我正在通过regexr.com学习正则表达式,以便在尝试匹配模式时不那么令人尴尬和不堪入目。
该网站为正则表达式语句的每个组成部分提供了解释,但我无法确定为什么这个表达式:
该网站为正则表达式语句的每个组成部分提供了解释,但我无法确定为什么这个表达式:
/([o])\w+/g
不能匹配单词“to”的任何部分。
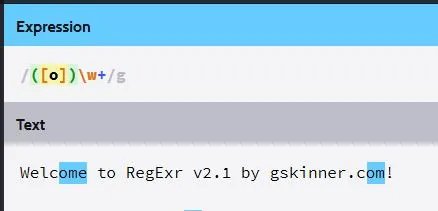
[o]应该匹配字母o,而\w开关告诉它去匹配单词。我还需要解释一下为什么它只匹配单词中o后面的字母(例如单词Welcome中的ome),而不是包含字母o的整个单词。最后,对于+的解释告诉我它意味着“匹配前面的标记1次或多次”,而切换这个似乎控制着是否只匹配o后面的1个字母,或者匹配单词中o后面的所有字母。非常感谢您对此进行澄清。抱歉问题有点初学者。
\w是一个单词字符(通常是字母数字和下划线),因此to不匹配/[o]\w+/g,因为在to之后没有更多的单词字符。 - BeyelerStudios\w只是[a-zA-z0-9_]的简写。就像\d是[0-9]的简写一样。请参见http://www.regular-expressions.info/shorthand.html。 - Felix Kling