如何找到(遍历)从/到给定节点的有向图中的所有环?
例如,我想要像这样的东西:
A->B->A
A->B->C->A
但不包括: B->C->B
如何找到(遍历)从/到给定节点的有向图中的所有环?
例如,我想要像这样的东西:
A->B->A
A->B->C->A
但不包括: B->C->B
我在搜索中发现了这个页面,因为循环结构不同于强连通分量,所以我继续搜索,最终找到了一种高效的算法,可以列出有向图中的所有(基本)循环。该算法来自 Donald B. Johnson,文章可以在以下链接中找到:
http://www.cs.tufts.edu/comp/150GA/homeworks/hw1/Johnson%2075.PDF
Java实现可以在以下链接中找到:
http://normalisiert.de/code/java/elementaryCycles.zip
Johnson算法的Mathematica演示可在此处找到,实现可以从右侧下载(“下载作者代码”)。
注意:实际上,对于这个问题有许多算法。其中一些列在这篇文章中:
http://dx.doi.org/10.1137/0205007
根据该文章,Johnson算法是最快的。
A->B->C->A 也是基本环,我可能有所遗漏。 - psmearssimple_cycle。 - Joel可以使用深度优先搜索(DFS)和回溯来解决这个问题。使用一个布尔值的数组来记录是否已经访问过某个节点。如果在没有遇到已经访问过的节点的情况下不能找到新的节点,则回溯并尝试不同的分支。
如果有邻接表表示图,则很容易实现DFS。例如,adj[A] = {B,C}表示B和C是A的子节点。
下面是伪代码示例。 "start" 是您从中开始的节点。
dfs(adj,node,visited):
if (visited[node]):
if (node == start):
"found a path"
return;
visited[node]=YES;
for child in adj[node]:
dfs(adj,child,visited)
visited[node]=NO;
使用起始节点调用上述函数:
visited = {}
dfs(adj,start,visited)
我发现解决这个问题最简单的选择是使用名为networkx的Python库。
它实现了在这个问题的最佳答案中提到的 Johnson 算法,但执行起来非常简单。
简而言之,你需要以下内容:
import networkx as nx
import matplotlib.pyplot as plt
# Create Directed Graph
G=nx.DiGraph()
# Add a list of nodes:
G.add_nodes_from(["a","b","c","d","e"])
# Add a list of edges:
G.add_edges_from([("a","b"),("b","c"), ("c","a"), ("b","d"), ("d","e"), ("e","a")])
#Return a list of cycles described as a list o nodes
list(nx.simple_cycles(G))
答案: [['a', 'b', 'd', 'e'], ['a', 'b', 'c']]
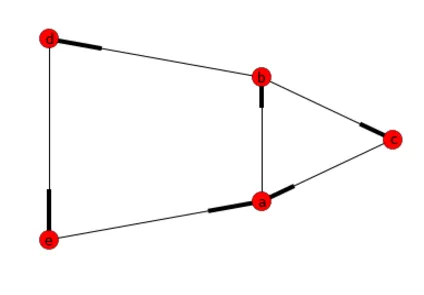
nx.DiGraph({'a': ['b'], 'b': ['c','d'], 'c': ['a'], 'd': ['e'], 'e':['a']})。 - Luke Miles顺便提一下,既然我提到了无向图:这些算法是不同的。首先建立一个生成树,然后那些不在生成树中的边就会和树上的一些边形成一个简单的环。通过这种方式找到的环被称为循环基底。所有简单的环都可以通过组合两个或更多不同的基底环来找到。更多细节请参见此处:http://dspace.mit.edu/bitstream/handle/1721.1/68106/FTL_R_1982_07.pdf。
jgrapht 的示例,它被用在 http://code.google.com/p/niographs/ 中。您可以从 https://github.com/jgrapht/jgrapht/wiki/DirectedGraphDemo 中获取示例。 - Vishrant val NO_EDGE = Integer.MAX_VALUE / 2
def shortestPath(weights: Array[Array[Int]]) = {
for (k <- weights.indices;
i <- weights.indices;
j <- weights.indices) {
val throughK = weights(i)(k) + weights(k)(j)
if (throughK < weights(i)(j)) {
weights(i)(j) = throughK
}
}
}
