有没有一种高效的算法可以检测有向图中的循环?
我有一个表示需要执行的作业安排的有向图,其中作业是节点,依赖关系是边。我需要检测出图中存在循环依赖导致错误的情况。
有没有一种高效的算法可以检测有向图中的循环?
我有一个表示需要执行的作业安排的有向图,其中作业是节点,依赖关系是边。我需要检测出图中存在循环依赖导致错误的情况。
塔杨强连通分量算法(Tarjan's strongly connected components algorithm)的时间复杂度为O(|E| + |V|)。
其他相关算法请参见维基百科上的强连通分量。
tsort肯定会检测到。因此,最好同时检测循环和对任务进行排序,而不是分开进行。其中包含一种算法的伪代码以及Tarjan的另一种算法的简要描述。两种算法的时间复杂度均为
O(| V | + | E |)。已经在多个答案中提到过这一点;在此我还将基于CLRS第22章提供一个代码示例。下面是所示例图。如果一个有向图G无回边,则G是无环图。
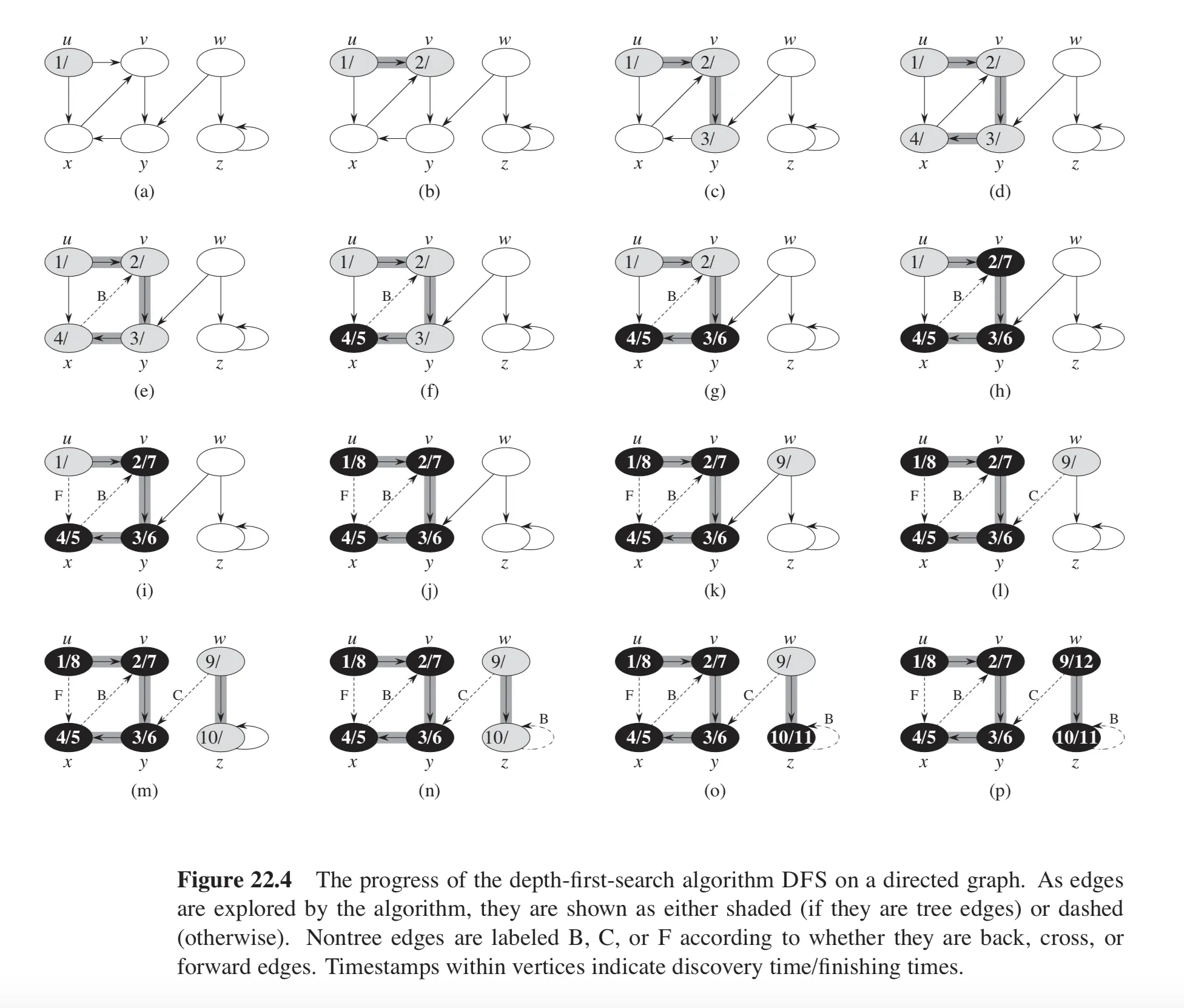
CLRS的深度优先搜索伪代码如下:

DFS-VISIT函数中遍历u的邻居v时,遇到颜色为GRAY的节点,就会遇到反向边。if子句来检测循环。import collections
class Graph(object):
def __init__(self, edges):
self.edges = edges
self.adj = Graph._build_adjacency_list(edges)
@staticmethod
def _build_adjacency_list(edges):
adj = collections.defaultdict(list)
for edge in edges:
adj[edge[0]].append(edge[1])
adj[edge[1]] # side effect only
return adj
def dfs(G):
discovered = set()
finished = set()
for u in G.adj:
if u not in discovered and u not in finished:
discovered, finished = dfs_visit(G, u, discovered, finished)
def dfs_visit(G, u, discovered, finished):
discovered.add(u)
for v in G.adj[u]:
# Detect cycles
if v in discovered:
print(f"Cycle detected: found a back edge from {u} to {v}.")
