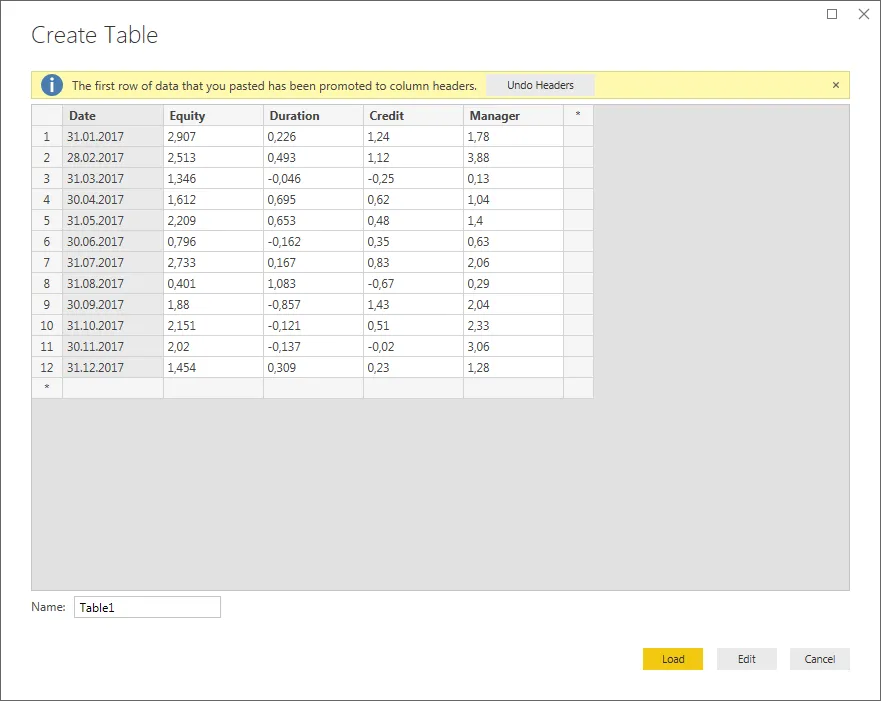
假设我有一组收益数据,想要计算它们相对于不同市场指数的beta值。为了举一个具体的例子,让我们使用以下数据集,在名为
它会输出一个类似于这样的数组:
问题是如何在Power BI中使用DAX获取这些值(最好不用编写自定义的R脚本)?
Returns的表格中呈现: Date Equity Duration Credit Manager
-----------------------------------------------
01/31/2017 2.907% 0.226% 1.240% 1.78%
02/28/2017 2.513% 0.493% 1.120% 3.88%
03/31/2017 1.346% -0.046% -0.250% 0.13%
04/30/2017 1.612% 0.695% 0.620% 1.04%
05/31/2017 2.209% 0.653% 0.480% 1.40%
06/30/2017 0.796% -0.162% 0.350% 0.63%
07/31/2017 2.733% 0.167% 0.830% 2.06%
08/31/2017 0.401% 1.083% -0.670% 0.29%
09/30/2017 1.880% -0.857% 1.430% 2.04%
10/31/2017 2.151% -0.121% 0.510% 2.33%
11/30/2017 2.020% -0.137% -0.020% 3.06%
12/31/2017 1.454% 0.309% 0.230% 1.28%
现在在Excel中,我可以使用LINEST函数来获取beta值:
= LINEST(Returns[Manager], Returns[[Equity]:[Credit]], TRUE, TRUE)
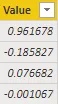
它会输出一个类似于这样的数组:
0.077250253 -0.184974002 0.961578127 -0.001063971
0.707796954 0.60202895 0.540811546 0.008257129
0.50202386 0.009166729 #N/A #N/A
2.688342242 8 #N/A #N/A
0.000677695 0.000672231 #N/A #N/A
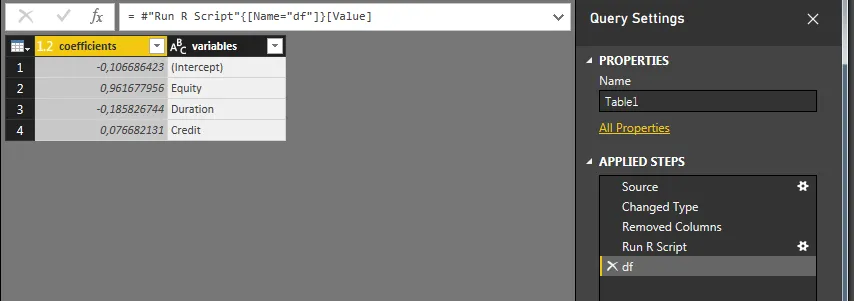
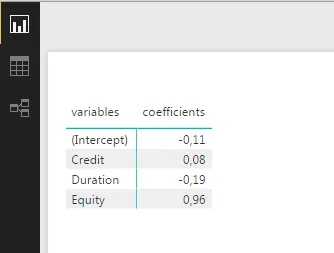
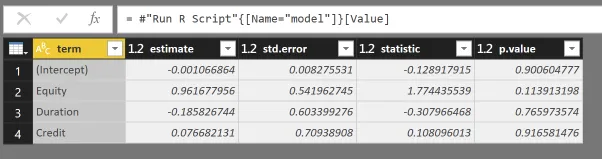
这些beta值位于顶行,使用它们可以给出以下线性估计:
Manager = 0.962 * Equity - 0.185 * Duration + 0.077 * Credit - 0.001
问题是如何在Power BI中使用DAX获取这些值(最好不用编写自定义的R脚本)?
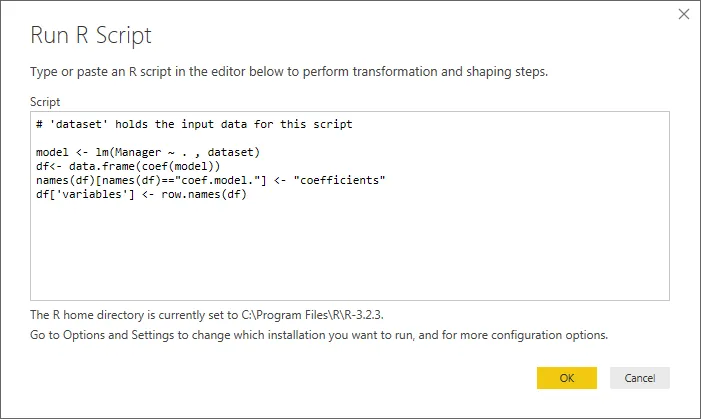
对于针对单列的简单线性回归,我可以返回到数学定义并编写类似于此帖子中给出的最小二乘实现。
然而,当涉及更多列时(我需要能够处理多达12列,但不总是相同数量),这很快变得混乱,我希望有更好的方法。