我目前正在尝试使用tensorflow训练自定义模型,在图像上检测2只手中的17个地标/关键点(指尖,第一关节,底部关节,手腕和手掌),共计34个点(因此需要预测68个值的x和y)。然而,我无法使模型收敛,输出结果是一个几乎对于每个预测都相同的点数组。
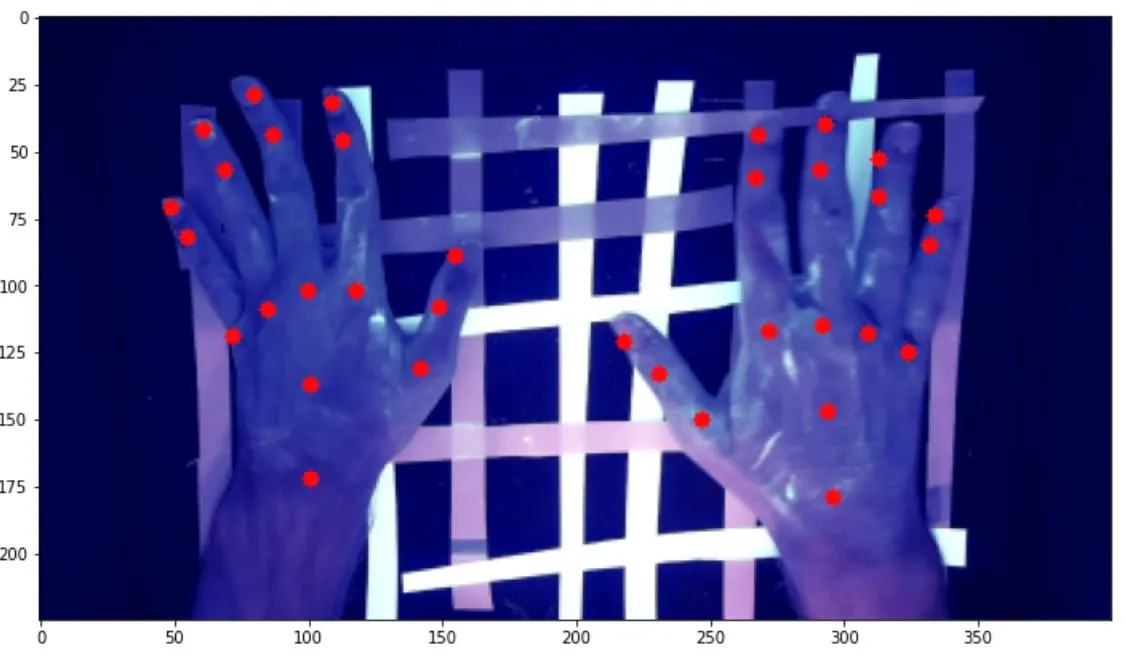
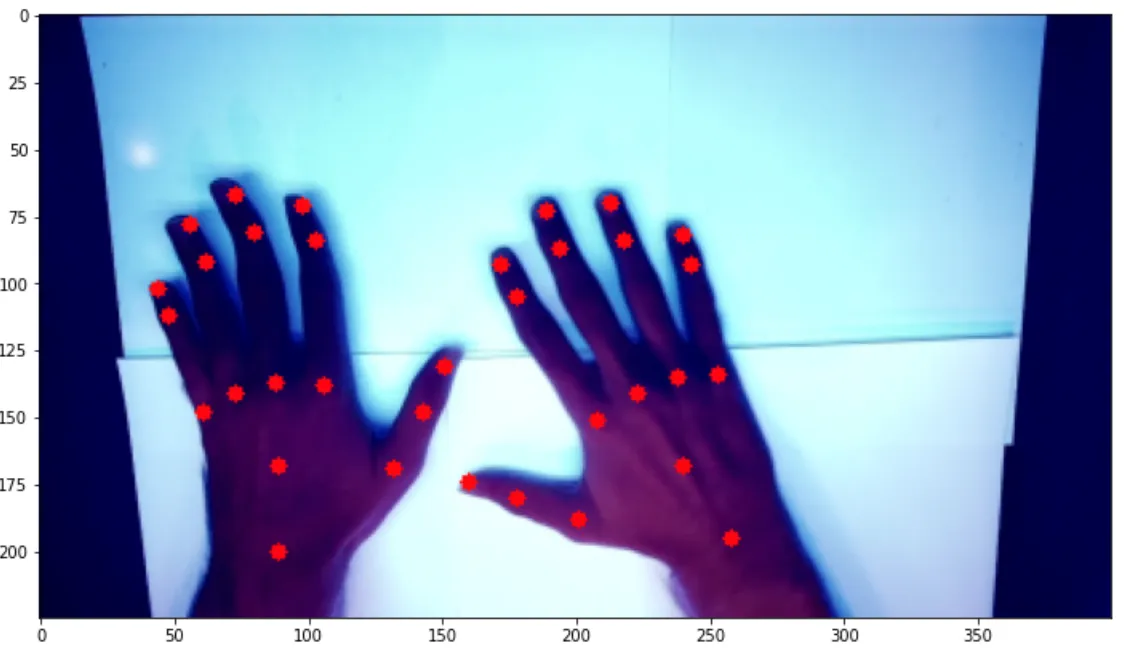
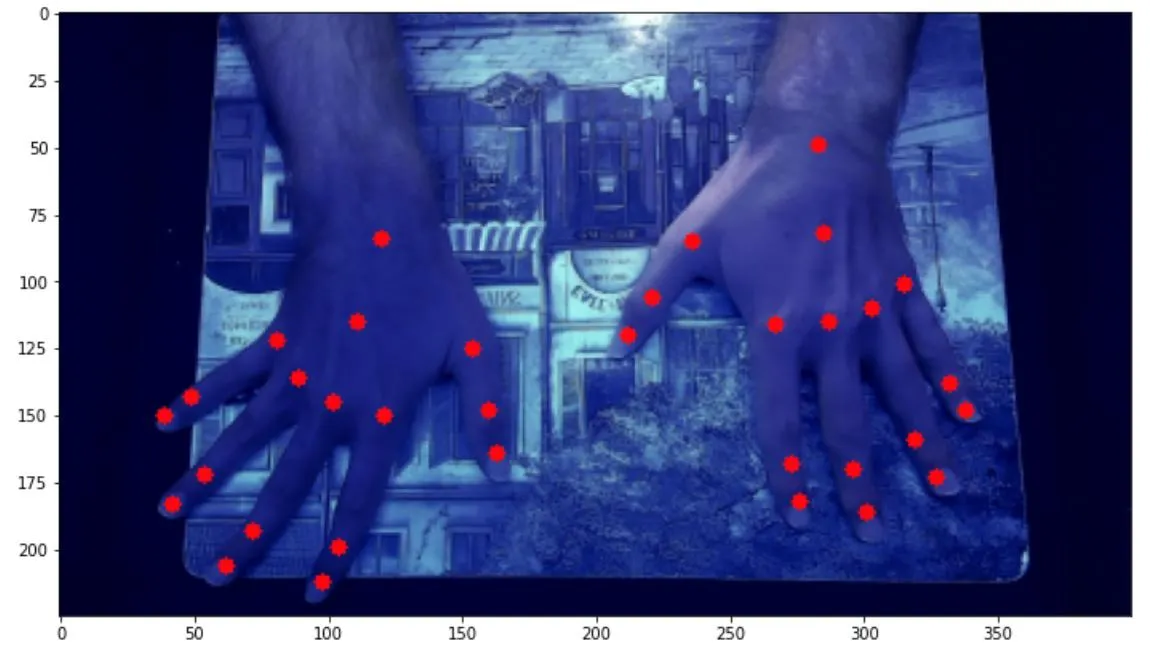
我开始使用的数据集包含这样的图像: 每个关键点都有对应的红点进行注释。为了扩大数据集以尝试获得更强大的模型,我拍摄了各种背景、角度、位置、姿势、光照条件、反射率等手部照片,如下图所示:
每个关键点都有对应的红点进行注释。为了扩大数据集以尝试获得更强大的模型,我拍摄了各种背景、角度、位置、姿势、光照条件、反射率等手部照片,如下图所示:

 。
。
