as.factor是factor的一个包装器,但如果输入向量已经是因子,则可以快速返回:
function (x)
{
if (is.factor(x))
x
else if (!is.object(x) && is.integer(x)) {
levels <- sort(unique.default(x))
f <- match(x, levels)
levels(f) <- as.character(levels)
if (!is.null(nx <- names(x)))
names(f) <- nx
class(f) <- "factor"
f
}
else factor(x)
}
来自Frank的评论:这不仅仅是一个包装器,因为这个“快速返回”将保留因子水平,而factor()则不会:
f = factor("a", levels = c("a", "b"))
factor(f)
as.factor(f)
两年后的扩展回答,包括以下内容:
- 手册上说了什么?
- 性能:当输入为因子时,
as.factor > factor
- 性能:当输入为整数时,
as.factor > factor
- 未使用的水平或NA水平
- 使用R的分组函数时要小心:注意未使用或NA水平
说明书上说什么?
?factor 的文档提到了以下内容:
‘factor(x, exclude = NULL)’ applied to a factor without ‘NA’s is a
no-operation unless there are unused levels: in that case, a
factor with the reduced level set is returned.
‘as.factor’ coerces its argument to a factor. It is an
abbreviated (sometimes faster) form of ‘factor’.
性能:当输入是因子时,as.factor > factor
“无操作”这个词有点含糊不清。不要把它理解为“什么都不做”;实际上,它的意思是“做了很多事情,但本质上没有改变任何东西”。以下是一个例子:
set.seed(0)
f <- sample(gl(1e+6, 10))
system.time(f1 <- factor(f))
system.time(f2 <- factor(f, exclude = NULL))
system.time(f3 <- as.factor(f))
identical(f, f1)
identical(f, f2)
identical(f, f3)
as.factor 可以快速返回结果,但是 factor 并不是真正的“no-op”(不执行操作)。让我们对 factor 进行分析,看看它都做了什么。
Rprof("factor.out")
f1 <- factor(f)
Rprof(NULL)
summaryRprof("factor.out")[c(1, 4)]
它首先对输入向量
f 的
unique 值进行排序,然后将
f 转换为字符向量,最后使用
factor 将字符向量强制转换回因子。这是确认
factor 源代码的方法。
function (x = character(), levels, labels = levels, exclude = NA,
ordered = is.ordered(x), nmax = NA)
{
if (is.null(x))
x <- character()
nx <- names(x)
if (missing(levels)) {
y <- unique(x, nmax = nmax)
ind <- sort.list(y)
levels <- unique(as.character(y)[ind])
}
force(ordered)
if (!is.character(x))
x <- as.character(x)
levels <- levels[is.na(match(levels, exclude))]
f <- match(x, levels)
if (!is.null(nx))
names(f) <- nx
nl <- length(labels)
nL <- length(levels)
if (!any(nl == c(1L, nL)))
stop(gettextf("invalid 'labels'; length %d should be 1 or %d",
nl, nL), domain = NA)
levels(f) <- if (nl == nL)
as.character(labels)
else paste0(labels, seq_along(levels))
class(f) <- c(if (ordered) "ordered", "factor")
f
}
因此,函数factor的设计是为了处理字符向量,并且它将as.character应用于其输入以确保如此。我们至少可以从上面学到两个与性能相关的问题:
- 对于数据框
DF,如果许多列已经是因子,则lapply(DF,as.factor)在类型转换时比lapply(DF,factor)快得多。
- 函数
factor很慢可以解释为什么一些重要的R函数很慢,例如table:R:table函数令人惊讶地慢
性能:as.factor> factor,当输入为整数时
因子变量是整数变量的近亲。
unclass(gl(2, 2, labels = letters[1:2]))
storage.mode(gl(2, 2, labels = letters[1:2]))
这意味着将整数转换为因子比将数字/字符转换为因子更容易。
as.factor 就可以轻松解决这个问题。
x <- sample.int(1e+6, 1e+7, TRUE)
system.time(as.factor(x))
system.time(factor(x))
未使用的水平或NA水平
现在让我们通过一些关于factor和as.factor对因子水平(如果输入已经是一个因子)的影响的例子。Frank给出了一个未使用的因子水平的例子,我将提供一个包含NA水平的示例。
f <- factor(c(1, NA), exclude = NULL)
as.factor(f)
factor(f, exclude = NULL)
factor(f)
有一个(通用的)函数droplevels可用于删除因子中未使用的级别。 但是,默认情况下无法删除NA级别。
droplevels.factor
droplevels(f)
droplevels(f, exclude = NA)
注意使用R的分组函数时要小心:注意未使用或NA水平
R函数执行分组操作,如split,tapply希望我们提供因子变量作为“按”变量。但是,通常我们只提供字符或数字变量。因此,在内部,这些函数需要将它们转换为因子,并且可能大多数函数首先使用as.factor(至少对于split.default和tapply而言)。table函数看起来像一个例外,我发现它内部使用factor而不是as.factor。可能有一些特殊考虑,但不幸的是在我检查其源代码时并不明显。
由于大多数分组R函数使用as.factor,如果它们给出了一个具有未使用或NA级别的因子,则该组将出现在结果中。
x <- c(1, 2)
f <- factor(letters[1:2], levels = letters[1:3])
split(x, f)
tapply(x, f, FUN = mean)
有趣的是,尽管
table 不依赖于
as.factor,它仍然保留了那些未使用的水平值:
table(f)
有时这种行为可能是不期望的。一个经典的例子是
barplot(table(f)):
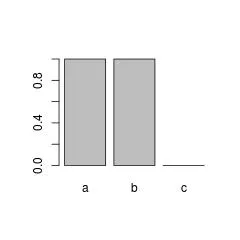
如果这真的不需要,我们需要手动从因子变量中删除未使用或
NA级别,使用
droplevels或
factor。
提示:
1.
split有一个默认为
FALSE的参数
drop,因此使用
as.factor; 通过
drop = TRUE函数
factor被使用。
2.
aggregate依赖于
split,因此它也有一个
drop参数,默认为
TRUE。
3.
tapply没有
drop,尽管它也依赖于
split。特别是文档
?tapply说
as.factor被(始终)使用。
as.class的函数。 - Gregor Thomas