我已经试图在Python中实现这个算法几天了。我一直回过头来,然后就放弃了,感到沮丧。我不知道发生了什么。我没有人可以问,也没有地方可以寻求帮助,所以我来到这里。
Mahesh Viswanathan - CS 473ug: Algorithms - Dynamic Programming
PDF警告:http://www.cs.uiuc.edu/class/sp08/cs473/Lectures/lec10.pdf
我觉得这个解释不够清楚,我确实不理解。
我对发生的事情的理解是这样的:
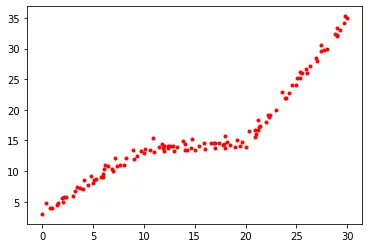
我们有一组点(x1,y1),(x2,y2)..,我们想要找到最适合这些数据的一些直线。我们可以有多条直线,这些直线来自给定的a和b的公式(y = ax + b)。
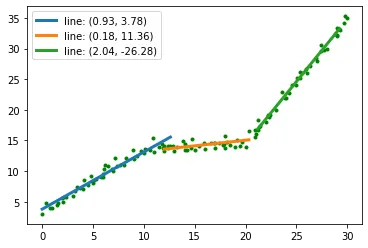
现在算法从末尾开始(?),假设点p(x_i,y_i)是线段的一部分。然后笔记中提到最优解是“对于{p1,... pi−1}的最优解加上通过{pi,... pn}的(最佳)直线”。对我来说,这意味着我们到达点p(x_i,y_i),然后向后找到另一条通过其余点的线段。现在最优解是这两个线段的组合。
然后它进行了一个我无法理解的逻辑跳跃,并说“假设最后一个点pn是从p_i开始的一段的一部分。如果Opt(j)表示前j个点的成本,e(j,k)表示通过点j到k的最佳直线的误差,那么Opt(n)= e(i,n)+ C + Opt(i−1)”。
然后是算法的伪代码,我不理解。我知道我们想要遍历点列表并找到最小化OPT(n)公式的点,但我就是不明白。这让我感觉很愚蠢。
我知道这个问题很烦人,而且不容易回答,但我只是想寻求一些指导,以便理解这个算法。对于使用PDF的不便,我表示歉意,但我没有更好的方法将关键信息传达给读者。
感谢您花时间阅读这篇文章,我非常感激。
我对发生的事情的理解是这样的:
我们有一组点(x1,y1),(x2,y2)..,我们想要找到最适合这些数据的一些直线。我们可以有多条直线,这些直线来自给定的a和b的公式(y = ax + b)。
现在算法从末尾开始(?),假设点p(x_i,y_i)是线段的一部分。然后笔记中提到最优解是“对于{p1,... pi−1}的最优解加上通过{pi,... pn}的(最佳)直线”。对我来说,这意味着我们到达点p(x_i,y_i),然后向后找到另一条通过其余点的线段。现在最优解是这两个线段的组合。
然后它进行了一个我无法理解的逻辑跳跃,并说“假设最后一个点pn是从p_i开始的一段的一部分。如果Opt(j)表示前j个点的成本,e(j,k)表示通过点j到k的最佳直线的误差,那么Opt(n)= e(i,n)+ C + Opt(i−1)”。
然后是算法的伪代码,我不理解。我知道我们想要遍历点列表并找到最小化OPT(n)公式的点,但我就是不明白。这让我感觉很愚蠢。
我知道这个问题很烦人,而且不容易回答,但我只是想寻求一些指导,以便理解这个算法。对于使用PDF的不便,我表示歉意,但我没有更好的方法将关键信息传达给读者。
感谢您花时间阅读这篇文章,我非常感激。