我尝试了几种不同的方法,每种方法都涉及CNN。第一种方法保持图像不变,并使用以下神经网络模型建立:
我已经修改了各种超参数,但似乎没有任何显着的差异。另一件我尝试过的事情是将图像调整大小以适应224x224x3数组,用于VGG-16网络,如下所示:
这个模型的结果与第一个相似。无论我做了什么,似乎都得到相同的结果,即我的mse损失在约0.009左右最小化,mae在约0.07左右,无论我运行多少个时期: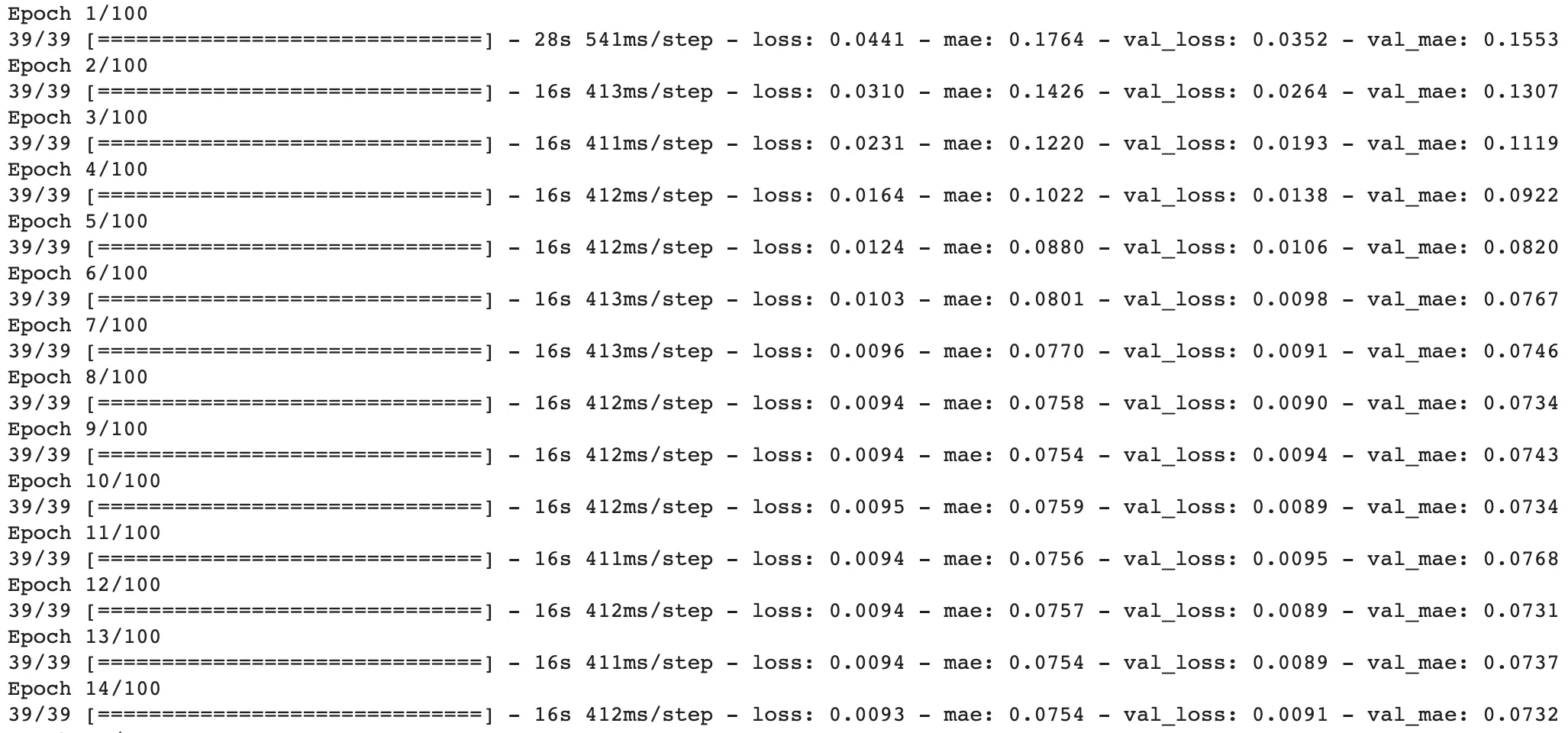 此外,当我基于该模型运行预测时,似乎每个图像的预测输出基本相同,仅在每个图像之间略有变化。看起来,该模型预测了一个坐标数组,看起来有点像展开的手,位于最有可能找到手的一般区域。这是一种适用于所有图像的综合解决方案,而不是针对每个图像的定制解决方案。这些图像说明了这一点,绿色表示预测点,红色表示左手的实际点:
