我有一堆数据(每个测量系列大约有10,000到50,000个值),我希望自动识别这些值分布密度估计中的局部最大值/最小值。实际上,我假设通常应该有两个峰值,由一个低谷隔开,我想找到这个低谷,以便将数据分成两部分进行进一步处理。如果可能的话,我也想知道峰值的位置。
由于密度估计可能包含非常小的局部变化,我希望能够调整“灵敏度”。到目前为止,我能找到的最好的解决方案是@Tommy的解决方案:https://dev59.com/-mw15IYBdhLWcg3wFHzf#6836924 这里是一个例子:
library(ggplot2)
d <- density(faithful$eruptions, bw = "sj")
loc.max <- d$x[localMaxima(d$y)]
ggplot(faithful, aes(eruptions)) + geom_density(adjust=1/2) +
geom_vline(x=loc.max, col="red") +
xlab("Measured values")
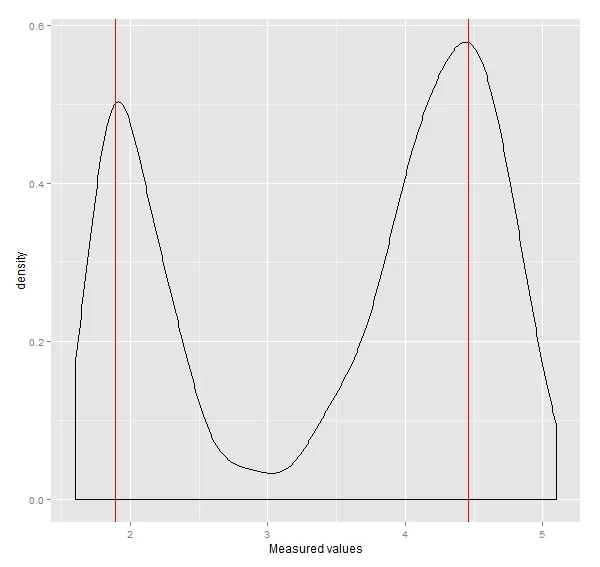
现在,我的数据噪声很大:
d <- density(my.df$Values, bw = "sj")
loc.max <- d$x[localMaxima(d$y)]
ggplot(my.df, aes(Values)) + geom_density(adjust=1/2) +
geom_vline(x=loc.max, col="red") +
xlab("Measured values")
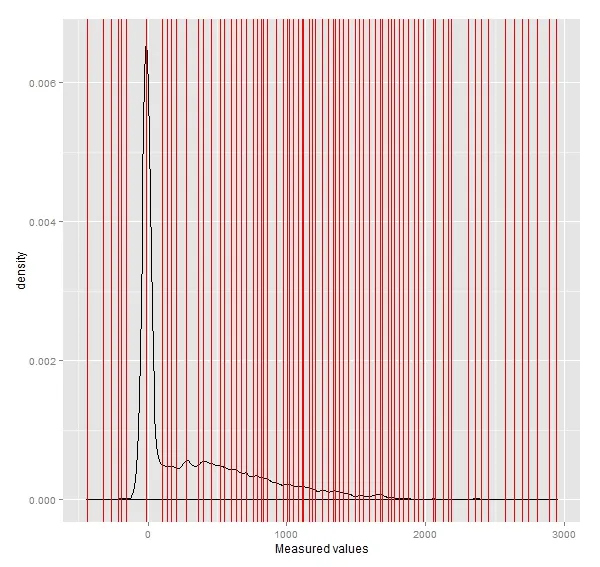
尝试调整参数(注意尾部出现了两个“不需要”的峰值):
d <- density(my.df$Values, bw="nrd", adjust=1.2)
loc.max <- d$x[localMaxima(d$y)]
ggplot(my.df, aes(Values)) + geom_density(adjust=1/2) +
geom_vline(x=loc.max, col="red") +
xlab("Measured values")
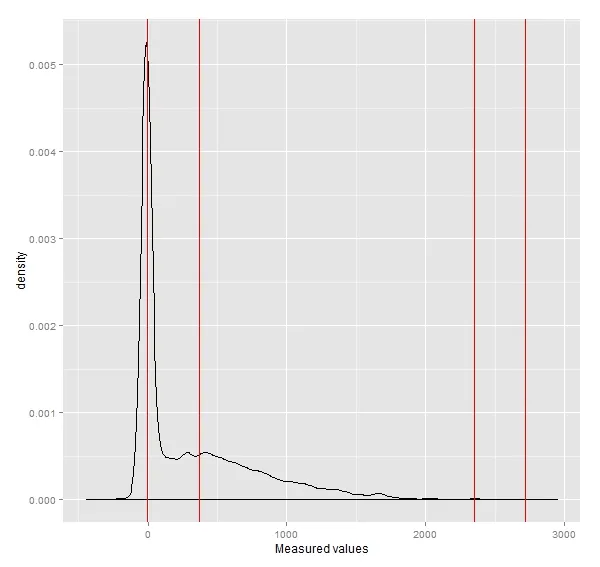
因此,问题是:
1)如何在这样一个嘈杂的数据集中自动识别真实的峰值? 2)如何可靠地找到分隔这些峰值的谷底?