尝试读取.csv文件,其中行看起来像这样:
gif,940ff2312-4325-8898dfs-9ce1ca56c5sfb,'[{"mid": "/m/083dsf", "description": "buff", "probability": 0.9663228988647461, "topic": 0.9663228988647461}]'
我需要读取这些行并将其放入两个列表中:gif和bif。每个列表必须包含一对元组:第一个字符串(在我的示例中为'gif'),字典列表(在单引号中的第三个元素是我的示例)。
由于read_csv会引发错误,因此无法正确解析它。尝试了简单的字符串方法,它有效,但修复字典列表很麻烦,我认为这不好/不优化。尝试了JSON - 不起作用。
以下是我的方法:
gif = []
bif = []
with open('file.csv', 'r', encoding = 'utf-8') as file:
lines = file.readlines()
for line in lines:
obj = line[:line.find(',')]
arr = line[line.find('['):-2]
json_acceptable_string = arr.replace("'", "\"")
arr = json.loads(json_acceptable_string)
if obj == 'gif':
gif.append((obj, arr))
elif obj == 'bif':
bif.append((obj, arr))
你有什么解决方法吗?也许在pandas中有一些误解和好的技巧?
更新:我也尝试了这种方式:
import csv
gif = []
bif = []
with open('file.csv', 'rt', encoding='utf-8') as file:
csv_reader = csv.reader(file, delimiter=',', quotechar="'")
for line in csv_reader:
for obj, Id, objArr in line: # here I'm trying to split it in 3 objects
if obj == 'gif':
gif.append((obj, arr))
elif obj == 'bif':
bif.append((obj, arr))
但它引发了:
ValueError: too many values to unpack (expected 3)
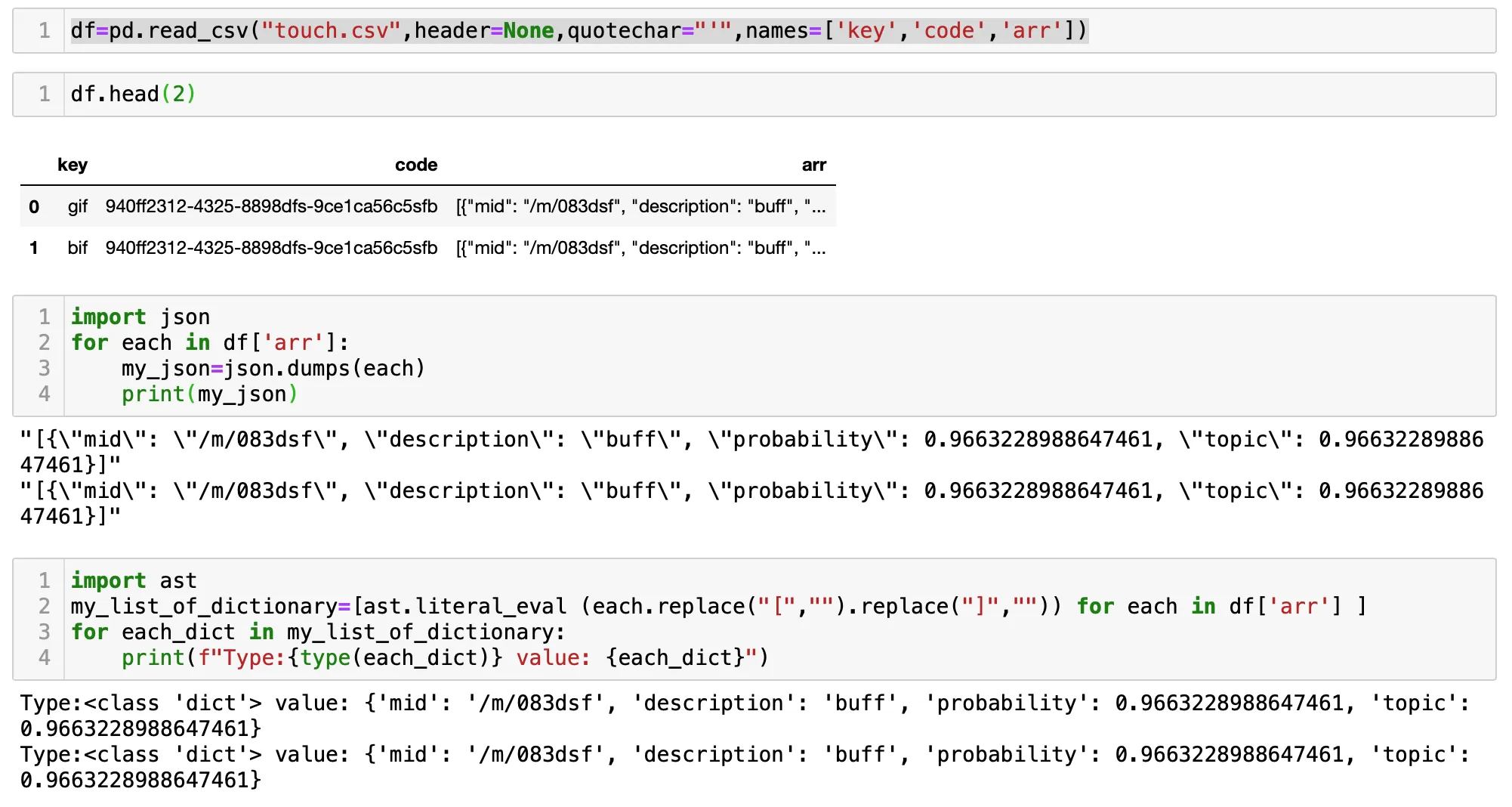
df=pd.read_csv("touch.csv",header=None,quotechar="'",names=['key','code','arr']),然后可以像这样构建JSON:values=[json.dumps(each) for each in df['arr']]。如果你能展示你想要的输出,我可以更具体地回答。 - undefinedobj, Id, objArr = *line- 然而,由于它依赖于解包和解析行长度相同,这是不清楚的,应该避免使用。你可以使用以下代码:obj = line[0]、Id = line[1]和objArr = line[1],这样更清晰但更冗长。 - undefinedjson.dumps()后面需要添加json.loads(),但我无法弄清楚为什么结果仍然是字符串,而不是字典... - undefined