此外,当我基于该模型运行预测时,似乎每个图像的预测输出基本相同,仅在每个图像之间略有变化。看起来,该模型预测了一个坐标数组,看起来有点像展开的手,位于最有可能找到手的一般区域。这是一种适用于所有图像的综合解决方案,而不是针对每个图像的定制解决方案。这些图像说明了这一点,绿色表示预测点,红色表示左手的实际点: 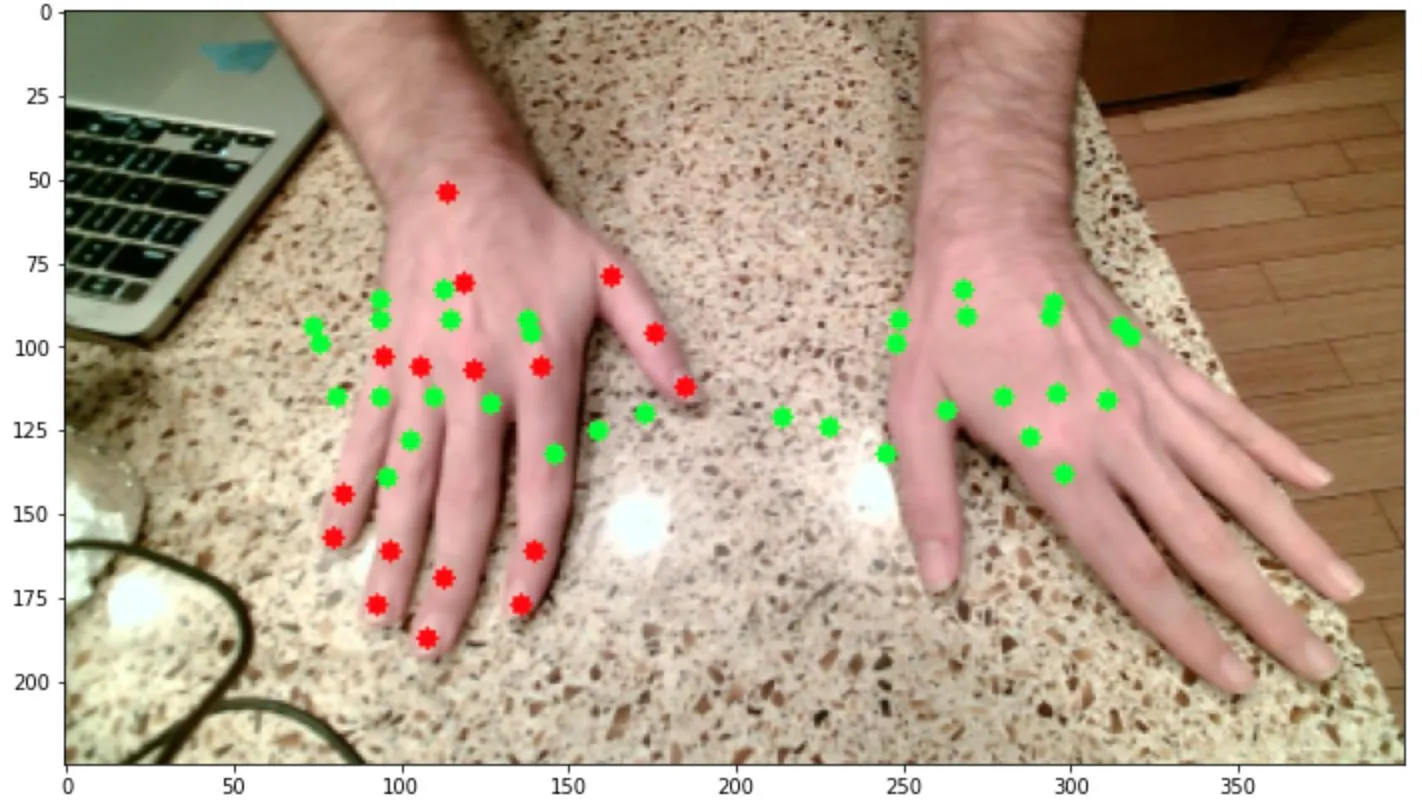
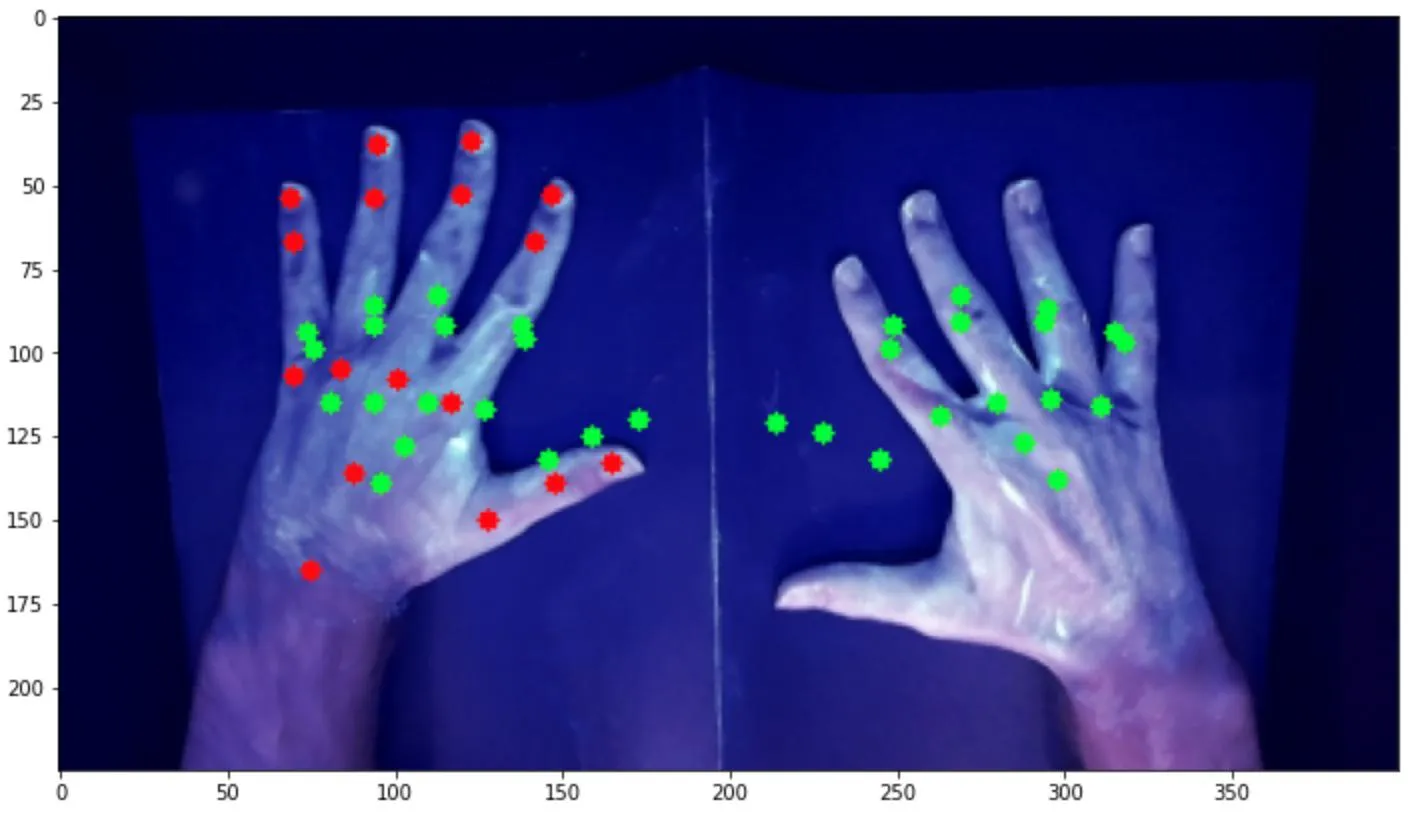
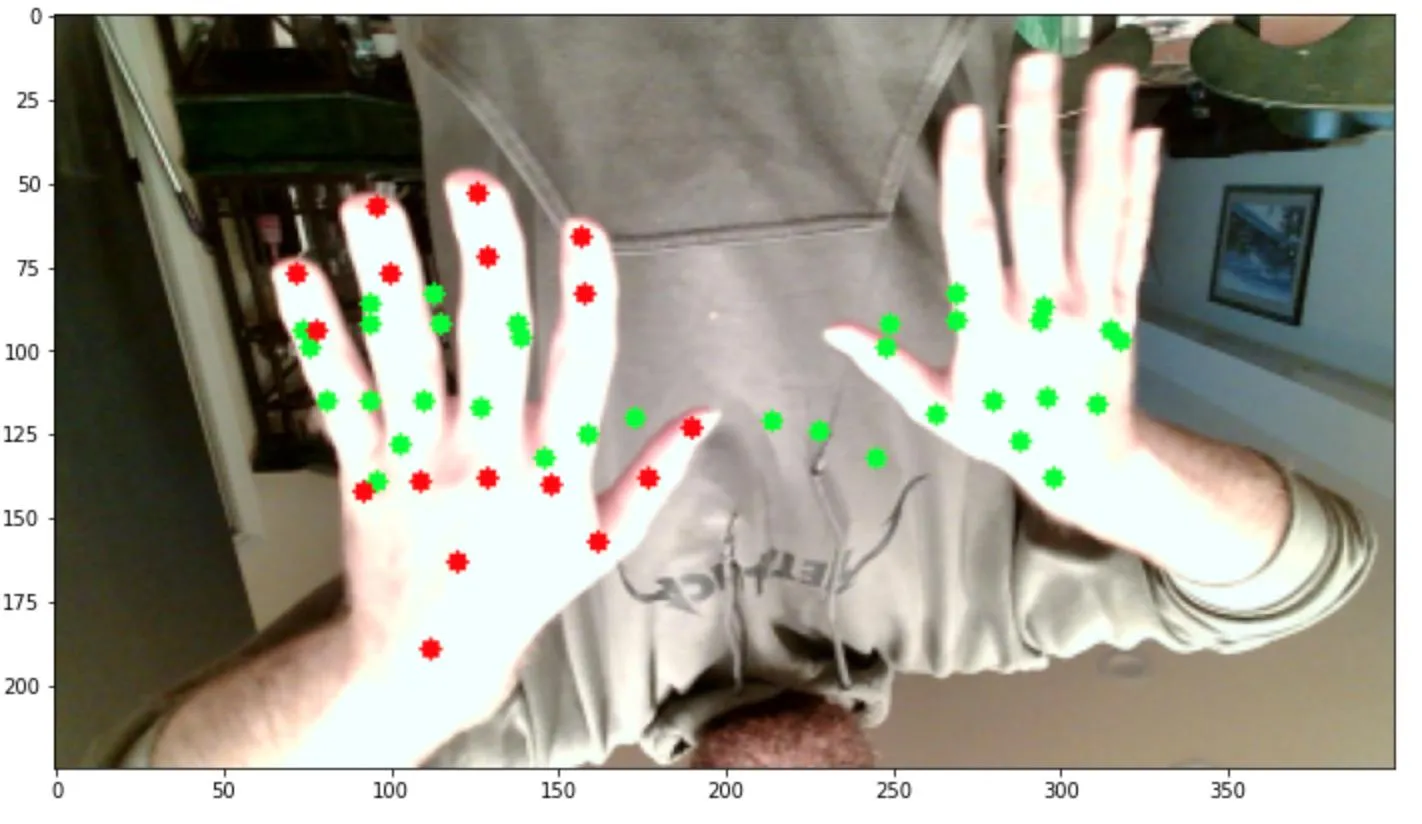
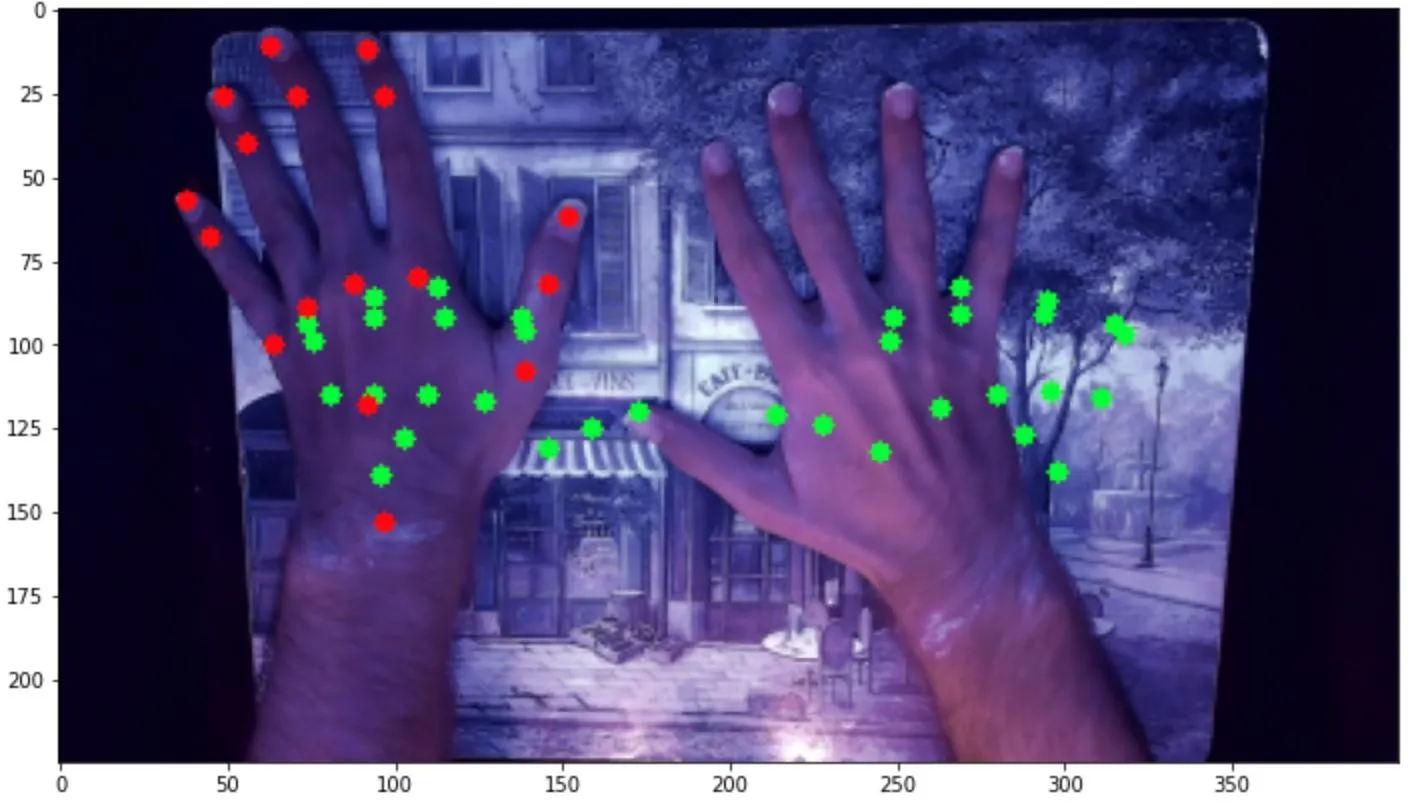 所以,我想知道是什么导致了这个问题,是模型、数据还是两者都有,因为我尝试修改模型或增强数据都没有效果。我甚至尝试将复杂度降低到仅预测一个手的情况,预测每只手的边界框,或预测单个关键点,但无论我尝试什么,结果都相当不准确。
所以,我想知道是什么导致了这个问题,是模型、数据还是两者都有,因为我尝试修改模型或增强数据都没有效果。我甚至尝试将复杂度降低到仅预测一个手的情况,预测每只手的边界框,或预测单个关键点,但无论我尝试什么,结果都相当不准确。
