tl;dr
我不是在询问关于 purrr 提供的语法或其他功能的喜好或厌恶。
选择符合你使用情况并最大化你的生产力的工具。对于优先考虑速度的生产代码,请使用 *apply,对于需要小内存占用的代码,请使用 map。基于人体工程学,map 对于大多数用户和大多数一次性任务来说可能更可取。
方便
2021 年 10 月更新
由于接受的回答和第二个最受欢迎的帖子都提到了语法的便利性:
R 版本 4.1.1 及更高版本现在支持简写匿名函数 \(x) 和管道符号 |> 语法。要检查你的 R 版本,请使用 version[['version.string']]。
library(purrr)
library(repurrrsive)
lapply(got_chars[1:2], `[[`, 2) |>
lapply(\(.) . + 1)
map(got_chars[1:2], 2) %>%
map(~ . + 1)
purrr 方法的语法通常更短,如果您的任务涉及对类似列表的对象进行多个操作。
nchar(
"lapply(x, fun, y) |>
lapply(\\(.) . + 1)")
nchar(
"library(purrr)
map(x, fun) %>%
map(~ . + 1)")
考虑到一个人在他们的职业生涯中可能会写数万或数十万个这样的调用,这种语法长度差异相当于写1或2部小说(平均小说80,000个字),假设代码是打出来的。进一步考虑 你的 代码输入速度(~65个单词每分钟?),你的 输入准确性(你是否经常打错某些语法 (\"< ?)),你的 对函数参数的记忆力,那么你可以公平地比较使用一种风格或两种风格的生产力。
另一个考虑因素可能是你的目标受众。就我个人而言,我发现解释purrr::map如何工作比解释lapply更难,正是因为它的简洁语法。
1 |>
lapply(\(.z) .z + 1)
#> [[1]]
#> [1] 2
1 %>%
map(~ .z+ 1)
#> Error in .f(.x[[i]], ...) : object '.z' not found
but,
1 %>%
map(~ .+ 1)
#> [[1]]
#> [1] 2
速度
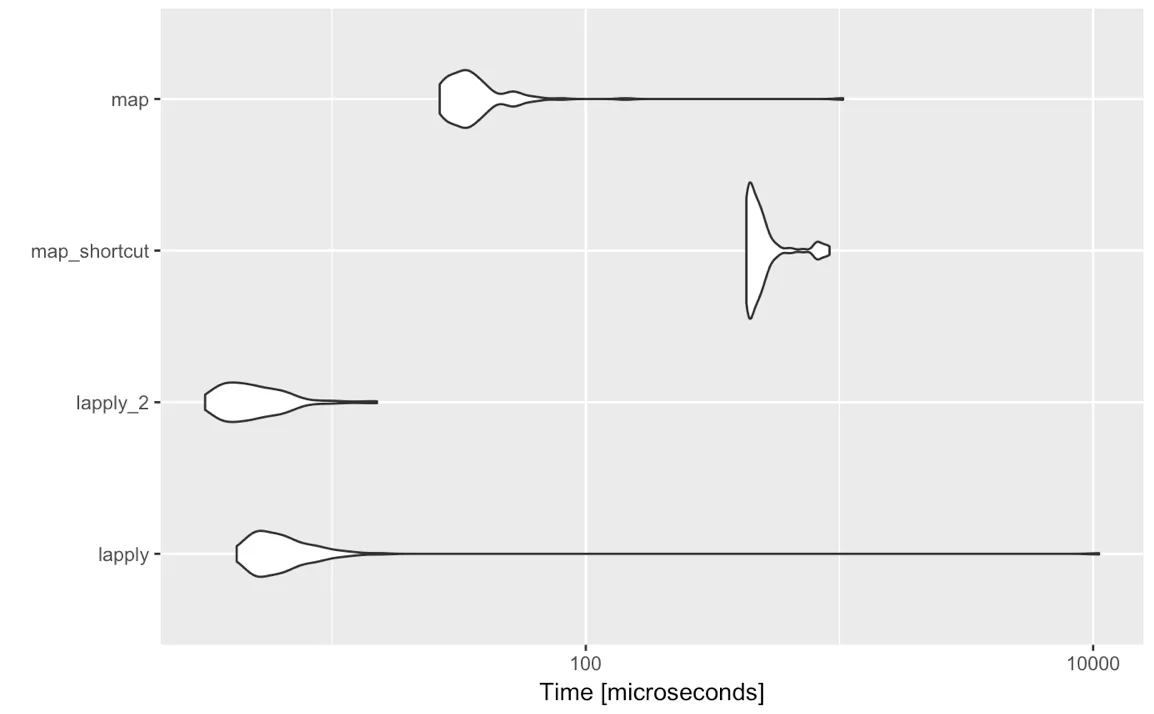
在处理类似列表的对象时,通常会执行多个操作。需要注意的是,在大多数代码 - 处理大型列表和使用情况时,purrr 的开销是微不足道的。
got_large <- rep(got_chars, 1e4) # 300 000 elements, 1.3 GB in memory
bench::mark(
base = {
lapply(got_large, `[[`, 2) |>
lapply(\(.) . * 1e5) |>
lapply(\(.) . / 1e5) |>
lapply(\(.) as.character(.))
},
purrr = {
map(got_large, 2) %>%
map(~ . * 1e5) %>%
map(~ . / 1e5) %>%
map(~ as.character(.))
}, iterations = 100,
)[c(1, 3, 4, 5, 7, 8, 9)]
# A tibble: 2 x 7
expression median `itr/sec` mem_alloc n_itr n_gc total_time
<bch:expr> <bch:tm> <dbl> <bch:byt> <int> <dbl> <bch:tm>
1 base 1.19s 0.807 9.17MB 100 301 2.06m
2 purrr 2.67s 0.363 9.15MB 100 919 4.59m
这个差异会随着操作次数的增加而扩大。如果你正在编写被某些用户常规使用或其他包依赖的代码,速度可能是在选择基础R和purr之间需要考虑的重要因素。请注意,
purr 的内存占用略低。
然而,有一个反驳的观点:
如果你想要速度,就去使用低级语言。
tidyverse,则可以从管道%>%和匿名函数~ .x + 1的语法中受益。 - Aurèle~{}简写的lambda表达式(无论是否使用{})对于我来说很方便,因为它可以直接用于purrr::map()。purrr::map_…()中的类型强制执行很方便,比vapply()更易懂。虽然purrr::map_df()是一个非常耗费资源的函数,但它也简化了代码。当然,坚持使用基本的R[lsv]apply()也完全没有问题。 - hrbrmstrpurrr包中的东西。我的观点是:tidyverse非常适合分析/交互/报告等操作,而不适合编程。如果你不得不使用lapply或map,那么你就是在编程,有可能最终创建一个程序包。那么依赖越少越好。另外,有时我看到人们在使用map时采用相当晦涩的语法。现在我看到性能测试:如果你习惯于使用apply家族函数,请坚持使用它。 - Eric Lecoutre