TL;DR: 问题在于选择基准点的策略,使得在这些类型的输入(A型和V型序列)上反复做出错误的选择。这导致快速排序产生高度“不平衡”的递归调用,从而导致算法表现非常糟糕(对于A型序列是二次时间)。
恭喜你,你已经(重新)发现了一种对于选择中间元素作为基准点的快速排序版本而言具有敌对性的输入(或者说是一类输入)。
参考资料:A型序列的一个示例是1 2 3 4 3 2 1,即一个增加、达到中间点后又减少的序列;V型序列的一个示例是4 3 2 1 2 3 4,即一个减少、达到中间最小值后又增加的序列。
请看当你选择中间元素作为A型或V型序列的枢轴时会发生什么。在第一种情况下,当你传递算法A型序列
1 2 ... n-1 n n-1 ... 2 1时,枢轴是数组的最大元素——这是因为A型序列的最大元素是中间元素,而你选择中间元素作为枢轴——并且你将对大小为
0(实际上你的代码不会对
0个元素进行调用)和
n-1的子数组进行递归调用。在对大小为
n-1的子数组进行的下一次调用中,你将选择子数组的最大元素(也就是原始数组的第二大元素)作为枢轴;以此类推。这导致了性能较差,因为运行时间为
O(n)+O(n-1)+...+O(1) = O(n^2),因为在每一步中,你基本上传递了几乎整个数组(除了枢轴),换句话说,递归调用中数组的大小高度不平衡。
