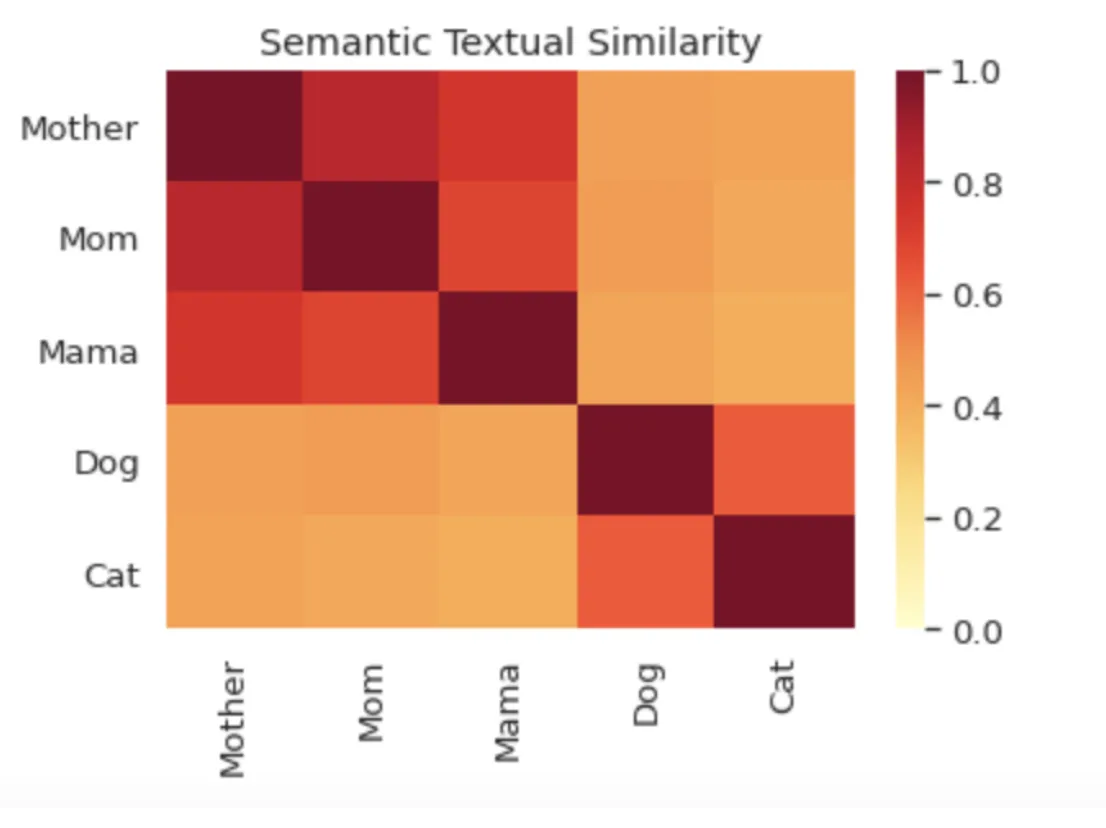
更新于2020年10月21日
我决定开发一个Python模块来处理本回答中提到的任务。该模块名为wordhoard,可以从pypi下载。
我曾尝试在需要确定关键词(例如“healthcare”)及其同义词(例如“wellness program”、“preventive medicine”)频率的项目中使用Word2vec和WordNet 。我发现大多数NLP库无法产生我所需的结果,因此我决定使用自定义关键词和同义词构建自己的字典。这种方法在多个项目中都成功地应用于文本分析和分类。
我相信精通NLP技术的人可能会有更强大的解决方案,但下面这个解决方案对我来说一次又一次地奏效。
我编写了我的答案以匹配您问题中的单词频率数据,但它可以修改为使用任何关键词和同义词数据集。
import string
word_relationship = {"father": ['dad', 'daddy', 'old man', 'pa', 'pappy', 'papa', 'pop'],
"mother": ["mamma", "momma", "mama", "mammy", "mummy", "mommy", "mom", "mum"]}
input_text = 'The hand that rocks the cradle also makes the house a home. It is the prayers of the mother ' \
'that keeps the family strong. When I think about my mum, I just cannot help but smile; The beauty of ' \
'her loving heart, the easy grace in her style. I will always need my mom, regardless of my age. She ' \
'has made me laugh, made me cry. Her love will never fade. If I could write a story, It would be the ' \
'greatest ever told. I would write about my daddy, For he had a heart of gold. For my father, my friend, ' \
'This to me you have always been. Through the good times and the bad, Your understanding I have had.'
