非捕获组,即(?:)在正则表达式中是如何使用的?它们有什么好处?
正则表达式中的非捕获组是什么?
2424
- never_had_a_name
1
70这个问题已被添加到 Stack Overflow 正则表达式 FAQ 中的 "分组" 部分。 - aliteralmind
18个回答
2989
让我用一个例子来解释。
考虑以下文本:
http://stackoverflow.com/
https://stackoverflow.com/questions/tagged/regex
现在,如果我对它应用下面的正则表达式...
(https?|ftp)://([^/\r\n]+)(/[^\r\n]*)?
…我将会得到以下结果:
Match "http://stackoverflow.com/"
Group 1: "http"
Group 2: "stackoverflow.com"
Group 3: "/"
Match "https://stackoverflow.com/questions/tagged/regex"
Group 1: "https"
Group 2: "stackoverflow.com"
Group 3: "/questions/tagged/regex"
但是我不关心协议——我只想要URL的主机名和路径。所以,我将正则表达式更改为包含非捕获组(?:)。
(?:https?|ftp)://([^/\r\n]+)(/[^\r\n]*)?
现在,我的结果看起来像这样:
Match "http://stackoverflow.com/"
Group 1: "stackoverflow.com"
Group 2: "/"
Match "https://stackoverflow.com/questions/tagged/regex"
Group 1: "stackoverflow.com"
Group 2: "/questions/tagged/regex"
看到了吗?第一组没有被捕获。解析器用它来匹配文本,但最终结果中会忽略它。
编辑:
根据要求,让我尝试解释一下组。
嗯,组有很多用途。它们可以帮助您从更大的匹配中提取精确的信息(这些信息也可以命名),让您重新匹配以前匹配过的组,并可用于替换。让我们来试试几个例子,好吗?
想象一下你有一些 XML 或 HTML(注意,正则表达式可能不是最好的工具,但作为示例很好)。你想解析标签,所以你可以做这样的事情(我添加了空格以便更容易理解):
\<(?<TAG>.+?)\> [^<]*? \</\k<TAG>\>
or
\<(.+?)\> [^<]*? \</\1\>
让我们现在尝试一些替换。考虑以下文本:
Lorem ipsum dolor sit amet consectetuer feugiat fames malesuada pretium egestas.
\b(\S)(\S)(\S)(\S*)\b
这个正则表达式匹配至少有3个字符的单词,并使用分组来分离前三个字母。结果如下:
Match "Lorem"
Group 1: "L"
Group 2: "o"
Group 3: "r"
Group 4: "em"
Match "ipsum"
Group 1: "i"
Group 2: "p"
Group 3: "s"
Group 4: "um"
...
Match "consectetuer"
Group 1: "c"
Group 2: "o"
Group 3: "n"
Group 4: "sectetuer"
...
所以,如果我们应用替换字符串:
$1_$3$2_$4
... 我们想使用第一组, 添加下划线, 再使用第三组, 接着使用第二组, 再添加另一个下划线, 最后使用第四组. 最终的字符串将会像以下这样.
L_ro_em i_sp_um d_lo_or s_ti_ a_em_t c_no_sectetuer f_ue_giat f_ma_es m_la_esuada p_er_tium e_eg_stas.
你也可以使用命名分组进行替换,使用${name}。
如果想要尝试正则表达式,请推荐http://regex101.com/,它提供了很多关于正则表达式工作方式的详细信息;它还提供了几个可选择的正则表达式引擎。
- Ricardo Nolde
9
4传统的(捕获)分组在对结果执行替换操作时非常有用。以下是一个例子,我正在获取以逗号分隔的姓和名,然后翻转它们的顺序(感谢命名分组)... http://regexhero.net/tester/?id=16892996-64d4-4f10-860a-24f28dad7e30 - Steve Wortham
6还可以指出,当使用正则表达式作为分隔符时,非捕获组是非常有用的: "Alice and Bob" -split "\s+(?:and|or)\s+" - Yevgeniy
13将非捕获组(?:)与正向先行断言(?=)和负向先行断言(?!)进行比较解释是很有趣的。我刚开始学习正则表达式,但据我所知,非捕获组用于匹配并“返回”它们匹配的内容,但是这个“返回值”不会被“存储”以供反向引用。另一方面,正向先行断言和负向先行断言不仅不会被“存储”,而且它们也不属于匹配的一部分,它们只是断言某些内容会匹配,但如果我没弄错的话,它们的“匹配值”会被忽略…(我的理解大致正确吗?) - Christian
9[] 表示一个字符集合;
[123] 匹配集合中的任意一个字符,只匹配一次;
[^123] 匹配除集合中的字符以外的任意一个字符,只匹配一次;
[^/\r\n]+ 匹配一个或多个与 /、\r、\n 不同的字符。 - Ricardo Nolde
1同样重要的是,具有非捕获组
(?: 的正则表达式比具有捕获组 '(' 的相同正则表达式快得多。因此,当我们不需要捕获组时,应该使用非捕获组。 - luke显示剩余4条评论
243
使用捕获组可以组织和解析表达式。非捕获组具有第一个好处,但不具备第二个的开销。例如,您仍然可以说非捕获组是可选的。
假设您想匹配数值文本,但某些数字可能以1st、2nd、3rd、4th等形式书写。如果您想捕获数字部分但不包括(可选的)后缀,则可以使用非捕获组。
([0-9]+)(?:st|nd|rd|th)?