以下是A型序列1 2 3 4 5 4 3 2 1的跟踪:
blazs@blazs:/tmp$ ./test
pivot=5
1 2 3 4 1 4 3 2 5
pivot=4
1 2 3 2 1 3 4 4
pivot=3
1 2 3 2 1 3
pivot=3
1 2 1 2 3
pivot=2
1 2 1 2
pivot=2
1 1 2
pivot=1
1 1
pivot=4
4 4
1 1 2 2 3 3 4 4 5
你可以从跟踪中看到,在递归调用时,该算法选择一个
最大的元素(最多可能有两个最大的元素,因此使用不定冠词
a而不是定冠词
the)作为枢轴。这意味着A形序列的运行时间确实为
O(n)+O(n-1)+...+O(1) = O(n^2)。(在技术术语中,A形序列是迫使算法表现不佳的对抗性输入的示例。)
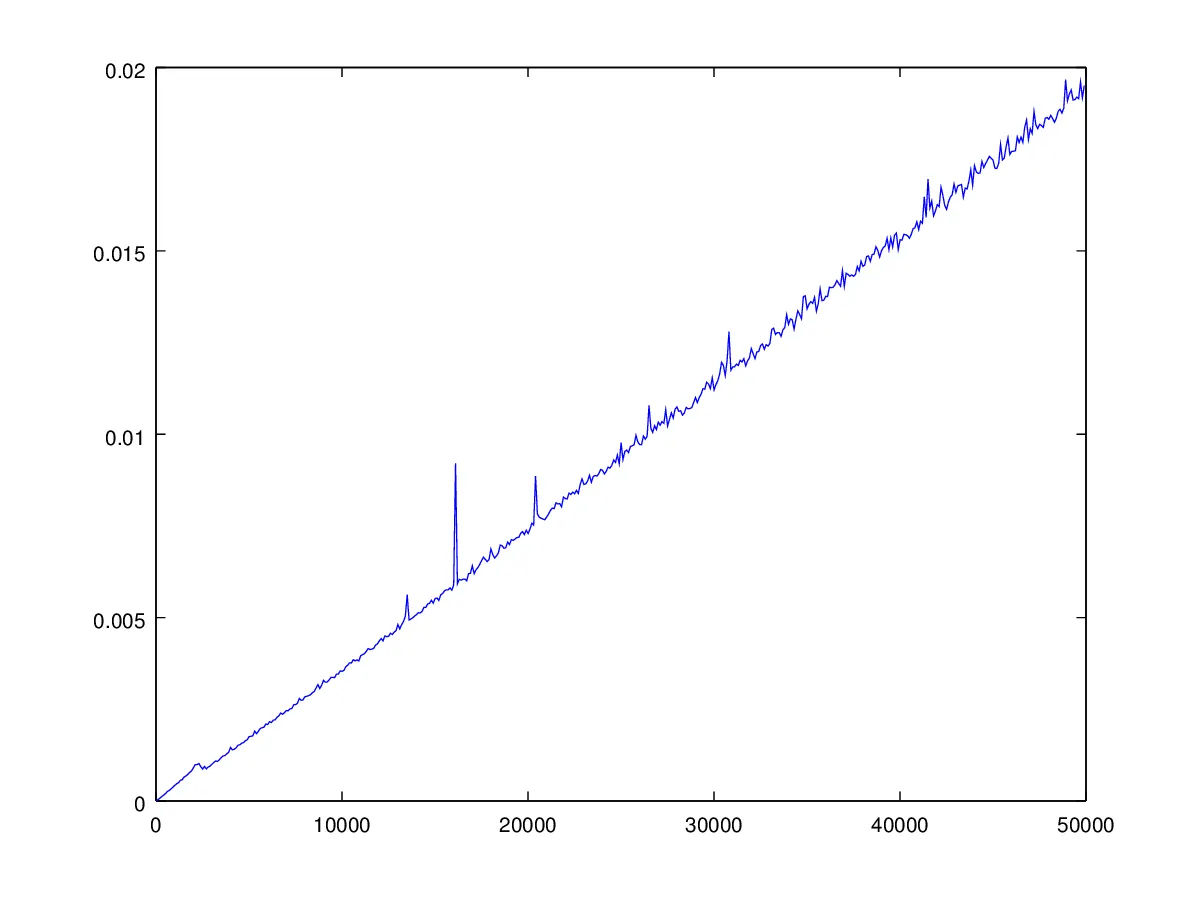
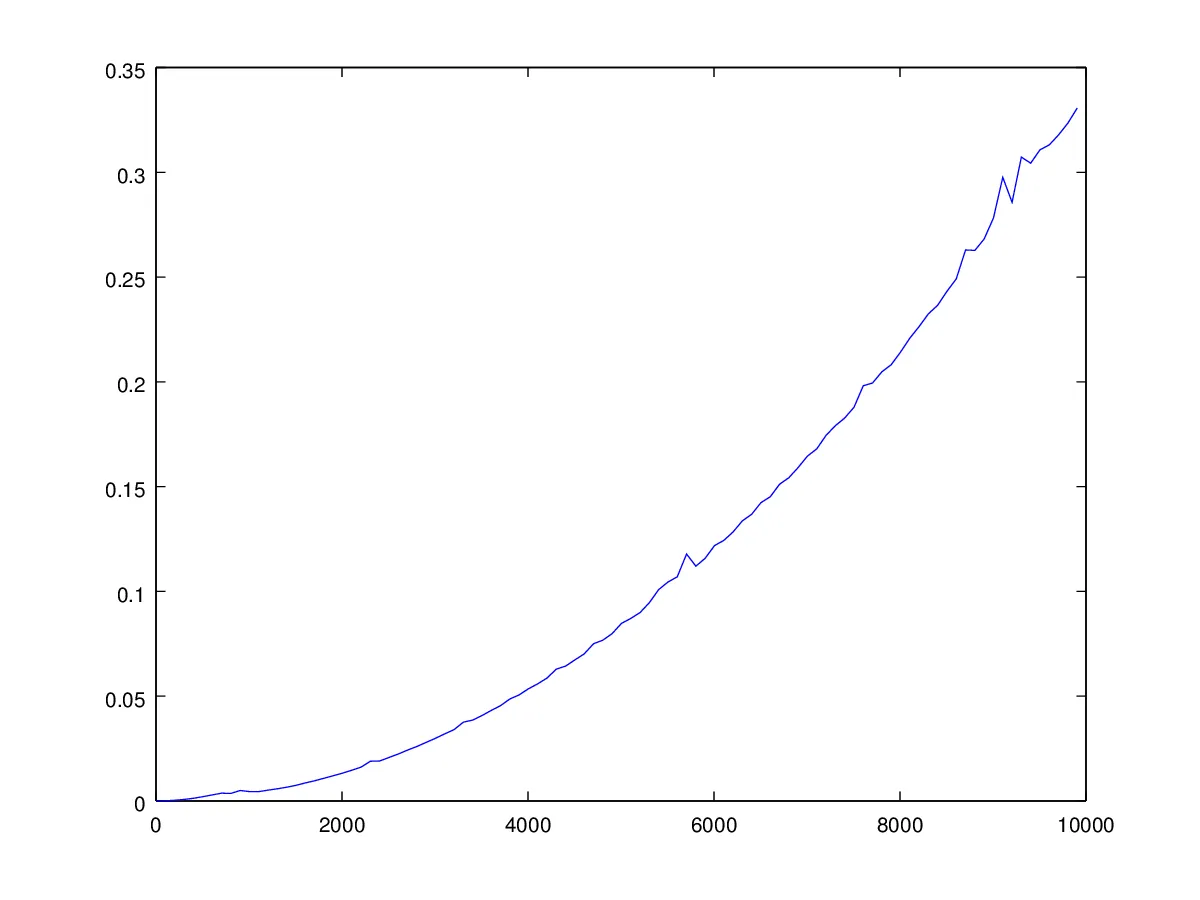
这意味着,如果您绘制“完美”的A形序列的运行时间,其形式为
1 2 3 ... n-1 n n-1 ... 3 2 1
当增加n时,你会看到一个漂亮的二次函数。这是我刚刚为A形序列1 2 ... n-1 n n-1 ... 2 1计算的n=5,105, 205, 305,...,9905的图表:
