由于我对深度学习还很新,所以这个问题可能对你来说有点幼稚。但是我无法在脑海中形象化它。这就是我要问它的原因。
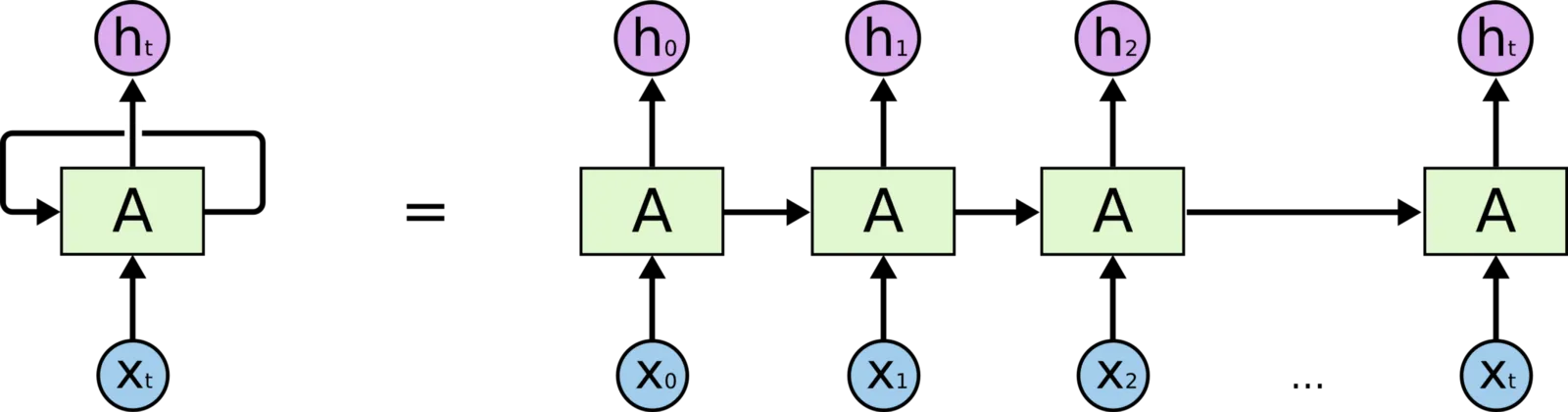
我将一句话作为向量交给LSTM,例如一句话包含10个单词。然后我将这些句子转换为向量并将其提供给LSTM。
LSTM单元的长度应该为10。但是在大多数教程中,我看到它们添加了128个隐藏状态。我无法理解和形象化它。通过LSTM层的“128维隐藏状态”这个词是什么意思?
例如:
X = LSTM(128, return_sequences=True)(embeddings)
这个的总结如下:
lstm_1 (LSTM) (None, 10, 128) 91648
这里似乎添加了10个LSTM单元,但为什么有128个隐藏状态?希望您明白我的期望。