你们当中有没有人实现过斐波那契堆?我几年前曾经实现过,但是它比使用基于数组的二叉堆慢了几个数量级。
当时,我认为这是一个宝贵的教训,说明研究并不总是像它声称的那么好。然而,很多研究论文声称它们的算法运行时间都是基于使用斐波那契堆的。
你是否曾经成功实现过一个高效的斐波那契堆?或者是你处理的数据集太大了,所以斐波那契堆更高效?如果是这样,一些细节将会非常感激。
你们当中有没有人实现过斐波那契堆?我几年前曾经实现过,但是它比使用基于数组的二叉堆慢了几个数量级。
当时,我认为这是一个宝贵的教训,说明研究并不总是像它声称的那么好。然而,很多研究论文声称它们的算法运行时间都是基于使用斐波那契堆的。
你是否曾经成功实现过一个高效的斐波那契堆?或者是你处理的数据集太大了,所以斐波那契堆更高效?如果是这样,一些细节将会非常感激。
Boost C++ libraries包括在boost/pending/fibonacci_heap.hpp中实现的Fibonacci堆。这个文件显然已经在pending/中存在多年,按照我的预测,它将永远不会被接受。此外,该实现中存在错误,这些错误由我的熟人和全能的家伙Aaron Windsor修复。不幸的是,我找到的大多数版本的该文件(以及Ubuntu的libboost-dev软件包中的版本)仍然存在错误;我不得不从Subversion存储库中提取一个干净的版本。
自版本1.49以来,Boost C ++库添加了许多新的堆结构,包括斐波那契堆。
我能够编译 dijkstra_heap_performance.cpp,并使用修改版的 dijkstra_shortest_paths.hpp 进行比较斐波那契堆和二叉堆。(在这一行typedef relaxed_heap<Vertex, IndirectCmp, IndexMap> MutableQueue 中,将 relaxed 改为 fibonacci。) 我最初忘记进行优化编译,在这种情况下,斐波那契堆和二叉堆的性能大致相同,斐波那契堆通常会略微优于二叉堆。在我进行了非常强的优化编译后,二叉堆得到了巨大的提升。在我的测试中,只有当图形非常大且密集时,例如:斐波那契堆才能优于二叉堆。Generating graph...10000 vertices, 20000000 edges.
Running Dijkstra's with binary heap...1.46 seconds.
Running Dijkstra's with Fibonacci heap...1.31 seconds.
Speedup = 1.1145.
顺便说一句,我强烈建议尝试使用您自己的数据结构与斐波那契堆的运行时间相匹配。我发现我只是自己重新发明了斐波那契堆。在此之前,我认为所有斐波那契堆的复杂性都是一些随意的想法,但后来我意识到它们都是自然而然且相当迫切的。
1993年,Knuth在他的书《Stanford Graphbase》中为最小生成树比较了斐波那契堆和二叉堆。他发现,在他测试的图大小(128个不同密度的顶点)下,斐波那契堆比二叉堆慢30%到60%。
源代码(使用CWEB编写,是C、数学和TeX的混合物)在MILES_SPAN部分中,可以在这里找到。
免责声明
我知道结果非常相似,而且“看起来运行时间完全被堆以外的其他因素所支配”(@Alpedar)。但是我在代码中找不到任何证据支持这一点。 代码是公开的,如果您能找到任何可能影响测试结果的因素,请告诉我。
也许我做错了什么,但我编写了一个测试,基于A.Rex的答案进行比较:
所有堆的执行时间(仅适用于完全图)非常接近。 测试是针对具有1000、2000、3000、4000、5000、6000、7000和8000个顶点的完全图进行的。对于每个测试,生成了50个随机图形,并输出每个堆的平均时间:
对于输出不太详细的问题,很抱歉,因为我需要从文本文件构建一些图表。
以下是结果(以秒为单位):
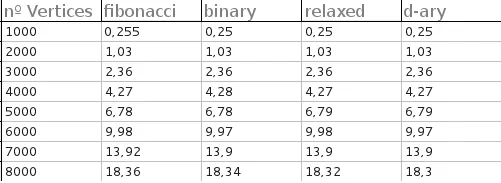
C++ 不是很了解,但你真的可以给从另一个模块导入的静态变量赋值吗?你确定你没有在同一堆上运行所有测试吗? - Thomas Ahle这里有一个相当全面的答案,以及使用斐波那契堆实现的经过测试的Dijkstra算法的C++代码 在这里