给定 n 个部分和,可以在 log2 并行步骤中对所有部分和进行求和。例如,假设有八个线程和八个部分和:s0, s1, s2, s3, s4, s5, s6, s7。可以通过 log2(8) = 3 个顺序步骤将其缩减为一个和。
thread0 thread1 thread2 thread4
s0 += s1 s2 += s3 s4 += s5 s6 +=s7
s0 += s2 s4 += s6
s0 += s4
我希望使用OpenMP来实现这个,但是我不想使用OpenMP的reduction子句。我已经想出了一个解决方案,但我认为可能可以找到更好的解决方案,也许可以使用OpenMP的task子句。
这比标量加法更普遍。让我选择一个更有用的情况:数组归约(有关数组归约的更多信息,请参见here,here和here)。
假设我想在数组a上进行数组归约。这里是一些代码,它为每个线程并行填充私有数组。
int bins = 20;
int a[bins];
int **at; // array of pointers to arrays
for(int i = 0; i<bins; i++) a[i] = 0;
#pragma omp parallel
{
#pragma omp single
at = (int**)malloc(sizeof *at * omp_get_num_threads());
at[omp_get_thread_num()] = (int*)malloc(sizeof **at * bins);
int a_private[bins];
//arbitrary function to fill the arrays for each thread
for(int i = 0; i<bins; i++) at[omp_get_thread_num()][i] = i + omp_get_thread_num();
}
此时,我有一个指向每个线程数组的指针数组。现在我想将所有这些数组相加并将最终总和写入a。这是我想出的解决方案。
#pragma omp parallel
{
int n = omp_get_num_threads();