因此,如果您有任何建议可以帮助模型收敛并创建更准确和定制的预测,以便对其看到的每个手图像进行预测,将非常感激。
谢谢,
山姆
我开始使用的数据集包含这样的图像:
每个关键点都有对应的红点进行注释。为了扩大数据集以尝试获得更强大的模型,我拍摄了各种背景、角度、位置、姿势、光照条件、反射率等手部照片,如下图所示: 。
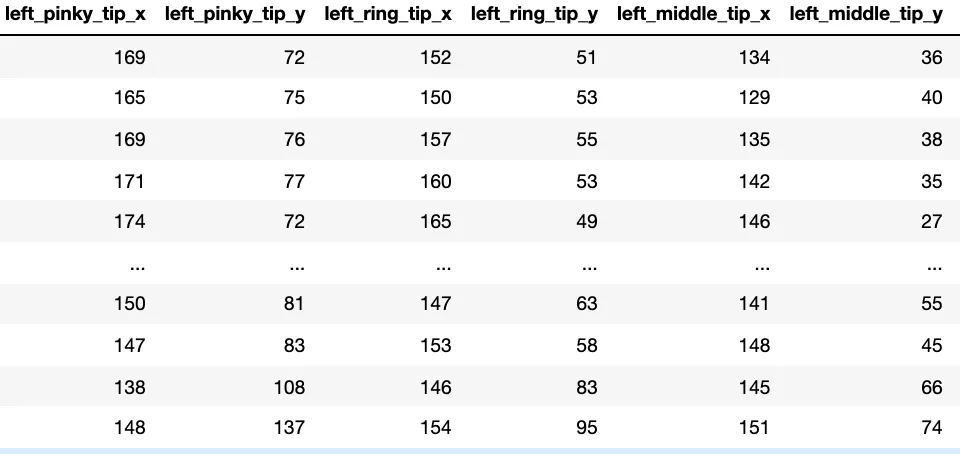
我现在已经创建了大约3000张图片,其中地标信息存储在csv文件中,格式如下:
我尝试了几种不同的方法,每种方法都涉及CNN。第一种方法保持图像不变,并使用以下神经网络模型建立:
model = Sequential()
model.add(Conv2D(filters = 64, kernel_size = (3,3), padding = 'same', activation = 'relu', input_shape = (225,400,3)))