这将匹配形式为1、2、3...或形式为1st、2nd、3rd等的数字,但它只会捕获数字部分。
- Bill the Lizard
2
2没有非捕获组,我可以这样做:
([0-9]+)(st|nd|rd|th)??有了\1,我就有了数字,不需要?:。顺便问一下,末尾的?是什么意思? - Timo1在这种情况下,末尾的
? 表示捕获组是可选的。 - Pillager225157
?: 用于分组表达式,但不想将其保存为字符串中匹配/捕获的部分。
例如,可以使用它来匹配IP地址:
/(?:\d{1,3}\.){3}\d{1,3}/
请注意,我不关心保存前三个八位组,但是(?:...)分组允许我缩短正则表达式而不会产生捕获和存储匹配的开销。
- RC.
2
17对于不熟悉的读者:这可以匹配一个IP地址,但也可以匹配无效的IP地址。用于验证IP地址的表达式会更加复杂。所以,请不要使用此方法来验证IP地址。 - Francisco Zarabozo
只是补充一下,这意味着您有1到3个数字,后跟一个“。”,正好三次,然后再跟1到3个数字。 - Amber
68
历史背景:
非捕获组的存在可以通过使用括号来解释。
考虑表达式 (a|b)c 和 a|bc,由于串联优先级高于 |,这些表达式表示两种不同的语言(分别为 {ac, bc} 和 {a, bc})。
然而,括号也可以用作匹配组(就像其他答案中所解释的一样……)。
当您想要括号但不捕获子表达式时,您使用非捕获组。在本例中,使用(?:a|b)c。
- user2369060
1
只回答暗示为什么我们需要分组。+1 - Behnam Esmaili
55
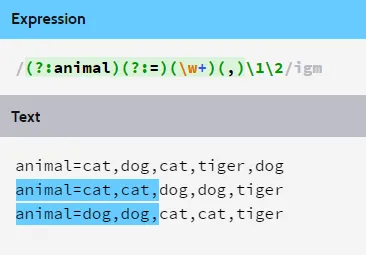
让我用一个例子来说明:
正则表达式代码: (?:animal)(?:=)(\w+)(,)\1\2
搜索字符串:
第1行 - animal=cat,dog,cat,tiger,dog
第2行 - animal=cat,cat,dog,dog,tiger
第3行 - animal=dog,dog,cat,cat,tiger
(?:animal) --> 非捕获组1
(?:=)--> 非捕获组2
(\w+)--> 捕获组1
(,)--> 捕获组2
\1 --> 捕获组1的结果,即第1行是猫,第2行是猫,第3行是狗。
\2 --> 捕获组2的结果,即逗号(,)
因此,在这个代码中,通过给出\1和\2,我们可以在代码后面调用或重复捕获组1和2的结果。
按照代码顺序,(?:animal) 应该是组1,(?:=) 应该是组2 以此类推..
