我有一个由排列集合组成的数组,想要移除同构排列。
我们有S个排列集合,每个集合包含K个排列,每个排列由N个元素组成。目前我将它保存为一个数组int pset[S][K][N],其中S、K和N是固定的,N大于K。
如果存在一个置换P,可以将A中的元素转换为B中的元素(例如,如果a是集合A中的元素,则P(a)是集合B中的元素),则称两个排列集合A和B同构。在这种情况下,我们可以说P使A和B同构。
我的当前算法是:
1. 我们选择所有满足i < j的对s1 = pset[i]和s2 = pset[j]。 2. 从所选集合(s1和s2)中的每个元素都被编号为1到K。这意味着每个元素可以表示为s1[i]或s2[i],其中0 < i < K+1。 3. 对于每个K元素的排列T,我们执行以下操作: - 找到置换R,使得R(s1[1]) = s2[1]。 - 检查R是否是一种使s1和T(s2)同构的排列,其中T(s2)是集合s2的元素(排列)的重新排列,因此我们只需检查R(s1[i]) = s2[T[i]],其中0 < i < K+1。 - 如果不是,则我们继续下一个排列T。
我们有S个排列集合,每个集合包含K个排列,每个排列由N个元素组成。目前我将它保存为一个数组int pset[S][K][N],其中S、K和N是固定的,N大于K。
如果存在一个置换P,可以将A中的元素转换为B中的元素(例如,如果a是集合A中的元素,则P(a)是集合B中的元素),则称两个排列集合A和B同构。在这种情况下,我们可以说P使A和B同构。
我的当前算法是:
1. 我们选择所有满足i < j的对s1 = pset[i]和s2 = pset[j]。 2. 从所选集合(s1和s2)中的每个元素都被编号为1到K。这意味着每个元素可以表示为s1[i]或s2[i],其中0 < i < K+1。 3. 对于每个K元素的排列T,我们执行以下操作: - 找到置换R,使得R(s1[1]) = s2[1]。 - 检查R是否是一种使s1和T(s2)同构的排列,其中T(s2)是集合s2的元素(排列)的重新排列,因此我们只需检查R(s1[i]) = s2[T[i]],其中0 < i < K+1。 - 如果不是,则我们继续下一个排列T。
这个算法运行速度非常慢:第一步的时间复杂度是O(S^2),每次循环检查排列T所需时间复杂度为O(K!),寻找R所需的时间复杂度是O(N^2),检查R是否与使s1和s2同构的排列匹配所需的时间复杂度为O(K*N) - 因此总时间复杂度是O(S^2 * K! * N^2)。
问题:我们能使它更快吗?
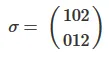
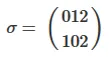
K!乘法器改进为多项式:对于每一个 i 和 j,找到置换 R 使得 R(s1[i]) = s2[j],标记 j 为 "used",然后对于每个 k != i,找到一个未被标记的 m,使得 R(s1[k]) = s2[m],并标记 m 为 "used"。如果对于某些 i 和 j,您可以 "标记" 所有从 1 到 K 的m,那么 R 会使 s1 和 s2 同构。 - KolmarPa被定义为一个由p和a组成的置换。 - vsoftcoA\isomorphic B?还是在共轭下,即B = p A inverse(p)? - vsoftco