model.add(Conv2D(filters = 64, kernel_size = (3,3), padding = 'same', activation = 'relu'))
model.add(MaxPooling2D(pool_size = (2,2), strides = 2))
filters_convs = [(128, 2), (256, 3), (512, 3), (512,3)]
for n_filters, n_convs in filters_convs:
for _ in np.arange(n_convs):
model.add(Conv2D(filters = n_filters, kernel_size = (3,3), padding = 'same', activation = 'relu'))
model.add(MaxPooling2D(pool_size = (2,2), strides = 2))
model.add(Flatten())
model.add(Dense(128, activation="relu"))
model.add(Dense(96, activation="relu"))
model.add(Dense(72, activation="relu"))
model.add(Dense(68, activation="sigmoid"))
opt = Adam(learning_rate=.0001)
model.compile(loss="mse", optimizer=opt, metrics=['mae'])
print(model.summary())
我已经修改了各种超参数,但似乎没有任何显着的差异。另一件我尝试过的事情是将图像调整大小以适应224x224x3数组,用于VGG-16网络,如下所示:
vgg = VGG16(weights="imagenet", include_top=False,
input_tensor=Input(shape=(224, 224, 3)))
vgg.trainable = False
flatten = vgg.output
flatten = Flatten()(flatten)
points = Dense(256, activation="relu")(flatten)
points = Dense(128, activation="relu")(points)
points = Dense(96, activation="relu")(points)
points = Dense(68, activation="sigmoid")(points)
model = Model(inputs=vgg.input, outputs=points)
opt = Adam(learning_rate=.0001)
model.compile(loss="mse", optimizer=opt, metrics=['mae'])
print(model.summary())
这个模型的结果与第一个相似。无论我做了什么,似乎都得到相同的结果,即我的mse损失在约0.009左右最小化,mae在约0.07左右,无论我运行多少个时期:
此外,当我基于该模型运行预测时,似乎每个图像的预测输出基本相同,仅在每个图像之间略有变化。看起来,该模型预测了一个坐标数组,看起来有点像展开的手,位于最有可能找到手的一般区域。这是一种适用于所有图像的综合解决方案,而不是针对每个图像的定制解决方案。这些图像说明了这一点,绿色表示预测点,红色表示左手的实际点:
所以,我想知道是什么导致了这个问题,是模型、数据还是两者都有,因为我尝试修改模型或增强数据都没有效果。我甚至尝试将复杂度降低到仅预测一个手的情况,预测每只手的边界框,或预测单个关键点,但无论我尝试什么,结果都相当不准确。因此,如果您有任何建议可以帮助模型收敛并创建更准确和定制的预测,以便对其看到的每个手图像进行预测,将非常感激。
谢谢,
山姆