break
# Recurse into DFS tree
if v not in finished:
dfs_visit(G, v, discovered, finished)
discovered.remove(u)
finished.add(u)
return discovered, finished
if __name__ == "__main__":
G = Graph([
('u', 'v'),
('u', 'x'),
('v', 'y'),
('w', 'y'),
('w', 'z'),
('x', 'v'),
('y', 'x'),
('z', 'z')])
dfs(G)
Cycle detected: found a back edge from x to v.
Cycle detected: found a back edge from z to z.
这些恰好是CLRS图22.4中示例的反向边。
discovered, finished = dfs_visit(G, u, discovered, finished) 可以替换为:dfs_visit(G, u, discovered, finished),并且 dfs-visit 可以返回 None。 - Sanandreabreak 语句。 - Christian LongRuntimeError: dictionary changed size during iteration。这是因为G.adj是一个默认字典,并且在for v in G.adj[u]中的查找正在添加它。 - Christian Long_build_adjacency_list 的 for 循环中添加对 adj[edge[1]] 的调用,这将初始化节点的键,这些节点在至少某个边缘中不出现为 edge[0](通常发生在没有循环的图形中)(刚刚添加到答案中)。 - Jthorpe最简单的方法是对图进行深度优先遍历(DFT)。
如果图有n个顶点,则这是一个O(n)时间复杂度算法。由于您可能需要从每个顶点开始进行DFT,因此总复杂度变为O(n^2)。
您必须维护一个包含当前深度优先遍历中所有顶点的堆栈,其第一个元素为根节点。如果在DFT期间遇到已经在堆栈中的元素,则表示存在环。
O(n),同时建议检查堆栈以查看它是否已包含访问过的节点?扫描堆栈会增加 O(n) 运行时的时间,因为它必须在每个新节点上扫描堆栈。如果标记节点已访问,则可以实现 O(n)。 - James Wierzba在我看来,检测有向图中循环的最易懂算法是图着色算法。
基本上,图着色算法以DFS方式(深度优先搜索,这意味着它会在探索下一个路径之前完全探索一条路径)遍历图。当它找到一个反向边时,就会将图标记为包含循环。
如果想要深入了解图着色算法,请阅读这篇文章:http://www.geeksforgeeks.org/detect-cycle-direct-graph-using-colors/
此外,我提供了JavaScript实现的图着色算法,具体请参考:https://github.com/dexcodeinc/graph_algorithm.js/blob/master/graph_algorithm.js
从DFS开始:当且仅当在DFS过程中发现反向边时,存在一个环。这是白路径定理的结果。
没有一种算法可以在多项式时间内找到有向图中的所有环。假设,有向图有n个节点,每对节点之间都有连接,这意味着您有一个完全图。因此,这n个节点的任何非空子集都表示一个环,而且有2^n-1个这样的子集。因此,不存在多项式时间算法。 因此,假设您拥有一种有效(非愚蠢)的算法,可以告诉您图中有多少个有向循环,您可以首先找到强连通分量,然后将您的算法应用于这些连通分量。由于循环只存在于分量内部而不是它们之间。
我曾经用sml(命令式编程)实现过这个问题。以下是大纲:找到所有入度或出度为0的节点,这些节点不能成为循环的一部分(因此要删除它们)。接下来删除这些节点的所有入边或出边。然后递归地将此过程应用于结果图。如果最终没有留下任何节点或边,则该图没有任何循环;否则就存在循环。
https://mathoverflow.net/questions/16393/finding-a-cycle-of-fixed-length 我最喜欢这个解决方案,特别是对于长度为4的情况 :)
此外,物理巫师说你必须执行O(V ^ 2)。我相信我们只需要O(V)/ O(V + E)即可。
如果图是连通的,则DFS将访问所有节点。如果图具有连接的子图,则每次在该子图的顶点上运行DFS时,我们将找到已连接的顶点,并且不必考虑下一次运行DFS时的这些顶点。 因此,为每个顶点运行的可能性是不正确的。