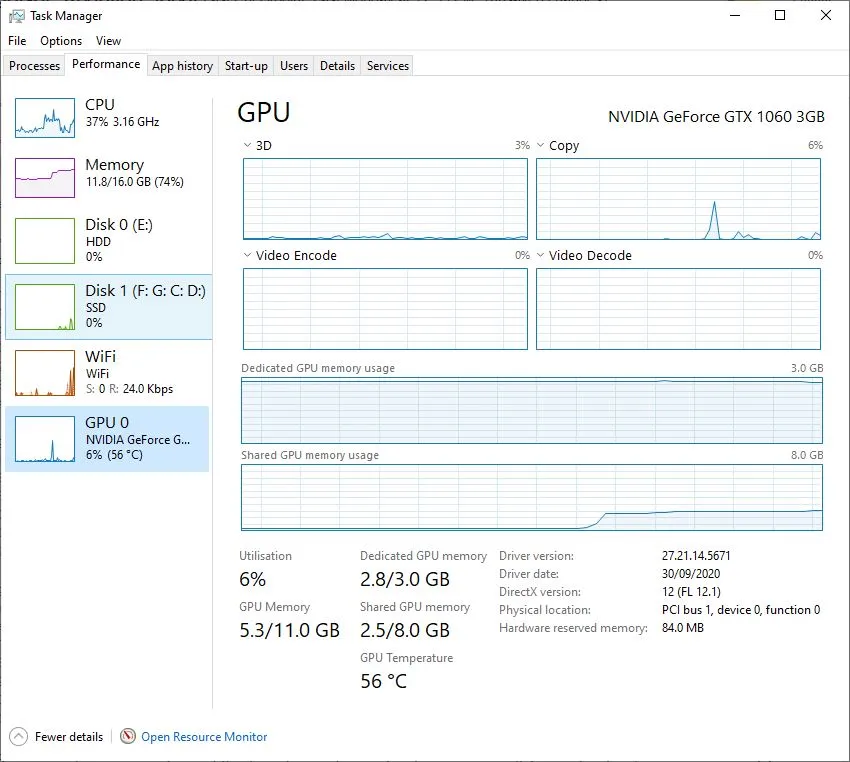
根据我的经验,Tensorflow只使用如下所述的专用GPU内存。此时,memory_limit = 最大专用内存 - 当前专用内存使用量(在Win10任务管理器中观察)。
from tensorflow.python.client import device_lib
print(device_lib.list_local_devices())
输出:
physical_device_desc: "device: XLA_CPU device"
, name: "/device:GPU:0"
device_type: "GPU"
memory_limit: 2196032718
为了验证这一点,我尝试使用一个单一的任务(来自
https://github.com/aime-team/tf2-benchmarks的Tensorflow 2基准测试),在装有Tensorflow 2.3.0的GTX1060 3GB上运行时出现了以下“资源耗尽”的错误。
2021-01-20 01:50:53.738987: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1716] Found device 0 with properties:
pciBusID: 0000:01:00.0 name: GeForce GTX 1060 3GB computeCapability: 6.1
coreClock: 1.7085GHz coreCount: 9 deviceMemorySize: 3.00GiB deviceMemoryBandwidth: 178.99GiB/s
Limit: 2196032718
InUse: 1997814016
MaxInUse: 2155556352
NumAllocs: 1943
MaxAllocSize: 551863552
Reserved: 0
PeakReserved: 0
LargestFreeBlock: 0
2021-01-20 01:51:21.393175: W tensorflow/core/framework/op_kernel.cc:1767] OP_REQUIRES failed at conv_ops.cc:539 : Resource exhausted: OOM when allocating tensor with shape[64,256,56,56] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc
Traceback (most recent call last):
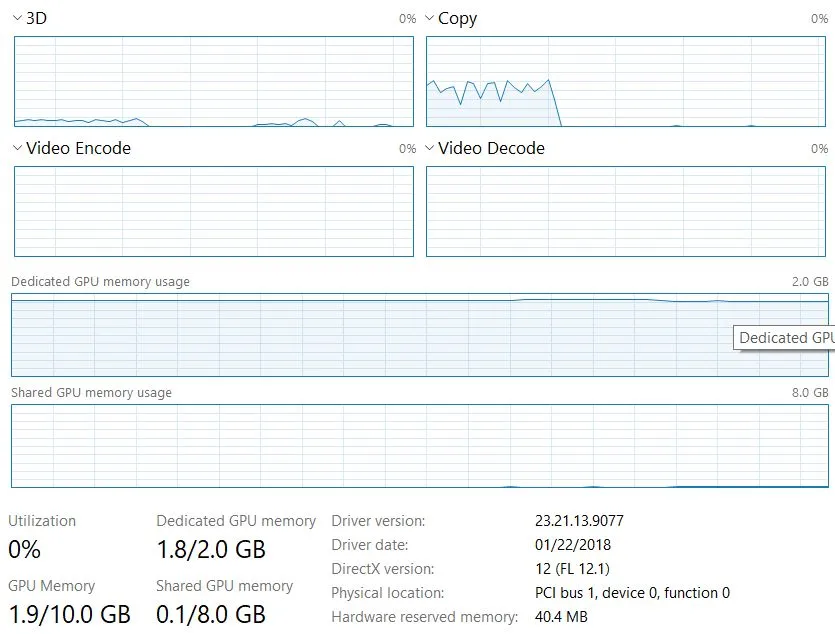
我尝试通过多个小任务来实现同样的操作。它试图使用共享的GPU内存来运行不同的Juypter内核上的多个任务,但最终较新的任务失败。
例如,有两个相似的Xception模型:
任务1:没有错误地运行
任务2:出现以下错误而失败
UnknownError: Failed to get convolution algorithm. This is probably because cuDNN failed to initialize, so try looking to see if a warning log message was printed above.
[[node xception/block1_conv1/Conv2D (defined at <ipython-input-25-0c5fe80db9f1>:3) ]] [Op:__inference_predict_function_5303]
Function call stack:
predict_function
在失败时的GPU内存使用情况(请注意任务2开始时共享内存的使用)