描述的是一个搜索操作,然后是一个删除操作。删除操作已经知道要删除哪个节点。如果对常见数据结构的时间复杂度有疑问,可以参考 bigocheatsheet.com。 - Ben
你不需要复制数据,可以有一个指向节点的引用(指针),就像链表中的节点指向下一个节点一样。 - Ben
需要注意的是,使用这种解决方案时,您没有释放/取消分配节点3。正如答案所述,这将使您拥有一个有效的“副本”(和断开连接的)节点3。这将改变单向链表通常为O(n)的空间复杂度。我并不是说您不能以这种方式“删除”节点,但这绝对不是标准做法,也不是没有缺点的。 - Luke Orth
显示剩余2条评论
6
因为你无法回过头去......
- Paul
5
在已知位置插入和删除的时间复杂度为O(1)。然而,要找到该位置的时间复杂度为O(n),除非它是列表的头部或尾部。
当我们谈论插入和删除的复杂度时,通常假设我们已经知道将发生的位置。
- Isabel Jinson
3
这与修复在删除节点之前的前一个节点中的下一个指针的复杂性有关。
- i_am_jorf
3
除非要删除的元素是头(或第一个)节点,否则我们需要遍历到要删除的节点之前的节点。因此,在最坏情况下,即需要删除最后一个节点时,指针必须一直到达倒数第二个节点,从而遍历(n-1)个位置,这给我们带来了O(n)的时间复杂度。
- Nilashish Chakraborty
2
我认为除非您知道要删除的节点的地址,否则它不是O(1)。您难道不需要循环到从头开始找到要删除的节点吗?
如果您有要删除的节点的地址,那么它是O(1),因为您拥有它的前一个节点链接和下一个节点链接。由于您拥有所有必要的链接,只需重新排列链接并释放“感兴趣的节点”即可使其出现在列表中。
但是,在单向链表中,您必须从头开始遍历以获取其前一个和下一个地址,无论您是否拥有要删除的节点的地址或节点位置(例如第1个、第2个、第10个等)。
如果您有要删除的节点的地址,那么它是O(1),因为您拥有它的前一个节点链接和下一个节点链接。由于您拥有所有必要的链接,只需重新排列链接并释放“感兴趣的节点”即可使其出现在列表中。
但是,在单向链表中,您必须从头开始遍历以获取其前一个和下一个地址,无论您是否拥有要删除的节点的地址或节点位置(例如第1个、第2个、第10个等)。
- srikar sana
1
假设有一个从1到10的链表,您需要删除节点5,而其位置已知。
你需要将4的下一个指针连接到6,才能删除5。
双向链表 您可以使用5的前一个指针转到4。然后您可以进行操作。
时间复杂度 = O(N)
1 -> 2 -> 3 -> 4 -> 5-> 6-> 7-> 8 -> 9 -> 10
你需要将4的下一个指针连接到6,才能删除5。
双向链表 您可以使用5的前一个指针转到4。然后您可以进行操作。
4->next = 5->next;
或者
Node* temp = givenNode->prev;
temp->next = givenNode->next;
时间复杂度 = O(1)
- 单向链表 由于单向链表没有前一个指针,因此无法向后移动,所以必须从头部遍历列表
Node* temp = head;
while(temp->next != givenNode)
{
temp = temp->next;
}
temp->next = givenNode->next;
时间复杂度 = O(N)
- Roomi
0
在LRU缓存设计中,双向链表中的删除需要O(1)时间。 LRU缓存是用哈希映射和双向链表实现的。 在双向链表中,我们存储值,在哈希映射中存储链表节点的指针。
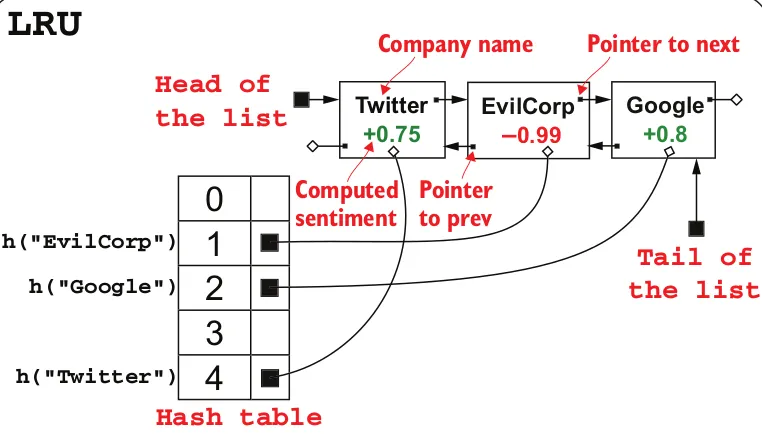
如果发生缓存命中,我们必须将元素移动到列表的前面。如果节点在双向链表的中间某处,由于我们在哈希映射中保持指针并以O(1)时间检索,因此我们可以通过删除它来。
next_temp=retrieved_node.next
prev_temp=retrieved_node.prev
然后将指针设置为None
retrieved_node.next=None
retrieved_node.prev=None
然后你可以重新连接链表中缺失的部分
prev_temp.next=next_temp
- Yilmaz
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接