我使用regex101分析了这两个正则表达式。 我认为/\S+:/的回溯是正确的。 但是我不明白其中的区别。 我错了吗?
为什么 /\w+:/ 和 /\S+:/ 处理回溯不同?
16
- Mr.kang
2
我其实很好奇你是如何逐步实现这个过程以便进行分析的! - user541686
5在regex101.com上输入正则表达式,然后使用页面左侧的“正则表达式调试器”。 - OnlineCop
2个回答
15
这是一种名为自动占有化的pcre优化。
PCRE的“自动占有化”优化通常适用于模式末尾(以及内部)的字符重复。例如,模式“
a\d+”被编译为“a\d++”,因为甚至考虑回溯到重复的数字是没有意义的。
和
由于例如,这是一种优化,将
a+b转换为a++b,以避免进入无法成功的a+的回溯。
: 不包含在 \w 中,所以您的模式被解释为 \w++:(第二个 + 避免回溯,参见占有量词)。额外的回溯状态被避免,因为没有另一个状态可以匹配。另一方面,
: 包含在 \S 中,因此这种优化不适用于第二种情况。
PCRE测试
你可以使用pcretest来查看差异 (这里有一个Windows版本可以下载here)。
模式/\w+:/需要11个步骤,输出结果为:
/\w+:/
--->get accept:
+0 ^ \w+
+3 ^ ^ :
+0 ^ \w+
+3 ^ ^ :
+0 ^ \w+
+3 ^^ :
+0 ^ \w+
+0 ^ \w+
+3 ^ ^ :
+4 ^ ^ .*
+6 ^ ^
0: accept:
然而,如果我们使用控制动词
(*NO_AUTO_POSSESS),禁用此优化,模式/(*NO_AUTO_POSSESS)\w+:/将花费14步并输出:/(*NO_AUTO_POSSESS)\w+:/
--->get accept:
+18 ^ \w+
+21 ^ ^ :
+21 ^ ^ :
+21 ^^ :
+18 ^ \w+
+21 ^ ^ :
+21 ^^ :
+18 ^ \w+
+21 ^^ :
+18 ^ \w+
+18 ^ \w+
+21 ^ ^ :
+22 ^ ^ .*
+24 ^ ^
0: accept:
- 它比\S+少1步,这是预期的,因为\w+不匹配:。
很遗憾regex101不支持这个动词。
更新: regex101现在支持这个动词,以下是比较3个案例的链接:
/\S+:/(14步) - https://regex101.com/r/cw7hGh/1/debugger/\w+:/(10步) - https://regex101.com/r/cw7hGh/2/debugger/(*NO_AUTO_POSSESS)\w+:/(13步) - https://regex101.com/r/cw7hGh/3/debugger
regex101调试器:
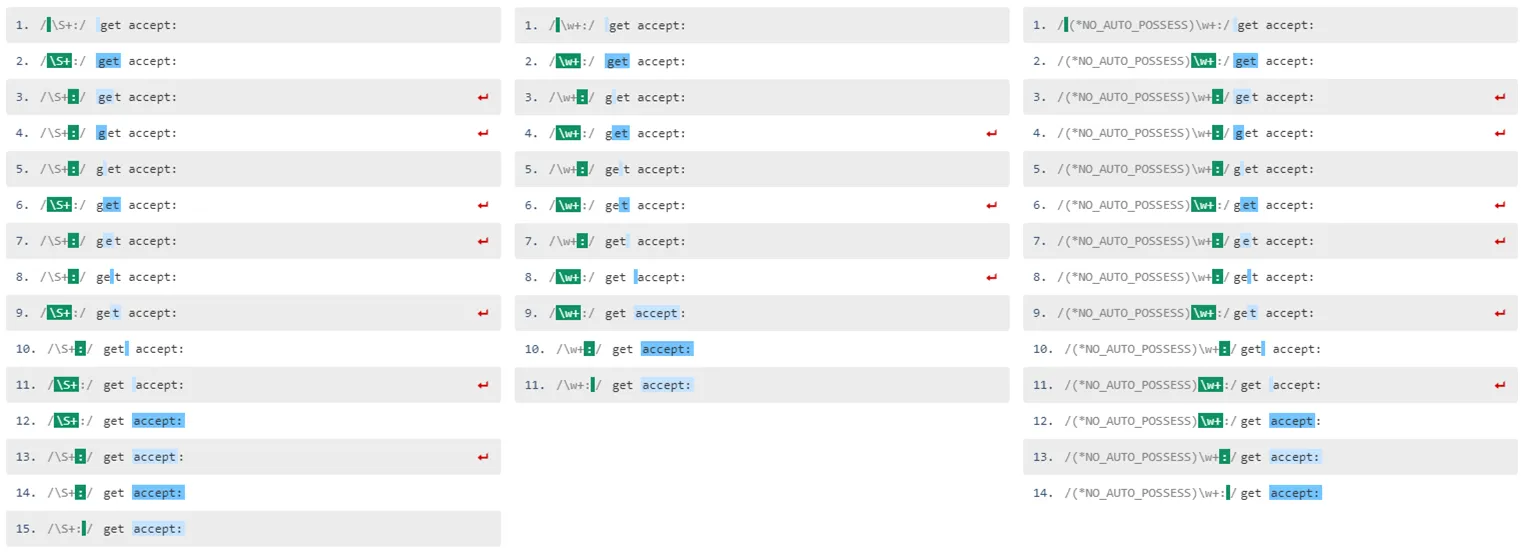
- Mariano
11
尽管这似乎是实现特定的(RegexBuddy没有显示这种行为),但可以解释如下:
\w不能匹配:,但\S可以。 因此,在确认get无法匹配之前,\S +:需要检查更多输入字符串的变化。
优化更多的正则表达式引擎将更快地排除不可能的匹配项(例如,当正则表达式包含在当前匹配的一部分中不存在的字面字符时), 但显然regex101使用的引擎并未这样做。
- Tim Pietzcker
3
我很好奇哪些正则表达式引擎更加优化,是否有任何明显的区别特征(除了您提到的行为)- 谢谢! - l'L'l
我不是很确定。我相信.NET、Perl和JGSoft的引擎都非常聪明,但我不知道是否有可比性的比较。 - Tim Pietzcker
无论如何,即使是聪明的引擎,在某些情况下也会陷入灾难性的回溯,尽管它们可能避免了一些对“天真”的实现造成问题的情况。 - Bakuriu
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
- 相关问题
- 18 JavaScript中的(/^\s+|\s+$/gm)是什么意思?
- 22 为什么JavaScript的RegExp /^\w+$/会匹配undefined?
- 5 为什么\w+匹配行末的换行符?
- 3 如何在正则表达式(R gsub)中将“\w+\W+”乘以4?
- 4 “#(\w+)=([\'"])(.*)\\2#U”是什么意思?
- 9 在Perl中,s/^\s+//和s/\s+$//有什么区别?
- 5 正则表达式模式 - 什么是((?=.*\d)|(?=.*\W+))和(?![.\n])?
- 13 为什么 s/^\s+|\s+$//g; 比两个单独的替换慢这么多?
- 3 为什么/([o])\w+/g不能匹配单词to?
- 30 正则表达式的区别:(\w+)? 和 (\w*)