修改:
1: 修正了评论中提出的边缘情况,更新了基准测试。
2: 向基准测试添加了“扩展”解决方案(必须将最大N元素减少到20000)。
3: 增加了accumarray方法到基准测试中(高N的胜者),以及sparse方法。
以下是另一种获得结果的方法,不使用函数unique或hist,而是依赖于函数sort。
如果您想查看中间步骤的结果,请以扩展形式查看:
A = [4, 12, 9, 8, 9, 12, 7, 1] ;
[B,I] = sort(A) ;
df = diff(B) ;
dx = find(df==0) ;
if ~isempty(dx)
dd = [diff(dx)~=1 , true] ;
dx = [dx dx(dd)+1] ;
d = I(dx)
else
d=[] ;
end
你可以将其压缩为:
[B,I] = sort(A) ;
dx = find(diff(B)==0) ;
if ~isempty(dx)
d = I([dx dx([diff(dx)~=1,true])+1]) ;
else
d = [] ;
end
提供:
d =
3 2 5 6
个人而言,我也会排序返回的索引,但如果不是必须的,而且你关心性能,那么你可以接受未排序的结果。
这里是另一个基准测试(测试元素数量从10到20000):
运行在MATLAB R2016a上
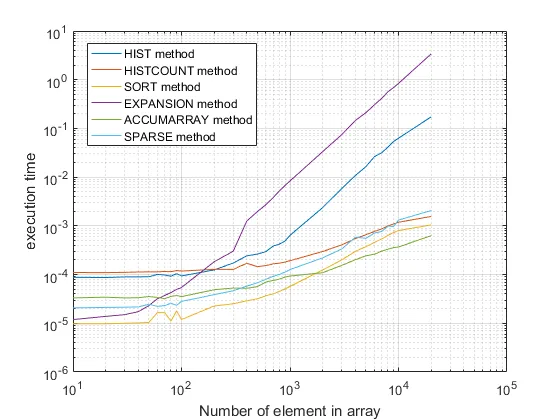
代码如下:
function ExecTimes = benchmark_findDuplicates
nOrder = (1:9).' * 10.^(1:3) ; nOrder = [nOrder(:) ; 10000 ; 20000 ] ;
npt = numel(nOrder) ;
ExecTimes = zeros(npt,6) ;
for k = 1:npt
N = nOrder(k) ;
A = randi(5000,[1,N]) ;
f1 = @() findDuplicates_histMethod(A) ;
f2 = @() findDuplicates_histcountMethod(A) ;
f3 = @() findDuplicates_sortMethod(A) ;
f4 = @() findDuplicates_expansionMethod(A) ;
f5 = @() findDuplicates_accumarrayMethod(A) ;
f6 = @() findDuplicates_sparseMethod(A) ;
ExecTimes(k,1) = timeit( f1 ) ;
ExecTimes(k,2) = timeit( f2 ) ;
ExecTimes(k,3) = timeit( f3 ) ;
ExecTimes(k,4) = timeit( f4 ) ;
ExecTimes(k,5) = timeit( f5 ) ;
ExecTimes(k,6) = timeit( f6 ) ;
clear A
disp(N)
end
function d = findDuplicates_histMethod(A)
U = unique(A);
[co,ce] = hist(A,U);
an = ce(co>1);
d=[];
for i=1:numel(an)
d=[d,find(A==an(i))];
end
end
function d = findDuplicates_histcountMethod(A)
[~,idxu,idxc] = unique(A);
[count, ~, idxcount] = histcounts(idxc,numel(idxu));
idxkeep = count(idxcount)>1;
idx_A = 1:length(A);
d = idx_A(idxkeep);
end
function d = findDuplicates_sortMethod(A)
[B,I] = sort(A) ;
dx = find(diff(B)==0) ;
if ~isempty(dx)
d = I([dx dx([diff(dx)~=1,true])+1]) ;
else
d=[];
end
end
function d = findDuplicates_expansionMethod(A)
Ae = ones(numel(A),1) * A ;
d = find(sum(Ae==Ae.')>1) ;
end
function d = findDuplicates_accumarrayMethod(A)
d = find(ismember(A, find(accumarray(A(:), 1)>1))) ;
end
function d = findDuplicates_sparseMethod(A)
d = find(ismember(A, find(sparse(A, 1, 1)>1)));
end
end
unique和hist函数是主要原因。我在这里调用hist函数来查找数组中唯一元素的频率,并查找频率大于 1 的元素的索引。 - impopularGuyd = find(sum(A==A.')>1)。 - obchardon