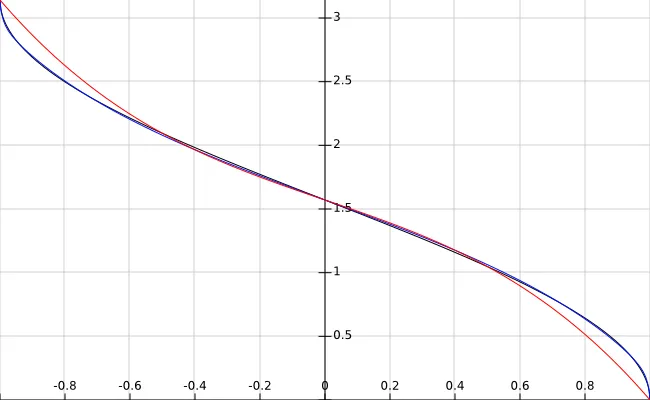
我有自己的算法。它非常精确并且速度相当快。它是基于我构建的四次收敛理论工作的。这个方程式很有趣,你可以在这里看到它以及它对我的对数近似收敛速度的影响:https://www.desmos.com/calculator/yb04qt8jx4
这是我的反余弦代码:
function acos(x)
local a=1.43+0.59*x a=(a+(2+2*x)/a)/2
local b=1.65-1.41*x b=(b+(2-2*x)/b)/2
local c=0.88-0.77*x c=(c+(2-a)/c)/2
return (8*(c+(2-a)/c)-(b+(2-2*x)/b))/6
end
很多都是平方根估算。它非常有效,除非您接近于对0取平方根。它的平均误差(不包括x=0.99到1)为0.0003。问题在于,当x等于0.99时,它开始变得糟糕,而当x等于1时,准确度的差异变为0.05。当然,这可以通过对平方根进行更多迭代来解决(呵呵,不行),或者像这样小小的事情,如果x>0.99,则使用不同的平方根线性化,但这会使代码变得冗长和丑陋。
如果您不太关心准确性,只需每个平方根进行一次迭代,这应该仍然可以使您保持在0.0162或其他某个准确度范围内:
function acos(x)
local a=1.43+0.59*x a=(a+(2+2*x)/a)/2
local b=1.65-1.41*x b=(b+(2-2*x)/b)/2
local c=0.88-0.77*x c=(c+(2-a)/c)/2
return 8/3*c-b/3
end
如果你可以接受的话,你可以使用预先存在的平方根代码。这将消除在x=1时方程变得有点疯狂的情况:
function acos(x)
local a = math.sqrt(2+2*x)
local b = math.sqrt(2-2*x)
local c = math.sqrt(2-a)
return 8/3*d-b/3
end
不过,如果你真的时间紧迫,记住你可以将arccos线性化为3.14159-1.57079x,然后只需执行:
function acos(x)
return 1.57079-1.57079*x
end
无论如何,如果你想要查看我的反余弦逼近方程列表,你可以前往
https://www.desmos.com/calculator/tcaty2sv8l。我知道我的逼近对于某些事情来说并不是最好的,但如果你正在做一些需要我的逼近方程的事情,请使用它们,但请尽量在引用中提到我。
math.h库中的sinf函数仅花费大约2.5倍于你的近似函数的时间。考虑到你的函数是内联的而库调用不是,这并没有太大的区别。我猜测,如果你添加范围缩减,使它可以像标准函数一样使用,你将会有完全相同的速度。 - Damon