cor接受两个数据框:
A<-data.frame(A1=c(1,2,3,4,5),B1=c(6,7,8,9,10),C1=c(11,12,13,14,15 ))
B<-data.frame(A2=c(6,7,7,10,11),B2=c(2,1,3,8,11),C2=c(1,5,16,7,8))
cor(A,B)
# A2 B2 C2
# A1 0.9481224 0.9190183 0.459588
# B1 0.9481224 0.9190183 0.459588
# C1 0.9481224 0.9190183 0.459588
diag(cor(A,B))
#[1] 0.9481224 0.9190183 0.4595880
编辑:
以下是一些基准测试结果:
Unit: microseconds
expr min lq median uq max neval
diag(cor(A, B)) 230.292 238.4225 243.0115 255.0295 352.955 100
mapply(cor, A, B) 267.076 281.5120 286.8030 299.5260 375.087 100
unlist(Map(cor, A, B)) 250.053 259.1045 264.5635 275.9035 1146.140 100
编辑2:
使用更好的基准测试:
set.seed(42)
A <- as.data.frame(matrix(rnorm(10*n),ncol=n))
B <- as.data.frame(matrix(rnorm(10*n),ncol=n))
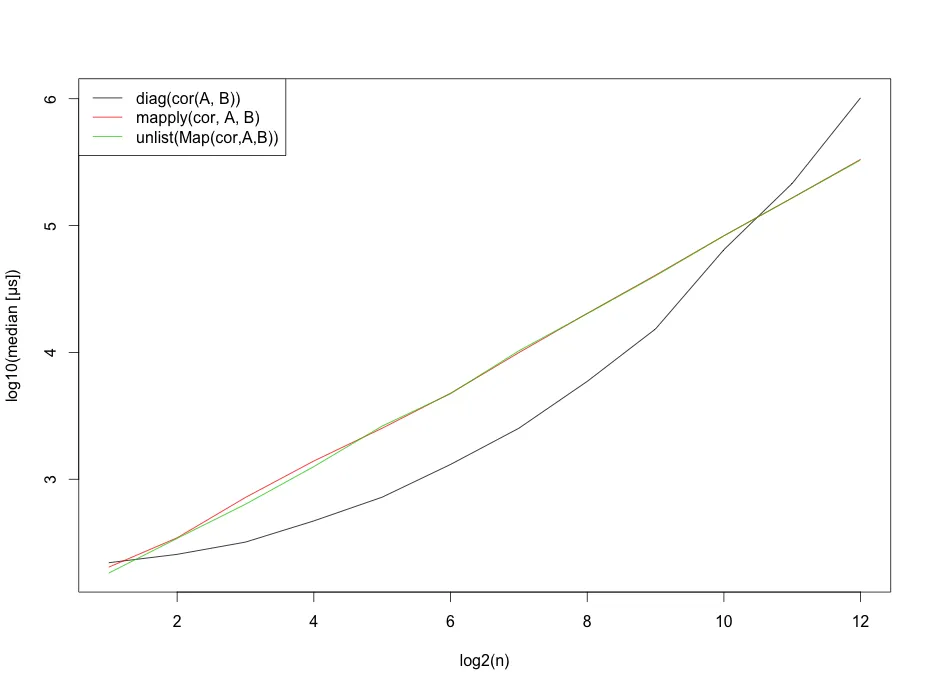
然而,我应该提到这些基准测试结果强烈依赖于行数。
编辑3:因为有人要求基准测试代码,所以在这里提供它。
b <- sapply(2^(1:12), function(n) {
set.seed(42)
A <- as.data.frame(matrix(rnorm(10*n),ncol=n))
B <- as.data.frame(matrix(rnorm(10*n),ncol=n))
require(microbenchmark)
res <- print(microbenchmark(
diag(cor(A,B)),
mapply(cor, A, B),
unlist(Map(cor,A,B)),
times=10
),unit="us")
res$median
})
b <- t(b)
matplot(x=1:12,log10(b),type="l",
ylab="log10(median [µs])",
xlab="log2(n)",col=1:3,lty=1)
legend("topleft", legend=c("diag(cor(A, B))",
"mapply(cor, A, B)",
"unlist(Map(cor,A,B))"),lty=1, col=1:3)
cor的函数可以给出相关性的 p 值? - daynediag非常快,这里并不重要。如果将数据框传递给cor,则会强制转换为矩阵。然后将矩阵传递给C函数。编译的代码比mapply或Map更有效率。 - Roland