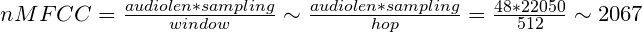from librosa.feature import mfcc
from librosa.core import load
def extract_mfcc(sound):
data, frame = load(sound)
return mfcc(data, frame)
mfcc = extract_mfcc("sound.wav")
我知道data * frame = length of audio.
但是,当我按上述方式计算MFCC并获取其形状时,结果如下:(20, 2086)
这些数字代表什么意思? 如何仅通过其MFCC计算音频的时间?
我试图计算每毫秒音频的平均MFCC。
任何帮助都将不胜感激!谢谢 :)