我正在寻找一个算法,它给定了一组数字(例如 1 2 3)和一个索引(例如 2),将会按照字典顺序获取这些数字的第二个排列。例如,在这种情况下,该算法将返回 1 3 2。
寻找数值排列的算法,给定字典序索引
6
- Eddie Dovzhik
3
你目前尝试了什么?一个天真的方法是生成所有排列,按字典顺序排序,然后选择第n个。 - Gumbo
3提示:首先找到一种算法来确定第n个排列的第一个数字。 - Raymond Chen
4相关提示:尝试搜索“阶乘进制”和“Lehmer编码”。 - Nemo
4个回答
22
这里是一个Scala的样例解决方案,我将详细解释:
/**
example: index:=15, list:=(1, 2, 3, 4)
*/
def permutationIndex (index: Int, list: List [Int]) : List [Int] =
if (list.isEmpty) list else {
val len = list.size // len = 4
val max = fac (len) // max = 24
val divisor = max / len // divisor = 6
val i = index / divisor // i = 2
val el = list (i)
el :: permutationIndex (index - divisor * i, list.filter (_ != el)) }
由于Scala并不是那么出名,我认为我需要解释一下算法的最后一行,除此之外,它本身就相当容易理解。
el :: elist
从元素el和列表elist构建一个新的列表。Elist是一个递归调用。
list.filter (_ != el)
这是一个不包含元素el的列表。
使用一个小列表进行全面测试:
(0 to fac (4) - 1).map (permutationIndex (_, List (1, 2, 3, 4))).mkString ("\n")
通过两个例子来测试一个更大的列表的速度:
scala> permutationIndex (123456789, (1 to 12).toList)
res45: List[Int] = List(4, 2, 1, 5, 12, 7, 10, 8, 11, 6, 9, 3)
scala> permutationIndex (123456790, (1 to 12).toList)
res46: List[Int] = List(4, 2, 1, 5, 12, 7, 10, 8, 11, 9, 3, 6)
这个方法可以在一个5年前的笔记本电脑上快速生成结果。对于一个包含12个元素的列表,有479 001 600种排列组合,但是对于100或1000个元素,这个解决方案仍然应该能够快速工作 - 您只需要使用BigInt作为索引。
它是如何工作的?我制作了一张图形来表示示例,一个(1, 2, 3, 4)列表和一个索引为15:
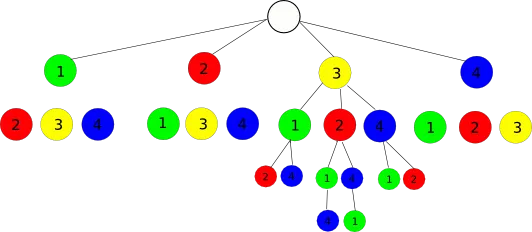
一个包含4个元素的列表会产生4!种排列组合(=24)。我们从0到4!-1中选择任意一个索引,比如说15。
我们可以用树状图将所有排列组合可视化,以1..4中的第一个节点开始。我们将4!除以4,看到每个第一个节点都指向6个子树。如果我们将索引15除以6,得到的结果是2,零基索引中位置为2的元素的值为3。因此第一个节点是3,剩下的列表是(1, 2, 4)。下表显示了15如何导致数组/列表/其他对象中索引为2的元素:
0 1 2 3 4 5 | 6 ... 11 | 12 13 14 15 16 17 | 18 ... 23
0 | 1 | 2 | 3
| | 0 1 2 3 4 5 |
我们现在从单元格的第一个元素12(12…17)中减去最后3个元素,这些元素有6种可能的排列方式,并查看15如何映射到3。数字3现在导致了数组索引1,这是元素2,因此到目前为止结果是列表(3, 2,...)。
| 0 1 | 2 3 | 4 5 |
| 0 | 1 | 3 |
| 0 1 |
再次减去2,最终剩下2个元素和2种排列,索引为(0,3),映射到值为(1,4)。我们可以看到,第二个元素属于顶部的15,映射到值为3,最后一步的剩余元素是另一个元素:
| 0 | 1 |
| 0 | 3 |
| 3 | 0 |
我们的结果是List(3, 2, 4, 1)或索引(2, 1, 3, 0)。按顺序测试所有索引表明它们按顺序产生所有排列。
- user unknown
7
这里有一个简单的解决方案:
from math import factorial # python math library
i = 5 # i is the lexicographic index (counting starts from 0)
n = 3 # n is the length of the permutation
p = range(1, n + 1) # p is a list from 1 to n
for k in range(1, n + 1): # k goes from 1 to n
f = factorial(n - k) # compute factorial once per iteration
d = i // f # use integer division (like division + floor)
print(p[d]), # print permuted number with trailing space
p.remove(p[d]) # delete p[d] from p
i = i % f # reduce i to its remainder
输出:
3 2 1
如果p是一个列表,则时间复杂度为O(n^2),如果p是哈希表且factorial已经预先计算,则摊销时间复杂度为O(n)。
- cyborg
2