for(int m=1; n>1; m*=2) {
int c = n%2;
n/=2;
#pragma omp for
for(int i = 0; i<n; i++) {
int *p1 = at[2*i*m], *p2 = at[2*i*m+m];
for(int j = 0; j<bins; j++) p1[j] += p2[j];
}
n+=c;
}
#pragma omp single
memcpy(a, at[0], sizeof *a*bins);
free(at[omp_get_thread_num()]);
#pragma omp single
free(at);
}
让我来解释一下这段代码的作用。假设有八个线程。我们定义
+=操作符表示对数组求和。例如,s0 += s1是将s1加到s0上。for(int i=0; i<bins; i++) s0[i] += s1[i]
那么这段代码将会执行
n thread0 thread1 thread2 thread4
4 s0 += s1 s2 += s3 s4 += s5 s6 +=s7
2 s0 += s2 s4 += s6
1 s0 += s4
但是,我的代码并不理想。
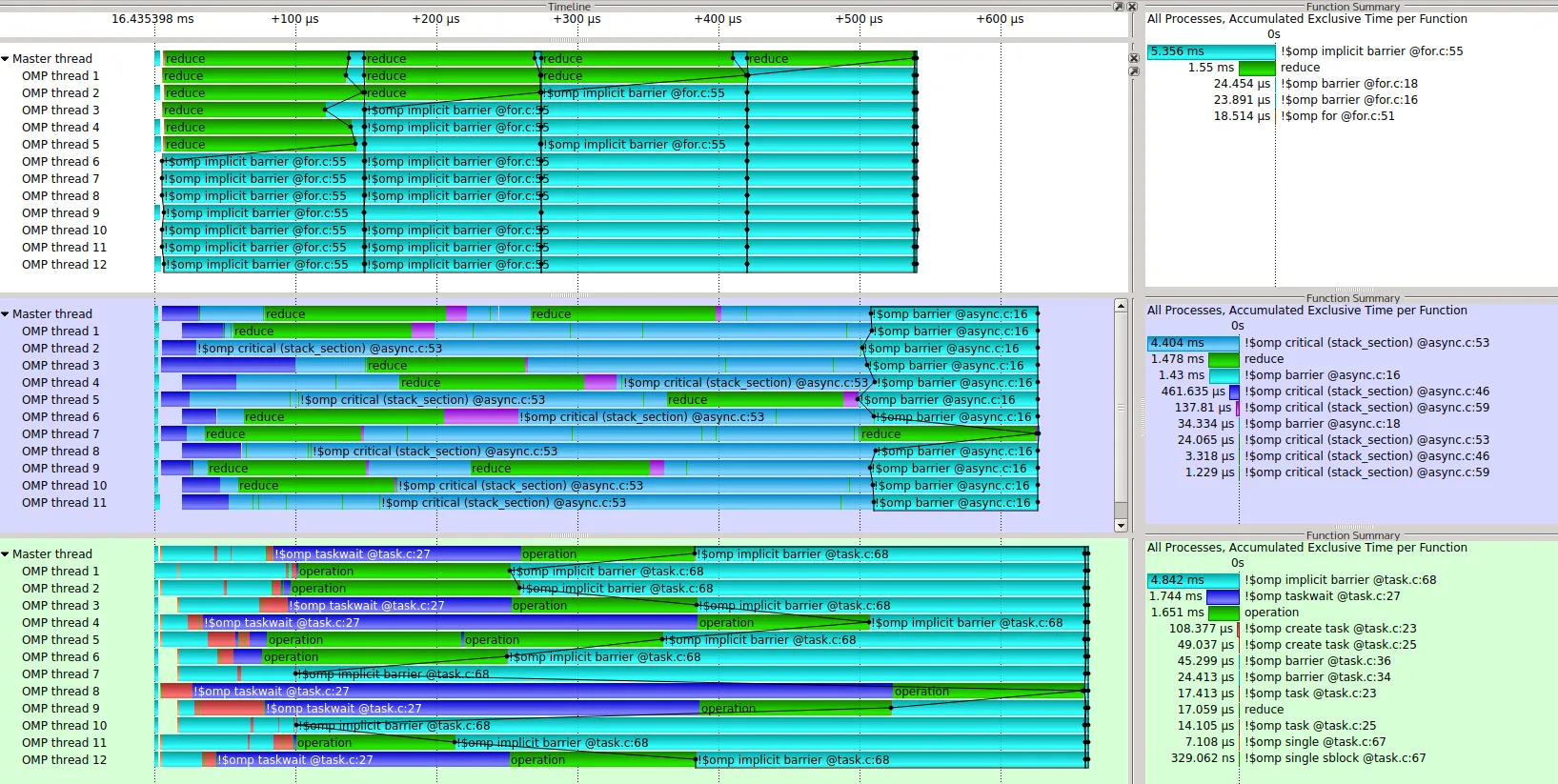
其中一个问题是,有一些隐含的屏障需要所有线程进行同步。这些屏障不应该是必要的。第一个屏障在填充数组和进行规约之间。第二个屏障在规约中的
#pragma omp for声明中。但是我不能使用nowait子句来移除屏障。另一个问题是,有几个线程不需要使用。例如,有8个线程。规约中第一步只需要4个线程,第二步需要2个线程,最后一步只需要1个线程。然而,这种方法将涉及到所有8个线程的规约。虽然,其他线程不做什么,应该直接到达屏障等待,所以可能不是什么问题。
我的直觉是,可以使用omp
task子句找到更好的方法。不幸的是,我对task子句的经验很少,迄今为止,我所做的所有努力都无法比现在更好地进行规约。有人能建议一种更好的方法,使用例如OpenMP的
task子句在对数时间内进行规约吗?
