4个回答
9
如我所评论的那样,分类决策树图和回归决策树图之间没有功能上的区别。从docs中调整回归玩具示例:
我们最终得到了一个名为
现在,您可以按照文档中所示进行可视化 - 但如果出于任何原因无法呈现Graphviz对象,则可以使用方便的服务WebGraphviz(+1到链接问题中的相关答案); 结果如下:
from sklearn import tree
X = [[0, 0], [2, 2]]
y = [0.5, 2.5]
clf = tree.DecisionTreeRegressor()
clf = clf.fit(X, y)
接着,类似地,一些关于graphviz的分类docs代码:
import graphviz
dot_data = tree.export_graphviz(clf, out_file='tree.dot')
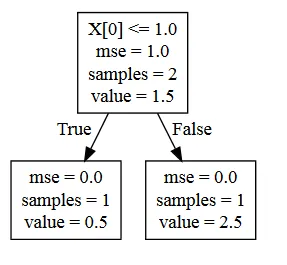
我们最终得到了一个名为
tree.dot的文件,看起来像这样:digraph Tree {
node [shape=box] ;
0 [label="X[0] <= 1.0\nmse = 1.0\nsamples = 2\nvalue = 1.5"] ;
1 [label="mse = 0.0\nsamples = 1\nvalue = 0.5"] ;
0 -> 1 [labeldistance=2.5, labelangle=45, headlabel="True"] ;
2 [label="mse = 0.0\nsamples = 1\nvalue = 2.5"] ;
0 -> 2 [labeldistance=2.5, labelangle=-45, headlabel="False"] ;
}
现在,您可以按照文档中所示进行可视化 - 但如果出于任何原因无法呈现Graphviz对象,则可以使用方便的服务WebGraphviz(+1到链接问题中的相关答案); 结果如下:
你自己的答案,即为了可视化而一路安装 graphlab,听起来有点过度...
最后一句话:不要被树形结构布局上的表面差异所迷惑,这些只反映了各个可视化包的设计选择;你绘制的回归树(诚然,看起来并不像一棵树)在结构上与从文档中取得的分类树类似 - 只需想象一棵自顶向下的树,你的 odor 节点位于顶部,接着是绿色节点,最后到达蓝色和橙色节点(并将 "yes / no" 替换为 "True / False")...
- desertnaut
0
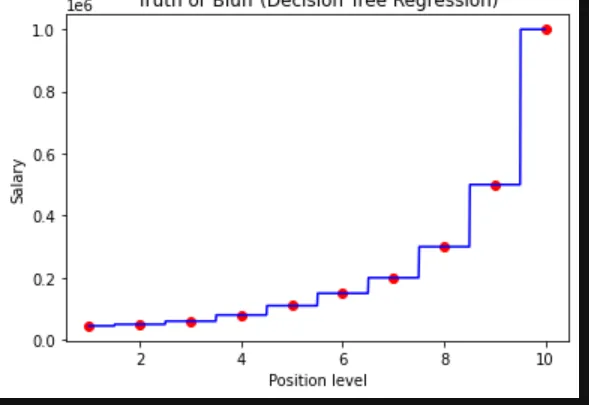
DTR 会为所有值创建一个分区级别
查看图表 - 点击这里
from sklearn.tree import DecisionTreeRegressor
#Getting X and y variable
X = df.iloc[:,1:2].values
y =df.iloc[:,2].values
#Creating a model object and fiting the data
reg = DecisionTreeRegressor(random_state=0)
reg.fit(X,y)
# Visualising the Decision Tree Regression results (higher resolution)
X_grid = np.arange(min(X), max(X), 0.01)
X_grid = X_grid.reshape((len(X_grid), 1))
plt.scatter(X, y, color = 'red')
plt.plot(X_grid, reg.predict(X_grid), color = 'blue')
plt.title('Truth or Bluff (Decision Tree Regression)')
plt.xlabel('Position level')
plt.ylabel('Salary')
plt.show()
- Ravi kumar
{kind=link}
-1
一个简单的文本模式解决方案:
from sklearn import tree
print(tree.export_text(clf_model))
典型的结果:
|--- feature_3 <= 0.46
| |--- feature_0 <= 0.50
| | |--- feature_7 <= 0.50
| | | |--- feature_5 <= 0.78
| | | | |--- value: [3288.64]
etc...
使用clf_model.feature_names_in_获取特征名称
- Poe Dator
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
tree.DecisionTreeRegressor()替换那个问题中的tree.DecisionTreeClassifier()就不能完成任务吗?还是你只对集成中的树感兴趣(如果是这样,你的问题主题表述得不够清楚)? - desertnautsklearn.tree.export_graphviz函数不仅限于DecisionTreeClassifiers,同样适用于回归等价物。 - Jan Trienes