1虽然这是最佳答案,但是在 Python 中 list.remove() 不是 O(1),因此此解决方案的时间复杂度为 Θ(n^2)。通过使用二叉搜索树而不是列表,可以将时间复杂度降至 Θ(n log n)。前提是factorial()的时间复杂度是O(1)(实际上它不是)。 - soulcheck
即使使用高效的数据结构,这个问题的复杂度仍然超过O(n^2)。除法和乘法的计算代价非常昂贵。请参考:https://en.wikipedia.org/wiki/Computational_complexity_of_mathematical_operations - Quantum Guy 123
1
提到的文章链接:http://penguin.ewu.edu/~trolfe/#Shuffle
/* Converting permutation index into a permutation
* From code accompanying "Algorithm Alley: Randomized Shuffling",
* Dr. Dobb’s Journal, Vol. 25, No. 1 (January 2000)
* http://penguin.ewu.edu/~trolfe/#Shuffle
*
* Author: Tim Rolfe
* RolfeT@earthlink.net
* http://penguin.ewu.edu/~trolfe/
*/
#include <stdio.h>
#include <stdlib.h>
// https://dev59.com/E1_Va4cB1Zd3GeqPT38s
// Invert the permutation index --- generate what would be
// the subscripts in the N-dimensional array with dimensions
// [N][N-1][N-2]...[2][1]
void IndexInvert(int J[], int N, int Idx)
{ int M, K;
for (M=1, K=N-1; K > 1; K--) // Generate (N-1)!
M *= K;
for ( K = 0; M > 1; K++ )
{ J[K] = Idx / M; // Offset in dimension K
Idx = Idx % M; // Remove K contribution
M /= --N; // next lower factorial
}
J[K] = Idx; // Right-most index
}
// Generate a permutation based on its index / subscript set.
// To generate the lexicographic order, this involves _shifting_
// characters around rather than swapping. Right-hand side must
// remain in lexicographic order
void Permute (char Line[], char first, int N, int Jdx[])
{ int Limit;
Line[0] = first;
for (Limit = 1; Limit < N; Limit++)
Line[Limit] = (char)(1+Line[Limit-1]);
for (Limit = 0; Limit < N; Limit++)
{ char Hold;
int Idx = Limit + Jdx[Limit];
Hold = Line[Idx];
while (Idx > Limit)
{ Line[Idx] = Line[Idx-1];
Idx--;
}
Line[Idx] = Hold;
}
}
// Note: hard-coded to generate permutation in the set [abc...
int main(int argc, char** argv)
{ int N = argc > 1 ? atoi(argv[1]) : 4;
char *Perm = (char*) calloc(N+1, sizeof *Perm);
int *Jdx = (int*) calloc(N, sizeof *Jdx);
int Index = argc > 2 ? atoi(argv[2]) : 23;
int K, Validate;
for (K = Validate = 1; K <= N; K++)
Validate *= K;
if (Index < 0 || Index >= Validate)
{ printf("Invalid index %d: %d! is %d\n", Index, N, Validate);
return -1; // Error return
}
IndexInvert(Jdx, N, Index);
Permute (Perm, 'a', N, Jdx);
printf("For N = %d, permutation %d in [0..%d] is %s\n",
N, Index, Validate-1, Perm);
return 0; // Success return
}
- Timothy Rolfe
0
由于您没有指定想要使用哪种语言,这里有一个Python实现。
您只需要获取序列的第n个元素。
算法的一个想法可能是生成一个表示输入序列的笛卡尔积的序列,并迭代它,跳过具有重复元素的项。
请注意,这可能不是最快的方法,但绝对是一种简单的方法。要了解更快的方法,请参阅cyborg的答案。
- soulcheck
1
1这个解决方案需要O(k!)的时间(其中k是排列的长度),而O(k)是随时可用的。 - cyborg
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接