我想使用mscoco数据集,使用 faster_rcnn_with resnet101 以及谷歌的物体检测来进行训练代码。 我只使用了10,000张图片进行培训。我的显卡是:GeForce 930M/PCIe/SSE2,NVIDIA驱动程序版本:384.90。这是我的GeForce的图片。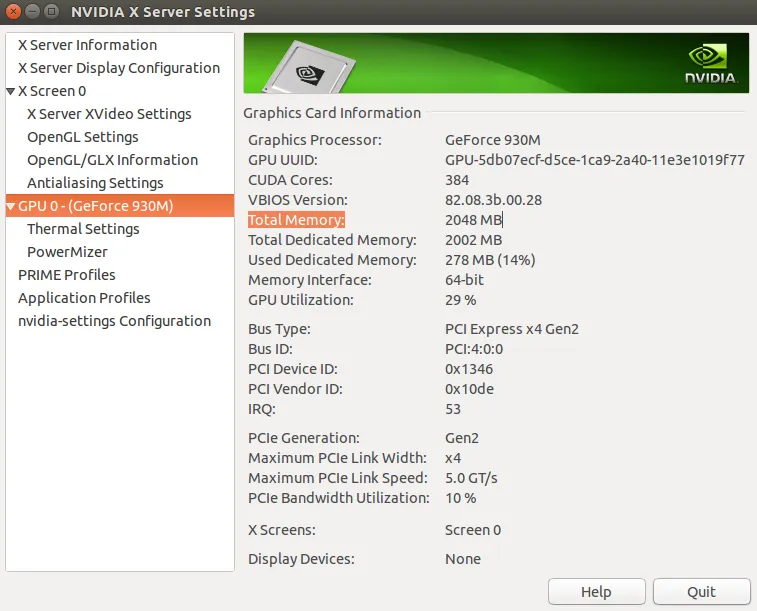
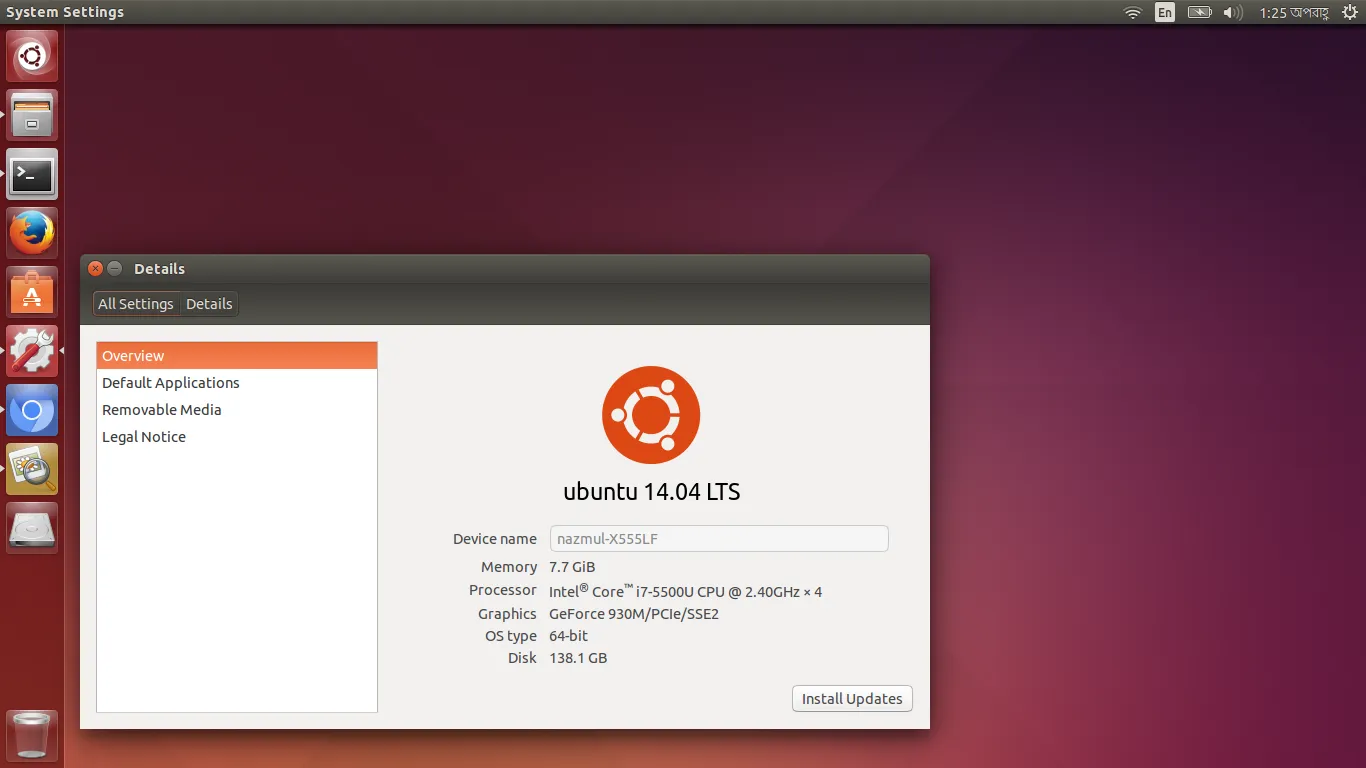
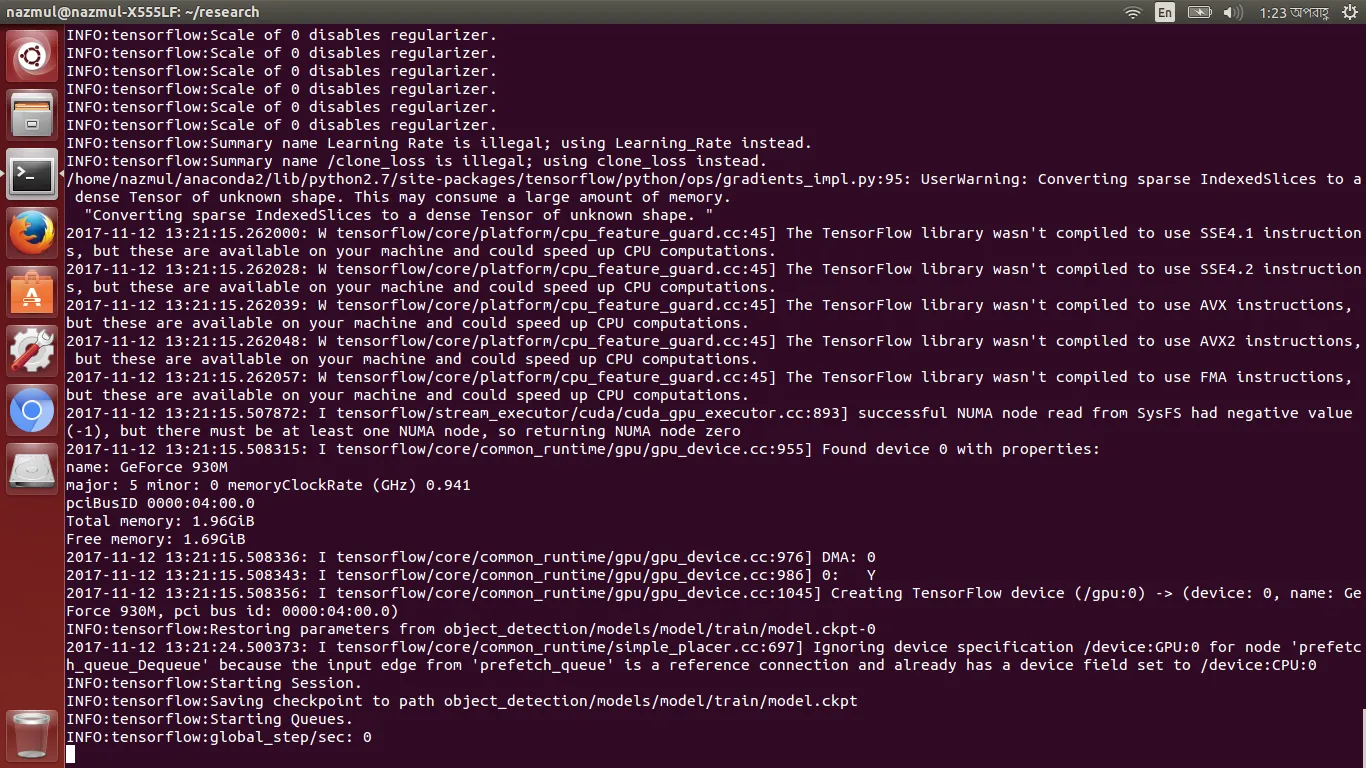
我有8GB RAM,但在tensorflow gpu中显示为1.96GB。
 现在该怎么扩展我的GPU RAM?我想使用全部系统内存。
现在该怎么扩展我的GPU RAM?我想使用全部系统内存。
我想使用mscoco数据集,使用 faster_rcnn_with resnet101 以及谷歌的物体检测来进行训练代码。 我只使用了10,000张图片进行培训。我的显卡是:GeForce 930M/PCIe/SSE2,NVIDIA驱动程序版本:384.90。这是我的GeForce的图片。
我有8GB RAM,但在tensorflow gpu中显示为1.96GB。
现在该怎么扩展我的GPU RAM?我想使用全部系统内存。