wordlist = input_text.lower().split()
remove_punctuation = [''.join(ch for ch in s if ch not in string.punctuation)
for s in wordlist]
wordfreq = []
for w in remove_punctuation:
wordfreq.append(remove_punctuation.count(w))
word_frequencies = (dict(zip(remove_punctuation, wordfreq)))
word_matches = []
for word, frequency in word_frequencies.items():
for keyword, synonym in word_relationship.items():
match = [x for x in synonym if word == x]
if word == keyword or match:
match = ' '.join(map(str, match))
word_matches.append([keyword, match, frequency])
final_results = {}
synonym_matches = [(keyword[0], keyword[2]) for keyword in word_matches]
for item in synonym_matches:
if item[0] not in final_results.keys():
frequency_count = 0
frequency_count = frequency_count + item[1]
final_results[item[0]] = frequency_count
else:
frequency_count = frequency_count + item[1]
final_results[item[0]] = frequency_count
print(final_results)
{'mother': 3, 'father': 2}
其他方法
以下是一些其他方法及其开箱即用的输出。
NLTK WORDNET
在这个例子中,我查找了单词"mother"的同义词。请注意,WordNet没有将"mom"或"mum"这两个同义词与单词"mother"联系起来。这两个词都在我的示例文本中。还要注意,“father”被列为“mother”的一个同义词。
from nltk.corpus import wordnet
synonyms = []
word = 'mother'
for synonym in wordnet.synsets(word):
for item in synonym.lemmas():
if word != synonym.name() and len(synonym.lemma_names()) > 1:
synonyms.append(item.name())
print(synonyms)
['mother', 'female_parent', 'mother', 'fuss', 'overprotect', 'beget', 'get', 'engender', 'father', 'mother', 'sire', 'generate', 'bring_forth']
PyDictionary
使用PyDictionary查询synonym.com,我以单词"mother"为例查询其同义词。这个例子中同义词包括单词"mom"和"mum"。同时,该例子还列举了WordNet未生成的其他同义词。
然而,PyDictionary也为"mum"生成了一个同义词列表。这与单词"mother"无关。看起来PyDictionary从页面的形容词部分提取了这个列表,而不是名词部分。对于计算机来说,很难区分形容词和名词中的"mum"。
from PyDictionary import PyDictionary
dictionary_mother = PyDictionary('mother')
print(dictionary_mother.getSynonyms())
[{'mother': ['mother-in-law', 'female parent', 'supermom', 'mum', 'parent', 'mom', 'momma', 'para I', 'mama', 'mummy', 'quadripara', 'mommy', 'quintipara', 'ma', 'puerpera', 'surrogate mother', 'mater', 'primipara', 'mammy', 'mamma']}]
dictionary_mum = PyDictionary('mum')
print(dictionary_mum.getSynonyms())
[{'mum': ['incommunicative', 'silent', 'uncommunicative']}]
其他可能的方法包括使用牛津词典API或查询thesaurus.com。这两种方法也存在一些问题。例如,牛津词典API需要一个API密钥和基于查询数量的付费订阅。而thesaurus.com缺少潜在的同义词,这在将单词分组时可能会有用。
https://www.thesaurus.com/browse/mother
synonyms: mom, parent, ancestor, creator, mommy, origin, predecessor, progenitor, source, child-bearer, forebearer, procreator
更新
为您的语料库中的每个潜在单词制作精确的同义词列表很困难,并且需要多管齐下。以下代码使用WordNet和PyDictionary创建了一个超集合的同义词。与所有其他答案一样,这种组合方法也会导致某些单词频率的过度计数。我一直在尝试通过合并最终同义词字典中的键和值对来减少这种过度计数。后者比我预期的要困难得多,可能需要我自己发布问题来解决。最终,我认为基于您的用例,您需要确定哪种方法最有效,并且可能需要结合几种方法。
感谢您发布这个问题,因为它让我看到了解决复杂问题的其他方法。
from string import punctuation
from nltk.corpus import stopwords
from nltk.corpus import wordnet
from PyDictionary import PyDictionary
input_text = """The hand that rocks the cradle also makes the house a home. It is the prayers of the mother
that keeps the family strong. When I think about my mum, I just cannot help but smile; The beauty of
her loving heart, the easy grace in her style. I will always need my mom, regardless of my age. She
has made me laugh, made me cry. Her love will never fade. If I could write a story, It would be the
greatest ever told. I would write about my daddy, For he had a heart of gold. For my father, my friend,
This to me you have always been. Through the good times and the bad, Your understanding I have had."""
def normalize_textual_information(text):
token = text.split()
table = str.maketrans('', '', punctuation)
token = [word.translate(table) for word in token]
token = [word.lower() for word in token if word.isalpha()]
stop_words = set(stopwords.words('english'))
stop_words.add('cannot')
stop_words.add('could')
stop_words.add('would')
token = [word for word in token if word not in stop_words]
token = [word for word in token if len(word) > 1]
return token
def generate_word_frequencies(words):
word_frequencies = []
for word in words:
word_frequencies.append(words.count(word))
word_frequencies = (dict(zip(words, word_frequencies)))
sorted_frequencies = {key: value for key, value in
sorted(word_frequencies.items(), key=lambda item: item[1])}
return sorted_frequencies
def get_synonyms_internet(word):
dictionary = PyDictionary(word)
synonym = dictionary.getSynonyms()
return synonym
words = normalize_textual_information(input_text)
all_synsets_1 = {}
for word in words:
for synonym in wordnet.synsets(word):
if word != synonym.name() and len(synonym.lemma_names()) > 1:
for item in synonym.lemmas():
if word != item.name():
all_synsets_1.setdefault(word, []).append(str(item.name()).lower())
all_synsets_2 = {}
for word in words:
word_synonyms = get_synonyms_internet(word)
for synonym in word_synonyms:
if word != synonym and synonym is not None:
all_synsets_2.update(synonym)
word_relationship = {**all_synsets_1, **all_synsets_2}
frequencies = generate_word_frequencies(words)
word_matches = []
word_set = {}
duplication_check = set()
for word, frequency in frequencies.items():
for keyword, synonym in word_relationship.items():
match = [x for x in synonym if word == x]
if word == keyword or match:
match = ' '.join(map(str, match))
if match not in word_set or match not in duplication_check or word not in duplication_check:
duplication_check.add(word)
duplication_check.add(match)
word_matches.append([keyword, match, frequency])
final_results = {}
synonym_matches = [(keyword[0], keyword[2]) for keyword in word_matches]
for item in synonym_matches:
if item[0] not in final_results.keys():
frequency_count = 0
frequency_count = frequency_count + item[1]
final_results[item[0]] = frequency_count
else:
frequency_count = frequency_count + item[1]
final_results[item[0]] = frequency_count