我了解梯度下降和反向传播算法。但是我不明白的是: 什么时候使用偏置很重要,如何使用它?
例如,当映射AND函数时,使用两个输入和一个输出时,它不能给出正确的权重。但是,当我使用三个输入(其中一个是偏置)时,它可以给出正确的权重。
我了解梯度下降和反向传播算法。但是我不明白的是: 什么时候使用偏置很重要,如何使用它?
例如,当映射AND函数时,使用两个输入和一个输出时,它不能给出正确的权重。但是,当我使用三个输入(其中一个是偏置)时,它可以给出正确的权重。
我认为偏置通常是有帮助的。实际上,偏置值使您能够将激活函数向左或向右移动,这可能对成功学习至关重要。
看一个简单的例子可能会有所帮助。考虑这个没有偏置的1输入、1输出网络:
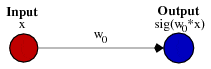
网络的输出通过将输入(x)与权重(w0)相乘并通过某种激活函数(例如sigmoid函数)传递结果来计算。
这是该网络针对不同的w0值计算出的函数:
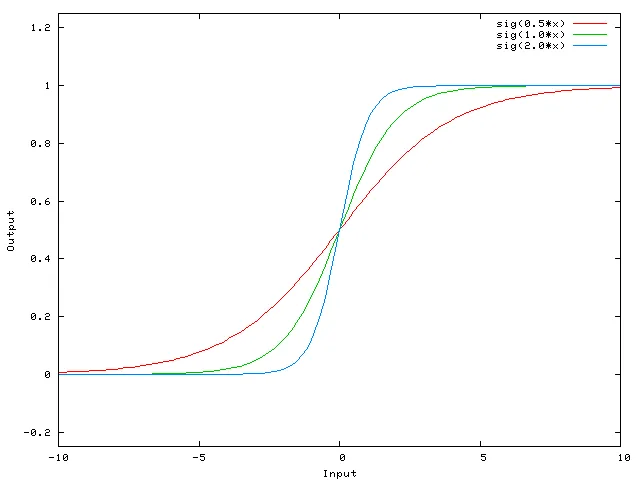
改变权重w0本质上改变了Sigmoid曲线的“陡峭程度”。这很有用,但是如果您想在x等于2时使网络输出0怎么办?仅仅改变Sigmoid的陡峭程度不会真正起作用 - 您要能够将整个曲线向右移动。
这正是偏置允许您做的。如果我们像这样向网络添加偏置:
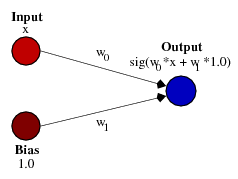
...那么网络的输出变为sig(w0 * x + w1 * 1.0)。以下是网络在各种w1值下的输出:
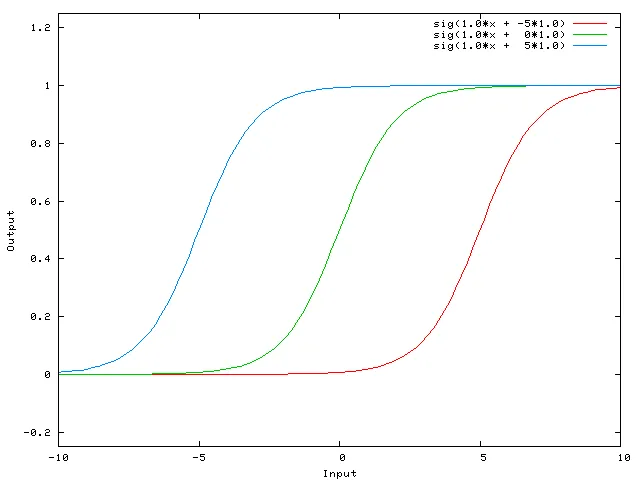
将w1设置为-5会将曲线向右移动,这使我们可以拥有在x等于2时输出0的网络。

 (来源: aihorizon.com)
(来源: aihorizon.com)
单个感知器可以用于表示许多布尔函数。
例如,如果我们假设布尔值为1(真)和-1(假),那么使用两个输入的感知器来实现AND函数的一种方法是将权重w0设置为-3,w1 = w2 = 0.5。通过将阈值更改为w0 = -0.3,可以使该感知器代表OR函数。实际上,AND和OR可以被视为m-of-n函数的特例:即,至少有m个n个输入到感知器必须为真的函数。 OR函数对应于m = 1,而AND函数对应于m = n。通过将所有输入权重设置为相同的值(例如0.5),然后相应地设置阈值w0,可以轻松地使用感知器表示任何m-of-n函数。
感知器可以表示所有基本布尔函数AND、OR、NAND(1 AND)和NOR(1 OR)。(机器学习-汤姆·米切尔)
阈值是偏置,w0是与偏置/阈值神经元相关联的权重。
偏差不是一个NN术语。它是一个通用的代数术语。
Y = M*X + C(直线方程)
如果C(偏差)= 0,那么这条直线将始终通过原点,即(0,0),并且仅依赖于一个参数M,即斜率,因此我们有更少的变量可供操作。
C,也就是偏差,可以取任何数字,并具有移动图形的作用,从而能够表示更复杂的情况。
在逻辑回归中,目标的期望值通过链接函数进行转换,以将其值限制为单位间隔。通过这种方式,模型预测可以被视为主要的输出概率,如下所示:
这是神经网络映射中的最终激活层,它打开和关闭神经元。在这里,偏差也有一个作用,它可以灵活地移动曲线,帮助我们映射模型。
神经网络中没有偏差的层仅仅是输入向量与矩阵相乘的结果。(输出向量可能会通过Sigmoid函数进行归一化,并在多层ANN中使用,但这不重要。)
这意味着您正在使用线性函数,因此所有零输入将始终映射到所有零输出。这对于某些系统可能是合理的解决方案,但通常过于严格。
使用偏差,您实际上是为您的输入空间添加了另一个维度,该维度始终取值为1,因此您避免了全零输入向量。这并不会使您失去任何普遍性,因为您训练的权重矩阵不需要是满射的,因此它仍然可以映射到以前可能的所有值。
2D ANN:
对于将两个维度映射到一个维度的ANN,例如复制AND或OR(或XOR)函数,您可以将神经网络视为执行以下操作:
在二维平面上标记所有输入向量的位置。因此,对于布尔值,您需要标记(-1,-1),(1,1),(-1,1),(1,-1)。现在,您的ANN正在二维平面上画一条直线,将正输出值与负输出值分开。
没有偏差时,这条直线必须经过零点,而有偏差时,您可以自由地将其放在任何位置。 因此,您会发现,在没有偏差的情况下,您面临AND函数的问题,因为您不能将(1,-1)和(-1,1)都放在负面。 (它们不允许处于线上。)OR函数的问题也是相同的。然而,有了偏差,画出这条直线就很容易。 请注意,即使有偏差,该情况下的XOR函数也无法解决。当你使用人工神经网络时,很少了解要学习的系统的内部情况。有些事情没有偏见就无法学习。例如,看一下以下数据:(0, 1),(1, 1),(2, 1),基本上是将任何x映射到1的函数。
如果您只有一个节点(或线性映射),则无法找到解决方案。但是,如果您有一个偏差,它就很简单!
在理想的情况下,偏差还可以将所有点映射到目标点的平均值,并让隐藏神经元对该点的差异进行建模。
仅修改神经元的权重只能改变您的传递函数的形状/曲率,而不是它的平衡/零点交叉。
引入偏置神经元可以使您在沿着输入轴水平移动转移函数曲线(左/右)的同时保持形状/曲率不变。 这将允许网络产生与默认值不同的任意输出,因此您可以自定义/移动输入到输出的映射以满足您的特定需求。
有关图形解释,请参见: http://www.heatonresearch.com/wiki/Bias
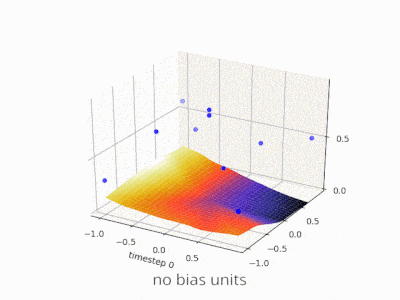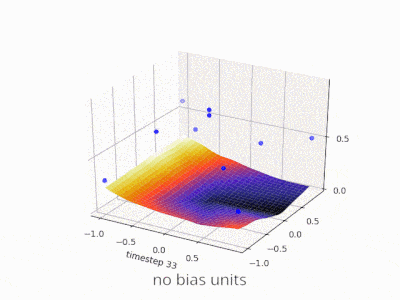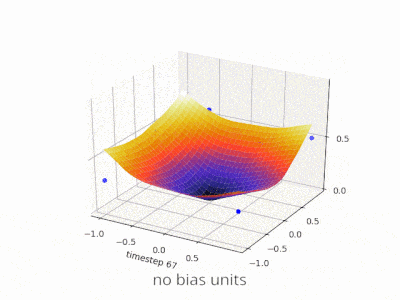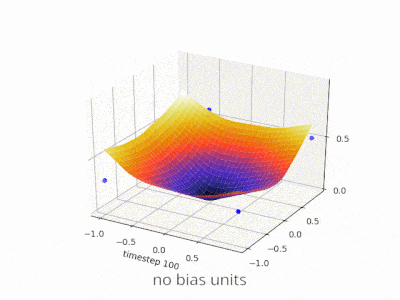
如果你正在处理图像,实际上你可能更喜欢根本不使用偏置。理论上,这样你的网络会更加独立于数据幅度,例如图片是暗的还是明亮和鲜艳的。而且网络将通过研究数据内部的相对性来学习完成它的工作。许多现代神经网络都使用此方法。
对于其他类型的数据,具有偏置可能至关重要。这取决于你正在处理什么类型的数据。如果你的信息是幅度不变的---如果输入[1,0,0.1]应该导致与输入[100,0,10]相同的结果,那么没有偏差可能更好。
{kind=link}