我找到了一种解决屏障问题的方法。这种方法是异步的。唯一剩下的问题是它仍然会将不参与缩减的线程放入繁忙循环中。该方法使用类似堆栈的东西,在关键部分中将指针推入堆栈(但从不弹出)。这是其中一个关键点,因为关键部分没有隐式屏障。堆栈是串行操作的,但缩减是并行的。
以下是一个可行的示例。
#include <stdio.h>
#include <omp.h>
#include <stdlib.h>
#include <string.h>
void foo6() {
int nthreads = 13;
omp_set_num_threads(nthreads);
int bins= 21;
int a[bins];
int **at;
int m = 0;
int nsums = 0;
for(int i = 0; i<bins; i++) a[i] = 0;
#pragma omp parallel
{
int n = omp_get_num_threads();
int ithread = omp_get_thread_num();
#pragma omp single
at = (int**)malloc(sizeof *at * n * 2);
int* a_private = (int*)malloc(sizeof *a_private * bins);
//arbitrary fill function
for(int i = 0; i<bins; i++) a_private[i] = i + omp_get_thread_num();
#pragma omp critical (stack_section)
at[nsums++] = a_private;
while(nsums<2*n-2) {
int *p1, *p2;
char pop = 0;
#pragma omp critical (stack_section)
if((nsums-m)>1) p1 = at[m], p2 = at[m+1], m +=2, pop = 1;
if(pop) {
for(int i = 0; i<bins; i++) p1[i] += p2[i];
#pragma omp critical (stack_section)
at[nsums++] = p1;
}
}
#pragma omp barrier
#pragma omp single
memcpy(a, at[2*n-2], sizeof **at *bins);
free(a_private);
#pragma omp single
free(at);
}
for(int i = 0; i<bins; i++) printf("%d ", a[i]); puts("");
for(int i = 0; i<bins; i++) printf("%d ", (nthreads-1)*nthreads/2 +nthreads*i); puts("");
}
int main(void) {
foo6();
}
我认为可以使用任务来寻找更好的方法,而不会使未被使用的线程处于忙碌状态。

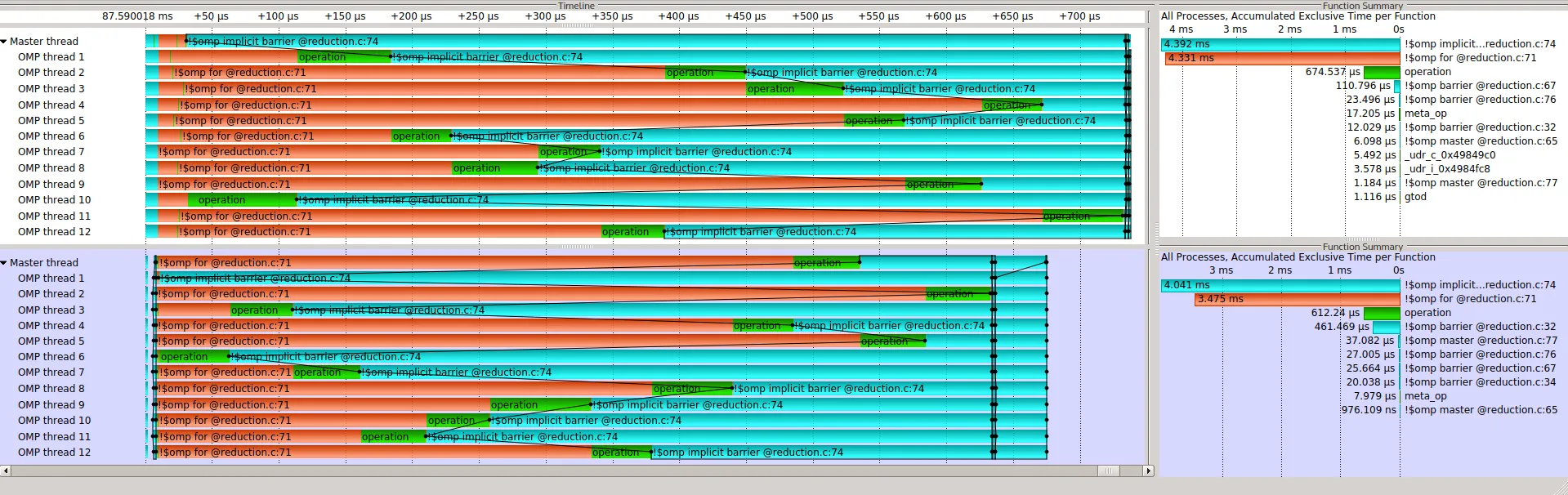
reduction是一个黑盒子。因为我不知道它是如何工作的,甚至不知道它是否使用了log(nthreads)的约简。因为当操作不可交换时,reduction不起作用。因为我认为学会如何手动处理事物很有用。因为我认为OpenMP是教授并行编程概念的良好范例。 - Z bosonn >> N所以第二阶段如何处理并不重要,因为时间完全由第一阶段主导。但是如果n ≈ N呢?在这种情况下,第二阶段将不会无关紧要。我承认我应该想出一个例子来展示这一点(我的意思是用时间来衡量),但是 SO 上的每个人都说要使用reduction子句来进行 OpenMP,因为它可能会在log(t)操作中执行第二阶段。所以我认为这可能是一个例子。 - Z boson