我在磁盘上存储了约700个矩阵,每个矩阵大约有70k行和300列。我需要相对快速地加载这些矩阵的部分数据,每个矩阵中大约1k行,加载到我在内存中的另一个矩阵中。我发现使用内存映射的方式是最快的方法,最初我可以在约0.02秒内加载1k行数据。然而,性能并不稳定,有时候,加载每个矩阵需要长达1秒的时间!我的代码大致如下:
通过逐行计时,我发现随着时间推移,明显是最后一行减速。
target = np.zeros((7000, 300))
target.fill(-1) # allocate memory
for path in os.listdir(folder_with_memmaps):
X = np.memmap(path, dtype=_DTYPE_MEMMAPS, mode='r', shape=(70000, 300))
indices_in_target = ... # some magic
indices_in_X = ... # some magic
target[indices_in_target, :] = X[indices_in_X, :]
通过逐行计时,我发现随着时间推移,明显是最后一行减速。
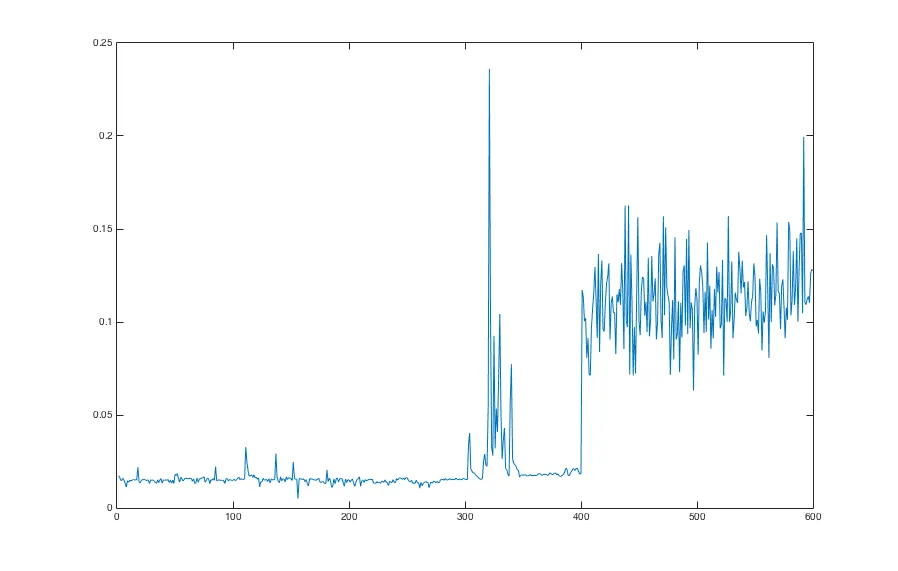
更新:绘制负载时间图表得到不同的结果。有一次它看起来像这样,即退化不是逐渐的,而是在确切的400个文件后跳跃。这可能是某种操作系统限制吗?
但另一次它看起来完全不同:
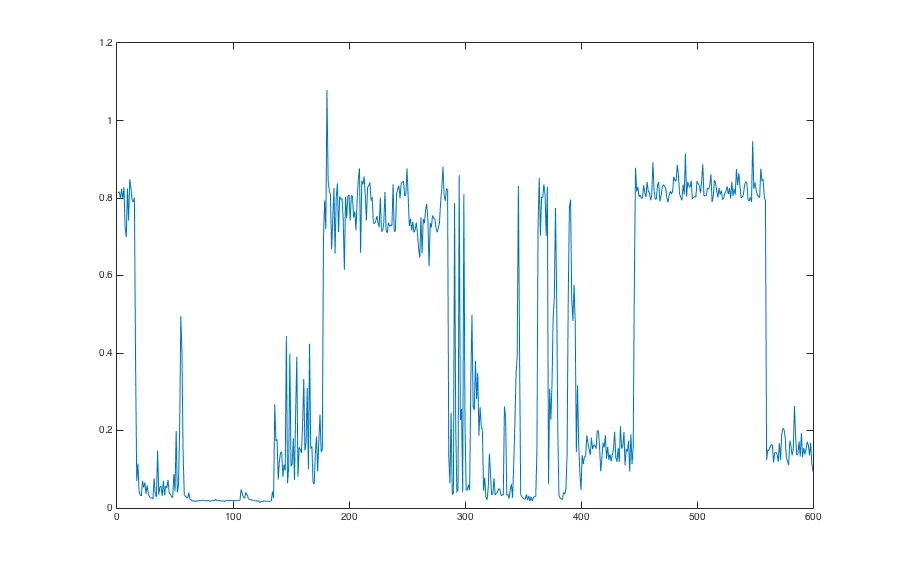
经过更多测试运行后,似乎第二个图表更符合性能发展的典型情况。
此外,我尝试了循环结束后的 del X,但没有任何影响。访问Python中底层的mmap,即X._mmap.close(),也没有效果。
对于为什么会出现性能不一致的想法?有没有更快的替代方法来存储和检索这些矩阵?
mmap文件没有被关闭。这只是一个猜测,但我建议在循环结束时添加del X。np.memmap的代码是可读的Python代码,但mmap.mmap的代码不是。 - hpauljindices_in_X是np.arange(1000)还是np.random.shuffe(np.arange(0, 70000, 70))很重要。此外,请尝试使计时独立于操作系统文件缓存效果:http://unix.stackexchange.com/q/87908 - user2379410indices_in_X和indices_in_target进行排序,我认为这稍微提高了基线,但是那些看似随机的退化补丁仍然存在。不幸的是,我正在使用共享服务器,并没有sudo权限,因此我无法清除任何缓存。 - fabian789