我要处理的数据长这样:
+----------+------------------+--------+
| specimen | date | bucket |
+----------+------------------+--------+
| 31598D | 3/3/2010 11:38 | 10 |
| A113899 | 2/10/2010 13:50 | 11 |
| A121375 | 12/17/2010 10:06 | 2 |
| A122115 | 6/14/2010 9:33 | 10 |
| A122119 | 5/19/2010 10:08 | 3 |
| A122124 | 6/30/2010 11:43 | 4 |
| DD58834 | 6/17/2010 10:08 | 1 |
| 31598A | 3/3/2010 11:36 | 10 |
+----------+------------------+--------+
我想知道是否有可能将其转换为类似于下图的频率分布:
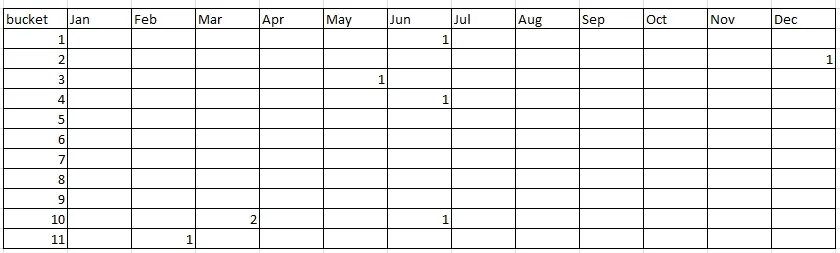
我应该在SQL Server中使用pivot函数吗?如果是这样,怎么做呢?
请注意,我可以访问SSRS,并可以将其用作解决此问题的资源。
非常感谢您的指导和时间。