这个算法最初是在加权边图上操作,以查找所有节点对之间的最短路径(因此需要权重参数)。为了使它正确工作,如果两个节点之间有一个有向边,则需要提供1,否则提供NO_EDGE。
算法执行后,您可以检查主对角线,如果有小于NO_EDGE的值,则此节点参与长度等于该值的循环。同一循环中的其他节点将具有相同的值(在主对角线上)。
要重建循环本身,我们需要使用稍微修改过的带父级跟踪版本的算法。
def shortestPath(weights: Array[Array[Int]], parents: Array[Array[Int]]) = {
for (k <- weights.indices;
i <- weights.indices;
j <- weights.indices) {
val throughK = weights(i)(k) + weights(k)(j)
if (throughK < weights(i)(j)) {
parents(i)(j) = k
weights(i)(j) = throughK
}
}
}
如果两个顶点之间有边,则父矩阵的初始值应为源顶点索引,否则为-1。
函数返回后,对于每条边,您将拥有指向最短路径树中父节点的引用。
然后就可以轻松恢复实际的循环。
总之,我们有以下程序查找所有最小循环:
val NO_EDGE = Integer.MAX_VALUE / 2;
def shortestPathWithParentTracking(
weights: Array[Array[Int]],
parents: Array[Array[Int]]) = {
for (k <- weights.indices;
i <- weights.indices;
j <- weights.indices) {
val throughK = weights(i)(k) + weights(k)(j)
if (throughK < weights(i)(j)) {
parents(i)(j) = parents(i)(k)
weights(i)(j) = throughK
}
}
}
def recoverCycles(
cycleNodes: Seq[Int],
parents: Array[Array[Int]]): Set[Seq[Int]] = {
val res = new mutable.HashSet[Seq[Int]]()
for (node <- cycleNodes) {
var cycle = new mutable.ArrayBuffer[Int]()
cycle += node
var other = parents(node)(node)
do {
cycle += other
other = parents(other)(node)
} while(other != node)
res += cycle.sorted
}
res.toSet
}
还需要一个小的主方法来测试结果
def main(args: Array[String]): Unit = {
val n = 3
val weights = Array(Array(NO_EDGE, 1, NO_EDGE), Array(NO_EDGE, NO_EDGE, 1), Array(1, NO_EDGE, NO_EDGE))
val parents = Array(Array(-1, 1, -1), Array(-1, -1, 2), Array(0, -1, -1))
shortestPathWithParentTracking(weights, parents)
val cycleNodes = parents.indices.filter(i => parents(i)(i) < NO_EDGE)
val cycles: Set[Seq[Int]] = recoverCycles(cycleNodes, parents)
println("The following minimal cycle found:")
cycles.foreach(c => println(c.mkString))
println(s"Total: ${cycles.size} cycle found")
}
输出结果为:
The following minimal cycle found:
012
Total: 1 cycle found
澄清一下:
强连通分量将查找所有至少存在一个循环的子图,而不是图中所有可能的循环。例如,如果您将所有强连通分量合并为一个节点(即每个组件一个节点),则可以获得没有循环的树(实际上是有向无环图)。每个组件(基本上是至少包含一个循环的子图)内部可以包含更多可能的循环,因此SCC将不会查找到所有可能的循环,它将查找所有可能具有至少一个循环的组,并且如果将它们合并,则该图将不会有循环。
要找到图中所有简单循环,正如其他人所提到的,Johnson算法就是一个候选算法。
这里是一个带有测试用例的Java实现链接:
http://stones333.blogspot.com/2013/12/find-cycles-in-directed-graph-dag.html