但是,通过使用?:,我们使匹配组成为非捕获的(其不计算在匹配的组中,因此分组编号从第一个捕获组开始而不是非捕获组),这样就无法在代码后面调用重复匹配组(?:animal)的结果。
希望这解释了非捕获组的用法。
- shekhar gehlot
1
(?:animal=)(\w+)(,)\1\2 因为 (?:animal)(?:=) 的匹配结果只有 animal=,所以没有必要有两个非捕获组。另一方面,如果你想要捕获第一个单词,(animal)(?:=)(\w+)(,)\2\3 可以重复第一个动物和逗号进行相同的匹配。例如,如果你的文本还包括蔬菜和矿物质,你可以使用 (?:\w+)(?:=)(\w+)(,)\2\3,然后你就可以将等于号前面的类别或者其他名字放在第一组中。在这种情况下,非捕获组将仅是 (?:=),它将被丢弃。 - Jeter-work47
这会使得这个组成为非捕获组,也就是说,与该组匹配的子字符串将不会被包含在捕获列表中。以下是 Ruby 的示例来说明差异:
"abc".match(/(.)(.)./).captures #=> ["a","b"]
"abc".match(/(?:.)(.)./).captures #=> ["b"]
- sepp2k
2
为什么我们不能在这里使用"abc".match(/.(.)./).captures呢? - PRASANNA SARAF
1@PRASANNASARAF 当然可以。代码的重点是展示
(?:) 不会产生捕获,而不是演示 (?:) 的有用示例。当您想要对非原子子表达式应用量词或者想要限制 | 的范围时,(?:) 是很有用的,但您不想捕获任何内容。 - sepp2k23
捕获组可以在正则表达式中后续使用来进行“或”匹配,或者用于替换操作。使用非捕获组可以将该组从上述两种情况中排除。
如果您尝试捕获多个不同的内容并且其中有一些组不想捕获,那么非捕获组就非常有用。
这基本上就是它们存在的原因。当您学习有关组的知识时,还应该学习原子组,它们可以做很多事情!还有查找组,但它们更加复杂,用得不太多。
以下是一个捕获组的后续使用示例(反向引用):
<([A-Z][A-Z0-9]*)\b[^>]*>.*?</\1> [ 查找一个xml标签(不支持ns) ]
([A-Z][A-Z0-9]*) 是一个捕获组(在此示例中为标签名称)
正则表达式中后续出现的 \1 表示仅会匹配第一个组(即([A-Z][A-Z0-9]*)组)中匹配到的相同文本(在此示例中,它是用来匹配结束标签)。
- Bob Fincheimer
2
1你能否给一个简单的例子来说明如何使用它来匹配OR? - never_had_a_name
1我的意思是,您可以在以后使用它进行匹配,也可以在替换中使用它。那个句子中的“or”只是为了向您展示捕获组有两种用途。 - Bob Fincheimer
22
一个简单的答案
使用它们来确保发生几种可能性之一的地方 (?:one|two) 或可选短语 camp(?:site)? ,或者在一般情况下,您想要建立一个组/短语/部分而无需特别引用它。
它们可以将捕获的组数保持最少。
- Cyberwip
19
简述 非捕获组,顾名思义,是正则表达式中你不希望包含在匹配结果中的部分,?: 则是定义一个非捕获组的方法。
假设你有一个邮箱地址 example@example.com。下面的正则表达式将会创建两个组,一个是id部分,另一个是@example.com部分。(\p{Alpha}*[a-z])(@example.com) 。为了简单起见,我们提取整个域名,包括@字符。
现在假设,你只需要该地址的id部分。你需要做的就是获取匹配结果的第一个用括号()包围的组,这时你就可以使用非捕获组的语法,即?:。所以,这个正则表达式(\p{Alpha}*[a-z])(?:@example.com) 将只返回该邮箱地址的id部分。
- Aaron S
3
3在我看到你的回答之前,我一直很难理解这里所有的答案! - metablaster
2非捕获组包含在匹配中。但它们不被捕获。这意味着当您列出捕获的组时,非捕获组不在该列表中。它们也无法在表达式后面引用。例如,如果您不关心域名,可以使用
(\w+)@\w.\w.*,只捕获ID部分。但是,如果必须是example.com,并且您想要丢弃example.com,因为所有良好的匹配都有它,那么您将使用非捕获组。(\w+)@(?:example.com)。 - Jeter-work1@Jeter-work在这里的评论本身就足够简洁和易读,应该作为对问题的回答! - saxbophone
15
我不能评论顶部答案来说这个:我想补充一个明确的观点,这个观点只在顶部答案中隐含:
非捕获组 (?:...) 不会从原始完全匹配中删除任何字符,它只是将正则表达式在视觉上重新组织给程序员。
要访问正则表达式的特定部分而不包括多余字符,您总是需要使用 .group()。
非捕获组 (?:...) 不会从原始完全匹配中删除任何字符,它只是将正则表达式在视觉上重新组织给程序员。
要访问正则表达式的特定部分而不包括多余字符,您总是需要使用 .group()。
- Scott Anderson
1
3你提供了其他回答中缺失的最重要的提示。我尝试了它们中的所有示例,并用最恰当的词语表达着感受,因为我没有得到期望的结果。只有你的帖子向我展示了我哪里出了错。 - Seshadri R
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接