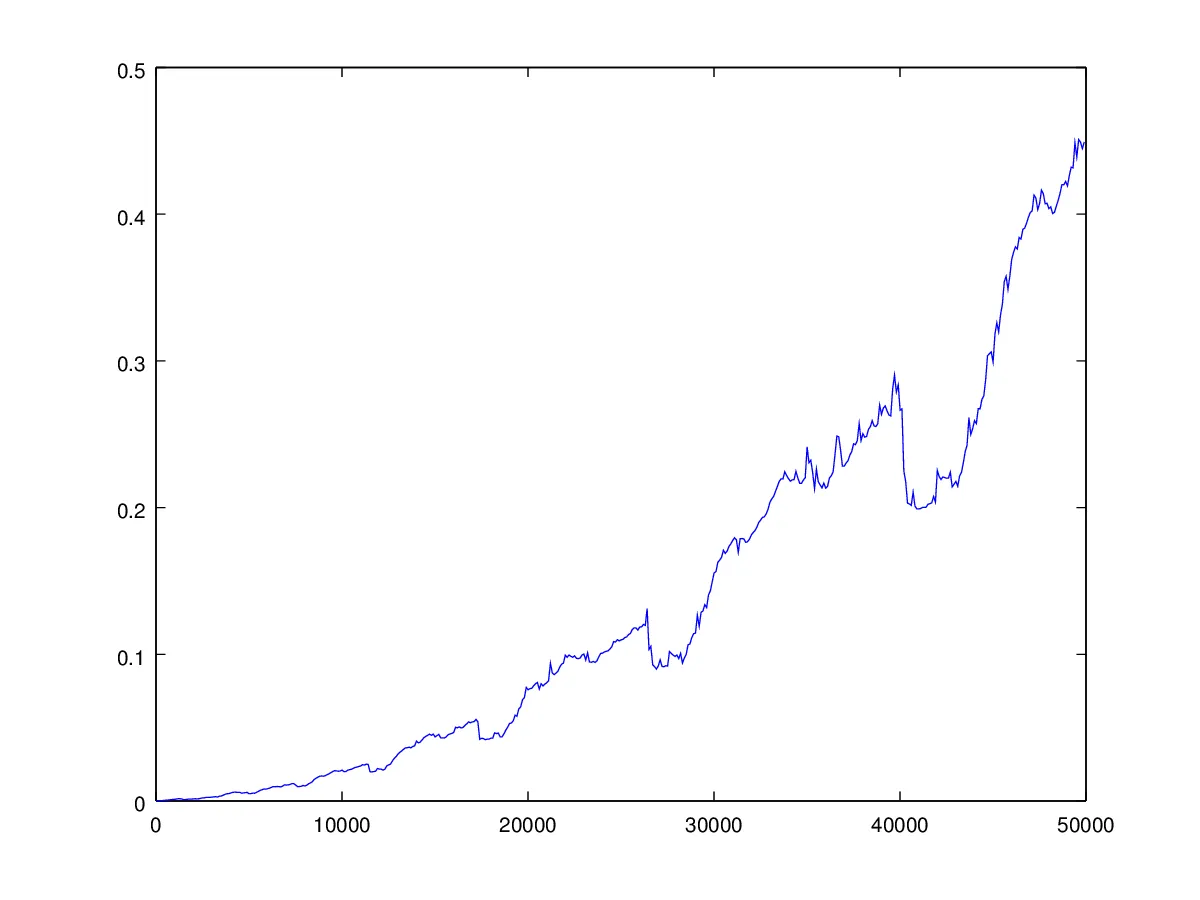
在第二种情况下,当您将V形序列传递给算法时,您选择数组中最小的元素作为枢轴,并因此对大小为
n-1和
0的子数组进行递归调用(实际上,您的代码不会对
0个元素进行调用)。在对大小为
n-1的子数组的下一次调用中,您将选择
最大元素作为枢轴;以此类推。(但您并不总是做出这样糟糕的选择;很难对这种情况做更多解释。)由于类似原因,这会导致性能差。这种情况略微复杂(它取决于您如何执行“移动”步骤)。
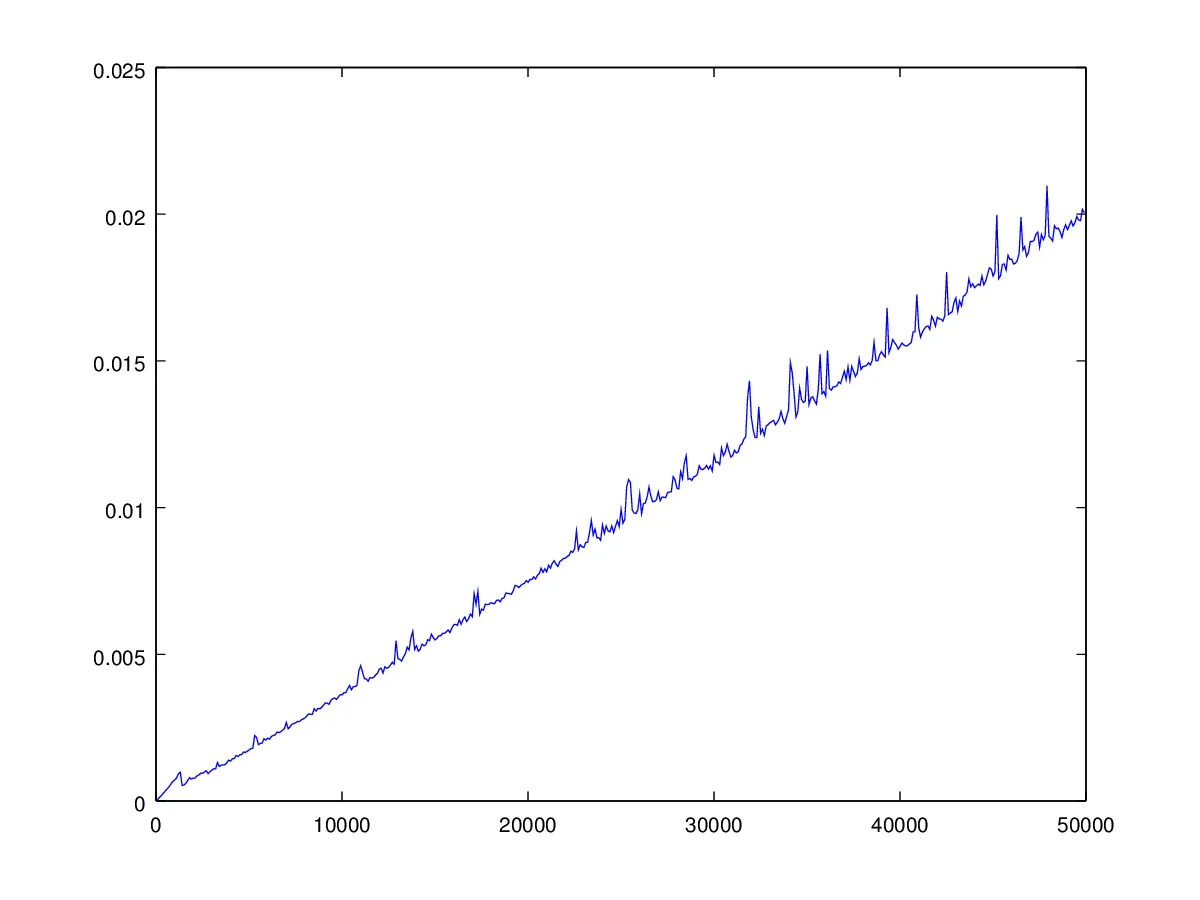
以下是V形序列
n n-1 ... 2 1 2 ... n-1 n(其中
n=5,105,205,...,49905)的运行时间图表。运行时间有些不规则——正如我所说,这更加复杂,因为您并不总是选择最小的元素作为枢轴。图表:
我用来测量时间的代码:
double seconds(size_t n) {
int *tab = (int *)malloc(sizeof(int) * (2*n - 1));
size_t i;
for (i = 0; i < n-1; i++) {
tab[i] = tab[2*n-i-2] = i+1;
}
tab[n-1] = n;
clock_t start = clock();
