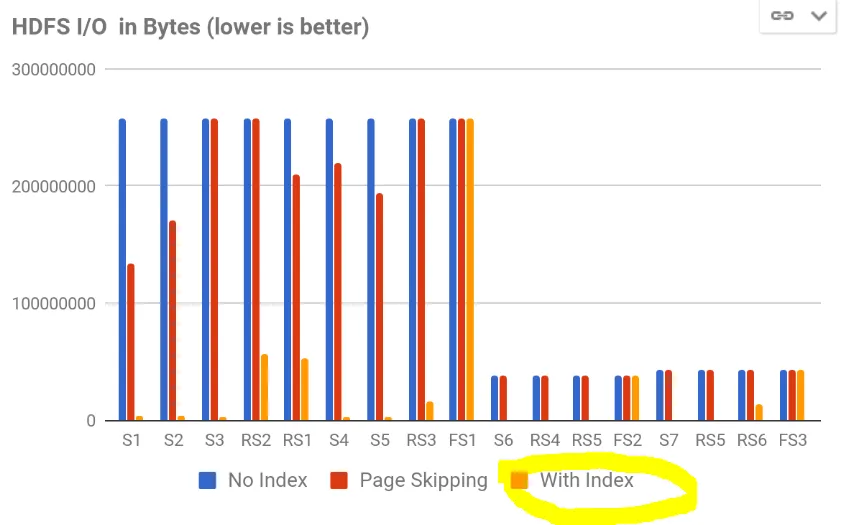
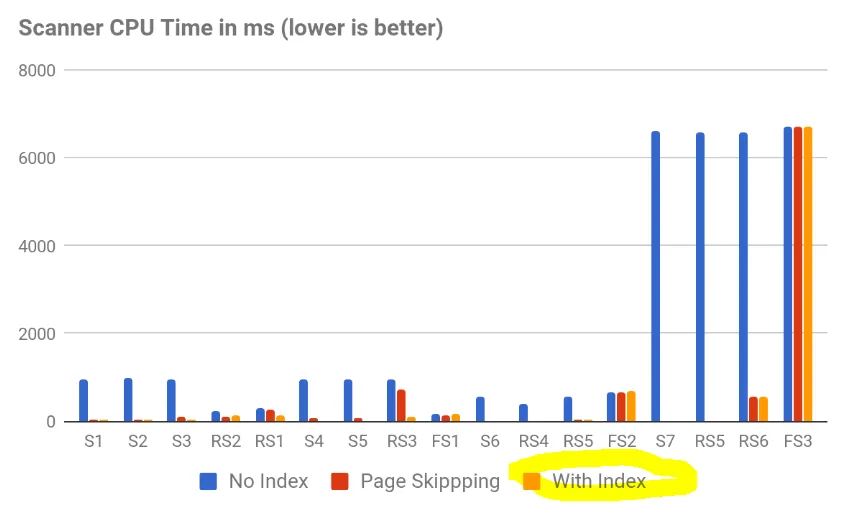
我希望能够对Parquet表执行快速范围查询。与总大小相比,需要返回的数据量非常小,但因为必须执行完整列扫描,所以对于我的使用情况来说太慢了。
使用索引可以解决这个问题,我读到Parquet 2.0中将添加此功能。然而,我找不到任何其他有关此功能的信息,因此我猜想它没有被添加。如果数据被排序(在我的情况下是这样的),我不认为会有任何根本性的障碍阻止添加(多列)索引。
我的问题是:Parquet什么时候会添加索引,如何进行高级别设计?我想,如果索引指向正确的分区,我已经很满意。
此致敬礼,
Sjoerd。