我是一名新手Clojure程序员,我有一些需要优化的代码。我想计算并发计数。主要函数是compute-space,输出是一个嵌套的map类型。
{"w1" {"w11" 10, "w12" 31, ...}
"w2" {"w21" 14, "w22" 1, ...}
...
}
这意味着"w1"与"w11"同时出现10次,等等...
它需要一组文档(句子)和一组目标词,遍历两者并最终应用上下文函数,比如滑动窗口来提取上下文单词。更具体地说,我正在传递一个闭包到滑动窗口。
(compute-space docs (fn [target doc] (sliding-window target doc 5)) targets)
我已经使用大约5000万个单词(约300万个句子)和约20,000个目标进行测试。这个版本需要超过一天才能完成。我还编写了一个pmap并行函数(pcompute-space),可以将计算时间缩短到约10小时,但我仍然感觉它应该更快。我没有其他可供比较的代码,但我的直觉是它应该更快。
(defn compute-space
([docs context-fn targets]
(let [space (atom {})]
(doseq [doc docs
target targets]
(when-let [contexts (context-fn target doc)]
(doseq [w contexts]
(if (get-in @space [target w])
(swap! space update-in [target w] (partial inc))
(swap! space assoc-in [target w] 1)))))
@space)))
(defn sliding-window
[target s n]
(loop [todo s seen [] acc []]
(let [curr (first todo)]
(cond (= curr target) (recur (rest todo) (cons curr seen) (concat acc (take n seen) (take n (rest todo))))
(empty? todo) acc
:else (recur (rest todo) (cons curr seen) acc)))))
(defn pcompute-space
[docs step context-fn targets]
(reduce
#(deep-merge-with + %1 %2)
(pmap
(fn [chunk]
(do (tick))
(compute-space chunk context-fn targets))
(partition-all step docs)))
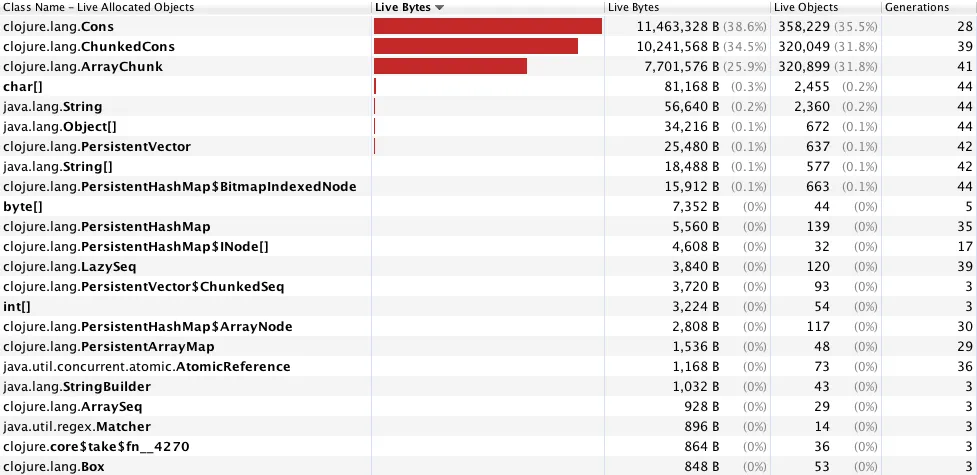
我使用 jvisualvm 对应用程序进行了剖析,发现
clojure.lang.Cons、clojure.lang.ChunkedCons 和 clojure.lang.ArrayChunk 过度地支配了进程(见下图)。这肯定与我使用双重 doseq 循环有关(先前的实验表明,这种方式比使用 map、reduce 等方式更快,尽管我使用 time 来对函数进行基准测试)。如果您能提供任何见解,并提出重构代码以使其运行更快的建议,我将非常感激。我猜 reducers 可以在此处提供一些帮助,但我不确定如何和/或为什么这样做。
规格
MacPro 2010 2,4 GHz Intel Core 2 Duo 4 GB RAM
Clojure 1.6.0
Java 1.7.0_51 Java HotSpot(TM) 64-Bit Server VM
(partial inc)本质上与inc相同。 - Shannon Severancecontext-fn的情况下,实际上是将闭包传递给了compute-space。(例如(fn [target sent] (sliding-window target sent 5)))。我会编辑问题以使其更清晰明了。 - emanjavacas