我认为你可以使用 groupby 按 hour 和 weekday 进行聚合sum(或者也许是mean),最后通过 unstack 和 DataFrame.plot 进行重塑:
df = df.groupby([df['Date'].dt.hour, 'weekday'])['Cyclists'].sum().unstack().plot()
使用pivot_table解决方案:
df1 = df.pivot_table(index=df['Date'].dt.hour,
columns='weekday',
values='Cyclists',
aggfunc='sum').plot()
示例:
N = 200
np.random.seed(100)
rng = pd.date_range('2016-01-01', periods=N, freq='H')
df = pd.DataFrame({'Date': rng, 'Cyclists': np.random.randint(100, size=N)})
df['weekday'] = df['Date'].dt.weekday_name
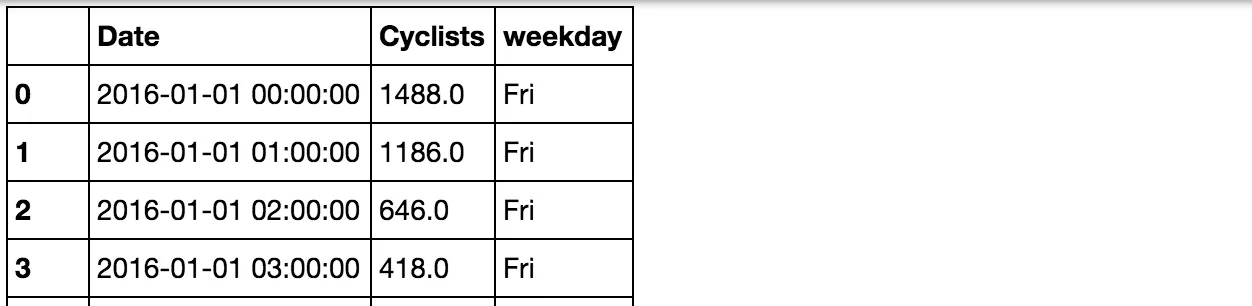
print (df.head())
Cyclists Date weekday
0 8 2016-01-01 00:00:00 Friday
1 24 2016-01-01 01:00:00 Friday
2 67 2016-01-01 02:00:00 Friday
3 87 2016-01-01 03:00:00 Friday
4 79 2016-01-01 04:00:00 Friday
print (df.groupby([df['Date'].dt.hour, 'weekday'])['Cyclists'].sum().unstack())
weekday Friday Monday Saturday Sunday Thursday Tuesday Wednesday
Date
0 102 91 120 53 95 86 21
1 102 83 100 27 20 94 25
2 121 53 105 56 10 98 54
3 164 78 54 30 8 42 6
4 163 0 43 48 89 84 37
5 49 13 150 47 72 95 58
6 24 57 32 39 30 76 39
7 127 76 128 38 12 33 94
8 72 3 59 44 18 58 51
9 138 70 67 18 93 42 30
10 77 3 7 64 92 22 66
11 159 84 49 56 44 0 24
12 156 79 47 34 57 55 55
13 42 10 65 53 0 98 17
14 116 87 61 74 73 19 45
15 106 60 14 17 54 53 89
16 22 3 55 72 92 68 45
17 154 48 71 13 66 62 35
18 60 52 80 30 16 50 16
19 79 43 2 17 5 68 12
20 11 36 94 53 51 35 86
21 180 5 19 68 90 23 82
22 103 71 98 50 34 9 67
23 92 38 63 91 67 48 92
df.groupby([df['Date'].dt.hour, 'weekday'])['Cyclists'].sum().unstack().plot()
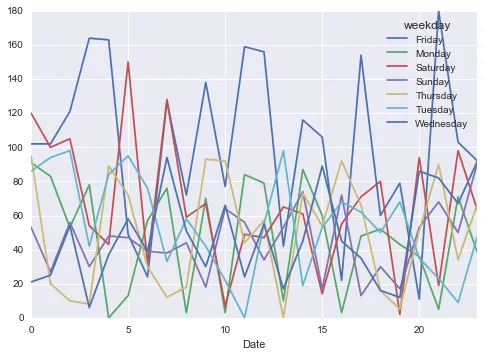
编辑:
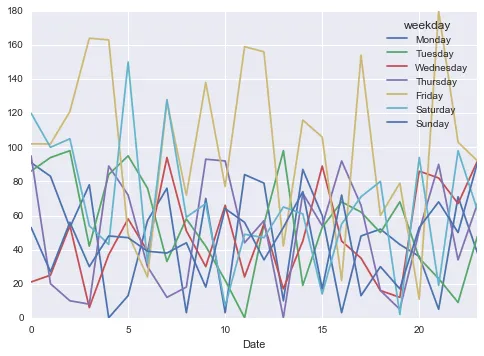
你还可以将wekkday转换为categorical,以便按照星期名称对列进行正确排序:
names = [ 'Monday', 'Tuesday', 'Wednesday', 'Thursday','Friday', 'Saturday', 'Sunday']
df['weekday'] = df['weekday'].astype('category', categories=names, ordered=True)
df.groupby([df['Date'].dt.hour, 'weekday'])['Cyclists'].sum().unstack().plot()
df.groupby(df['Date'].dt.hour),然后针对此进行绘图。 - EdChum