非捕获组,即(?:)在正则表达式中是如何使用的?它们有什么好处?
正则表达式中的非捕获组是什么?
2424
- never_had_a_name
1
70这个问题已被添加到 Stack Overflow 正则表达式 FAQ 中的 "分组" 部分。 - aliteralmind
18个回答
12
为了补充这个帖子中其他好的回答,我想要加入我发现的一个有趣的观察。
发现:你可以在一个非捕获组中放置一个捕获组。
问题详情:请看下面用于匹配Web URL的正则表达式:
var parse_url_regex = /^(?:([A-Za-z]+):)(\/{0,3})([0-9.\-A-Za-z]+)(?::(\d+))?(?:\/([^?#]*))?(?:\?([^#]*))?(?:#(.*))?$/;
这是我的输入网址字符串:
var url = "http://www.ora.com:80/goodparts?q#fragment";
我的正则表达式中的第一个组是(?:([A-Za-z]+):),它是一个非捕获组,匹配协议方案(http)和冒号(:)字符。继续匹配后会匹配到http:。但是当我运行下面的代码时:
console.debug(parse_url_regex.exec(url));
我可以看到返回的数组的第1个索引包含字符串http(请参阅截图)。
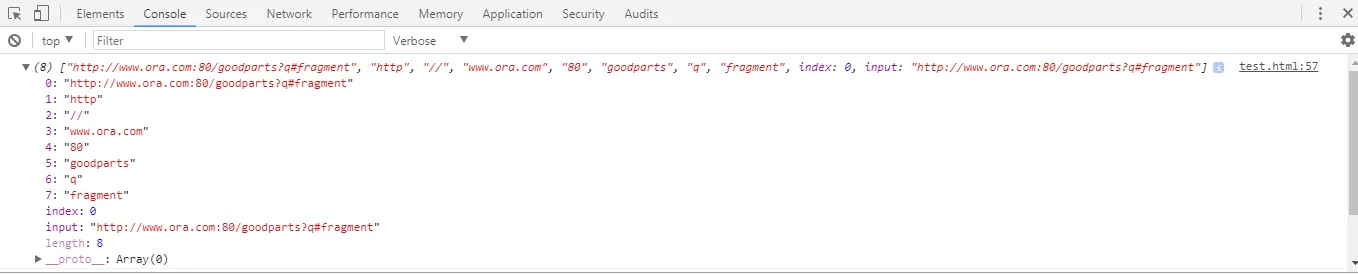
此时,我的想法是http和冒号:都不会在输出中报告,因为它们位于一个非捕获组内。如果第一个正则表达式组(?:([A-Za-z]+):)是一个非捕获组,那么为什么它会在输出数组中返回http字符串呢?
解释:如果您注意到,([A-Za-z]+)是一个捕获组(开头没有?:)。但是,该捕获组本身位于非捕获组(?:([A-Za-z]+):)中,并跟随一个冒号:字符。这就是为什么文本http仍然被捕获,但落在非捕获组内(但在捕获组外部)的冒号:字符不会在输出数组中报告的原因。
- RBT
11
我是一名 JavaScript 开发者,将尝试解释其在 JavaScript 中的重要性。
考虑这样一个情景:你想匹配 cat is animal,
当你想要匹配 cat 和 animal 并且它们两者之间应该有一个 is。
// this will ignore "is" as that's is what we want
"cat is animal".match(/(cat)(?: is )(animal)/) ;
result ["cat is animal", "cat", "animal"]
// using lookahead pattern it will match only "cat" we can
// use lookahead but the problem is we can not give anything
// at the back of lookahead pattern
"cat is animal".match(/cat(?= is animal)/) ;
result ["cat"]
//so I gave another grouping parenthesis for animal
// in lookahead pattern to match animal as well
"cat is animal".match(/(cat)(?= is (animal))/) ;
result ["cat", "cat", "animal"]
// we got extra cat in above example so removing another grouping
"cat is animal".match(/cat(?= is (animal))/) ;
result ["cat", "animal"]
- Gaurav
9
在复杂的正则表达式中,你可能会遇到一种情况,即希望使用大量组,其中一些用于重复匹配,一些用于提供回溯引用。默认情况下,匹配每个组的文本将加载到回溯引用数组中。当我们有很多组,并且只需要能够从回溯引用数组中引用其中一些时,我们可以覆盖此默认行为,告诉正则表达式某些组仅用于重复处理,并且不需要被捕获和存储在回溯引用数组中。
- Jack Peng
7
让我举一个地理坐标的例子,下面匹配了两个组
Latitude,Longitude
([+-]?\d+(?:\.\d+)?),([+-]?\d+(?:\.\d+)?)
让我们取一个坐标点 ([+-]?\d+(?:\.\d+)?)
坐标可以是整数,比如 58,也可以是小数,比如 58.666。因此,可选的(.666)第二部分 (\.\d+)? 被提及。
(...)? - for optional
但是它被括号包围,这将成为另一组匹配。我们不希望有两次匹配,一次是对于58,另一次是对于.666,我们需要一个匹配的纬度。这就是非捕获组(?:)。
使用非捕获组[+-]?\d+(?:\.\d+)?,58.666和58都是单个匹配。
- Kanagavelu Sugumar
6
(?: ... ) 表示一个组 ( ... ) 但不捕获匹配数据。它比标准的捕获组要高效得多。当你想要分组但不需要以后重用时,可以使用它。@Toto
- user8998146
5
这非常简单,我们可以通过一个简单的日期示例来理解,假设日期为2019年1月1日或2019年5月2日或其他任何日期,我们只想将其转换为dd/mm/yyyy格式,不需要月份的名称(例如January或February),因此为了捕获数字部分而不是(可选)后缀,您可以使用非捕获组。
所以正则表达式应该是:
([0-9]+)(?:January|February)?
就是这么简单。
- Naved Ahmad
4
我来翻译一下。关于IT技术,有一个需要注意的问题:在使用捕获变量时,一定要检查匹配是否成功。
如果匹配失败,那么捕获变量如$1等都是无效的,并且它们也不会被清除。
#!/usr/bin/perl
use warnings;
use strict;
$_ = "bronto saurus burger";
if (/(?:bronto)? saurus (steak|burger)/)
{
print "Fred wants a $1";
}
else
{
print "Fred dont wants a $1 $2";
}
在上面的例子中,为了避免在
$1中捕获bronto,使用了(?:)。如果匹配成功,则
$1将被作为下一个分组模式所捕获。因此,输出结果如下:
Fred wants a burger
如果您不想保存匹配结果,这将非常有用。
- Harini
3
打开你的 Google Chrome 开发者工具,然后切换到控制台选项卡,并输入以下内容:
"Peace".match(/(\w)(\w)(\w)/)
运行它,你会看到:
["Pea", "P", "e", "a", index: 0, input: "Peace", groups: undefined]
JavaScript的RegExp引擎捕获三个组,索引为1、2、3的项。现在使用非捕获标记来查看结果。
"Peace".match(/(?:\w)(\w)(\w)/)
结果如下:
["Pea", "e", "a", index: 0, input: "Peace", groups: undefined]
这很明显是非捕获组。
- AmerllicA
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接