quicksort(0, 2*n-2, tab);
clock_t finish = clock();
free(tab);
return (double) (finish - start) / CLOCKS_PER_SEC;
}
我将您的代码进行了修改,以便打印算法的“跟踪”,这样您就可以自己操作并深入了解正在发生的事情:
#include <stdio.h>
void print(int *a, size_t l, size_t r);
void quicksort(int l,int p,int *tab);
int main() {
int tab[] = {1,2,3,4,5,4,3,2,1};
size_t sz = sizeof(tab) / sizeof(int);
quicksort(0, sz-1, tab);
print(tab, 0, sz-1);
return 0;
}
void print(int *a, size_t l, size_t r) {
size_t i;
for (i = l; i <= r; ++i) {
printf("%4d", a[i]);
}
printf("\n");
}
void quicksort(int l,int p,int *tab)
{
int i=l,j=p,x=tab[(l+p)/2],w;
printf("pivot=%d\n", x);
do
{
while (tab[i]<x)
{
i++;
}
while (x<tab[j])
{
j--;
}
if (i<=j)
{
w=tab[i];
tab[i]=tab[j];
tab[j]=w;
i++;
j--;
}
}
while (i<=j);
print(tab, l, p);
if (l<j)
{
quicksort(l,j,tab);
}
if (i<p)
{
quicksort(i,p,tab);
}
}
顺便提一下,如果你对每个输入序列进行100次运行时间的平均值,图表显示的运行时间会更加平滑。
我们看到这里的问题是选择主元的策略。让我指出,您可以通过随机化主元选择步骤来缓解对抗性输入的问题。最简单的方法是均匀随机选择主元(每个元素被选为主元的可能性相等); 然后您可以证明该算法在O(n log n)时间内运行很高的概率。(但请注意,要展示此尖峰边界,您需要对输入做出一些假设;如果数字都不同,则该结果肯定成立;例如,请参阅Motwani和Raghavan的随机算法书。)
为了证实我的说法,这里是同一序列使用随机选择主元的运行时间图表,其中
x = tab[l + (rand() % (p-l))]; (确保在主函数中调用
srand(time(NULL)))。
对于A形序列:
对于V形序列: